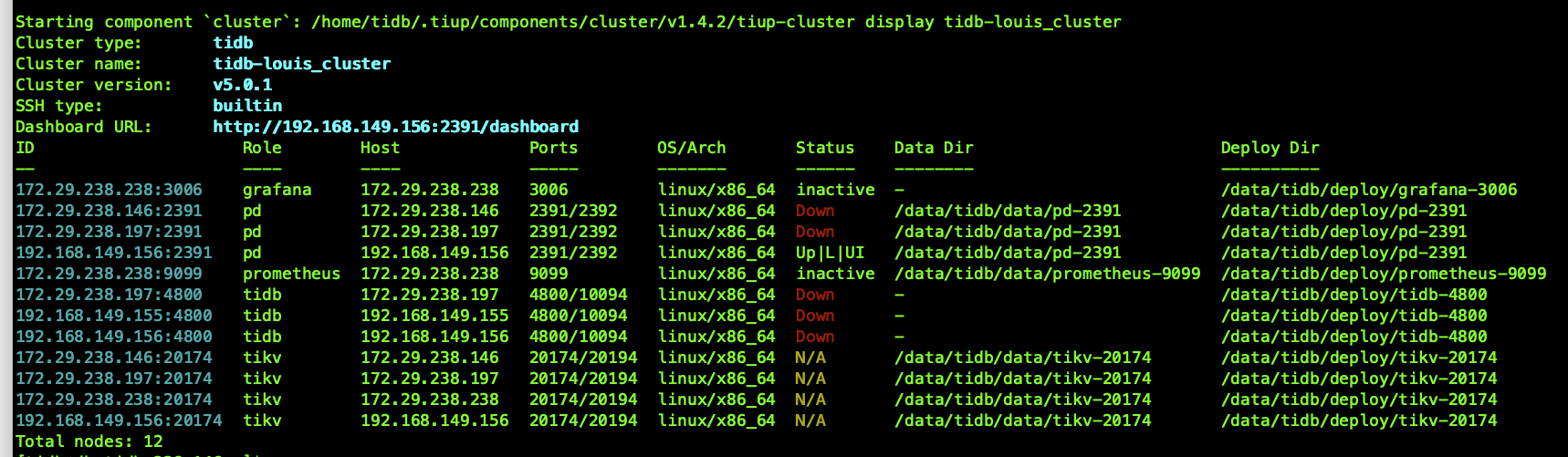
环境信息
- 单机模拟
tiup cluster display tidb-test
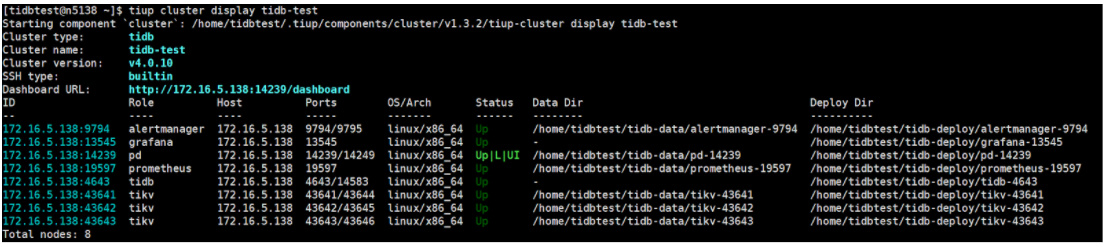
模拟 PD 损坏
- 删除 PD data 目录数据
cd /home/tidbtest/tidb-data/pd-14239
rm -rf *
- 查看集群状态已不可用
tiup cluster display tidb-test

- 等待一段时间再次查看 data 目录自动恢复,提示变为 label 配置不合理,这里感觉有问题,先忽略,继续。

恢复步骤
tiup install pd-recover
download https://tiup-mirrors.pingcap.com/pd-recover-v5.0.0-rc-linux-amd64.tar.gz 14.10 MiB / 14.10 MiB 100.00% 53.55 MiB p/s
2.1 从 PD 日志获取 Cluster ID(推荐)
cd /home/tidbtest/tidb-deploy/pd-14239/log
cat pd.log grep “init cluster id”
[2021/02/19 14:25:16.063 +08:00] [INFO] [server.go:343] [“init cluster id”] [cluster-id=6930857086136645412]
[2021/02/22 10:33:32.958 +08:00] [INFO] [server.go:343] [“init cluster id”] [cluster-id=6931910623486032202]
[2021/02/22 10:50:49.445 +08:00] [INFO] [server.go:343] [“init cluster id”] [cluster-id=6931915078138639983]
2.2 从 TiDB 日志获取 Cluster ID(无法找到最初的 id)
cd /home/tidbtest/tidb-deploy/tidb-4643/log
cat tidb.log grep “init cluster id”
[2021/02/19 14:25:17.664 +08:00] [INFO] [base_client.go:102] [“[pd] init cluster id”] [cluster-id=6930857086136645412]
…
[2021/02/22 10:47:55.084 +08:00] [INFO] [base_client.go:102] [“[pd] init cluster id”] [cluster-id=6931910623486032202]
…
[2021/02/22 10:50:50.447 +08:00] [INFO] [base_client.go:102] [“[pd] init cluster id”] [cluster-id=6931915078138639983]
2.3 从 TiKV 日志获取 Cluster ID(没有最初的 cluster id)
cd /home/tidbtest/tidb-deploy/tikv-43641/log
cat tikv.log grep “connect to PD cluster”
[2021/02/22 10:50:07.052 +08:00] [INFO] [server.rs:242] [“connect to PD cluster”] [cluster_id=6931910623486032202]
[2021/02/22 10:50:22.561 +08:00] [INFO] [server.rs:242] [“connect to PD cluster”] [cluster_id=6931910623486032202]
[2021/02/22 10:50:49.758 +08:00] [INFO] [server.rs:242] [“connect to PD cluster”] [cluster_id=6931915078138639983]
[2021/02/22 10:51:05.301 +08:00] [INFO] [server.rs:242] [“connect to PD cluster”] [cluster_id=6931915078138639983]
其他两个 TiKV 节点日志类似
2.4 查看 PD 日志
确认 cluster-id=6930857086136645412 是 rm -rf 时的 id
其他 cluster id 是 rm -rf 后重新生成的 id
[2021/02/22 10:50:31.470 +08:00] [FATAL] [server.go:822] [“failed to purge snap db file”] [error=“open /home/tidbtest/tidb-data/pd-14239/member/snap: no such file or directory”] [stack=“go.etcd.io/etcd/etcdserver.(*EtcdServer).purgeFile
\t/home/jenkins/agent/workspace/build_pd_multi_branch_v4.0.10/go/pkg/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:822
go.etcd.io/etcd/etcdserver.(*EtcdServer).goAttach.func1
\t/home/jenkins/agent/workspace/build_pd_multi_branch_v4.0.10/go/pkg/mod/go.etcd.io/etcd@v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738/etcdserver/server.go:2632”]
[2021/02/22 10:50:46.913 +08:00] [INFO] [util.go:42] [“Welcome to Placement Driver (PD)”]
[2021/02/22 10:50:46.913 +08:00] [INFO] [util.go:43] [PD] [release-version=v4.0.10]
3.1 从监控中获取已分配 ID(推荐)
3.2 从 PD 日志获取已分配 ID (查看所有 PD 日志,查找最大值)
cd /home/tidbtest/tidb-deploy/pd-14239/log
cat pd*.log grep “idAllocator allocates a new id” awk -F’=’ ‘{print $2}’ awk -F’]’ ‘{print $1}’ sort -r head -n 1
2000
4.1 删除旧的数据目录
cd /home/tidbtest/tidb-data/
rm -rf pd-14239
5.1 重启 PD 集群
tiup cluster start tidb-test -N 172.16.5.138:14239
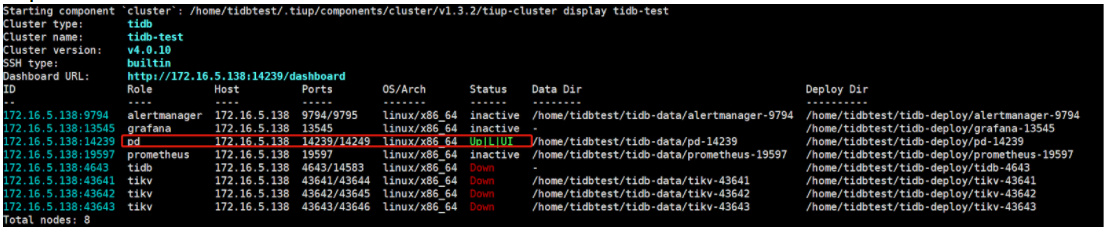
5.2 使用 pd-recover 恢复(使用出问题前的 cluster id,模拟选错 cluster id,注意 alloc-id 要比当前最大值大)
tiup pd-recover -endpoints http://172.16.5.138:14239 -cluster-id 6930857086136645412 -alloc-id 3000
Starting component pd-recover: /home/tidbtest/.tiup/components/pd-recover/v5.0.0-rc/pd-recover -endpoints http://172.16.5.138:14239 -cluster-id 6930857086136645412 -alloc-id 3000
recover success! please restart the PD cluster
重启集群成功
tiup cluster restart tidb-test