为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.2
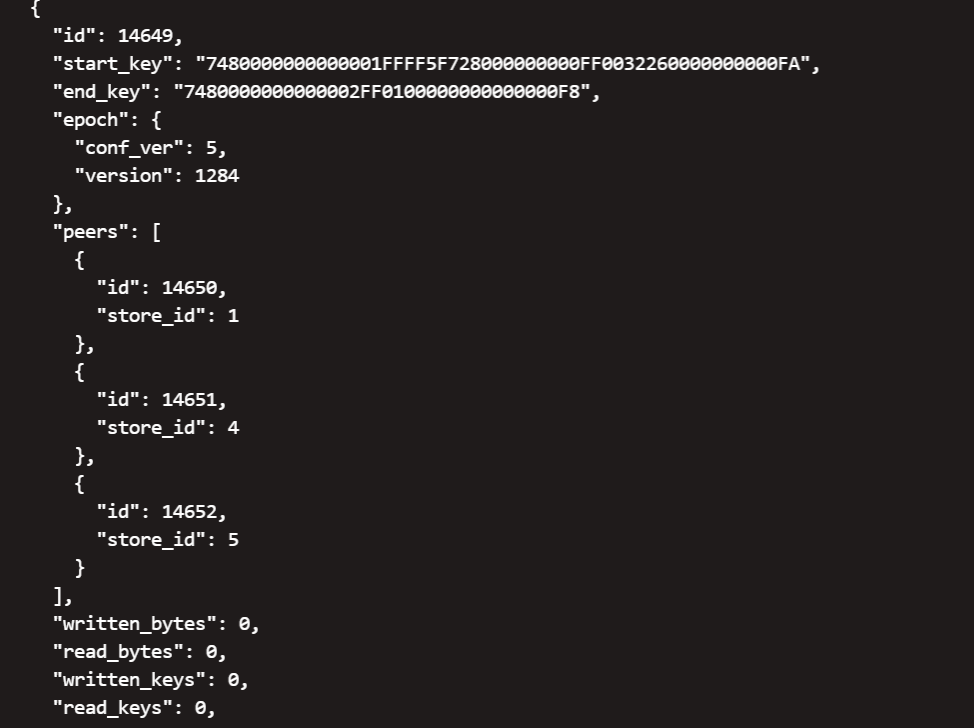
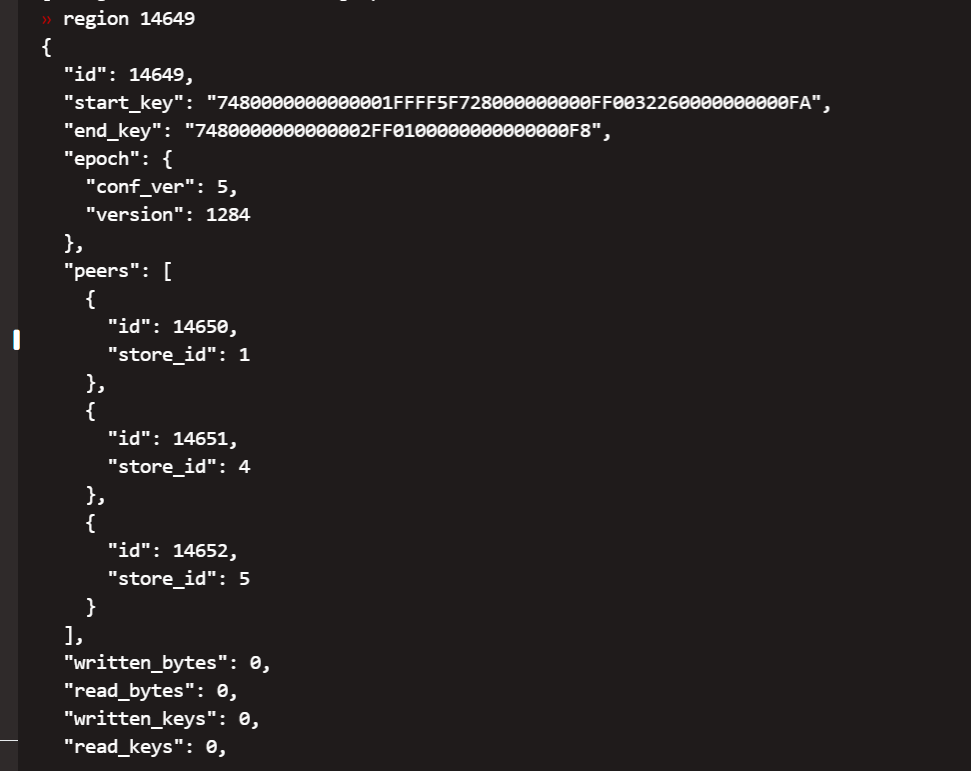
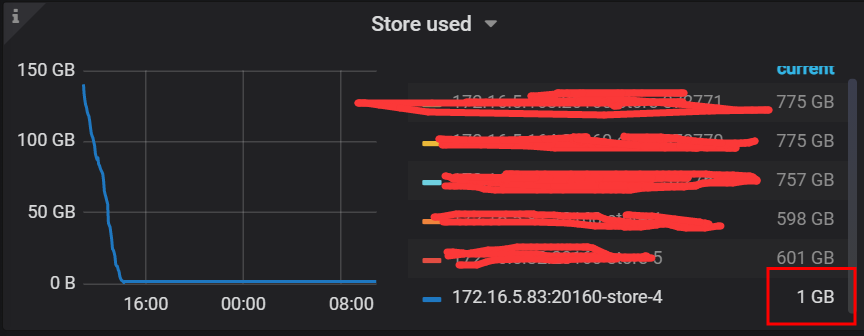
【问题描述】下线tikv节点显示一直Pending Offline 然后有1G的数据一直没有从下线节点迁移走
tikv的报错:
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.2
【问题描述】下线tikv节点显示一直Pending Offline 然后有1G的数据一直没有从下线节点迁移走
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
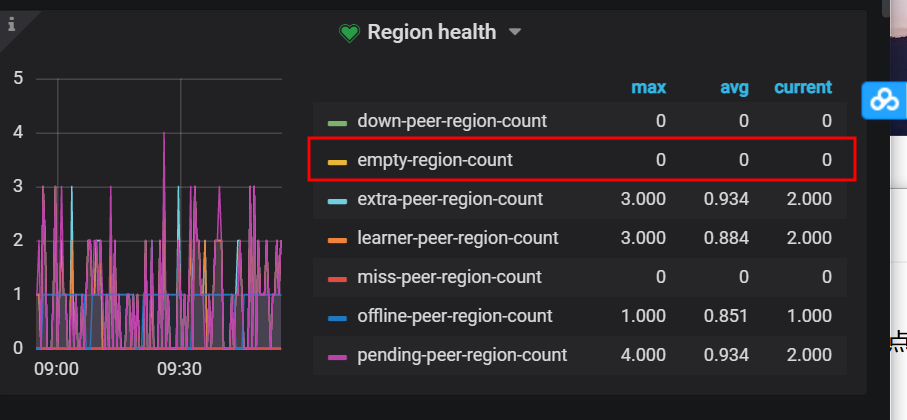
看下 PD 监控面板中 region health 的监控,截个图看下有没有异常的 region 信息。
region_info (22.1 KB) pd.log (8.2 MB) tikv.log (6.9 MB)
看了下下线的这个 store 上的 region 都是空 region。
可以参考下这个 FAQ 将集群内的 empty-region 都 merge 清理下,看能不能下线成功
empty-region的话可否直接force下线tikv节点。
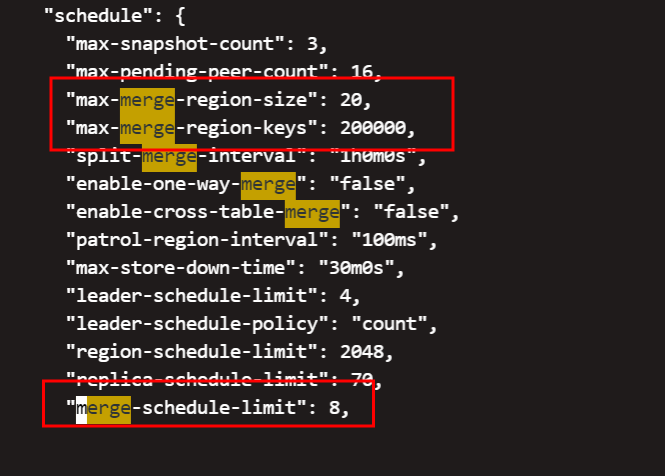 这个默认是打开的了
这个默认是打开的了
建议是按照流程下线节点,将 region 迁移完成后再下线。开启了 region merge ,还是有 empty-region-count 的问题,可以参考上面的 FAQ。
这个集群之前是不是有做过 unsafe-recover 之类的恢复操作?
在 store 4 节点上执行
./tikv-ctl --host ${store4_ip}:${store4_tikv_port} raft region -r 15141
./tikv-ctl --host ${store4_ip}:${store4_tikv_port} raft region -r 15149
./tikv-ctl --host ${store4_ip}:${store4_tikv_port} raft region -r 52021
拿一下结果
没有哦
region id: 15141
region state key: \001\003\000\000\000\000\000\000;%\001
region state: Some(region { id: 15141 start_key: 7480000000000001FFB35F698000000000FF0000010131323132FF33643530FF2D3066FF66362D3430FF3965FF2D383965612DFF37FF63303136666333FFFF6432326537326333FFFF323137662D6231FF64FF362D34613039FF2D62FF3235612D36FF326638FF35346233FF31626662FF000000FF0000000000F70000FD end_key: 7480000000000001FFB35F698000000000FF0000010132316531FF31373536FF2D6333FF30312D3463FF6137FF2D623866322DFF35FF63633238633730FFFF3432393836653064FFFF396136612D3663FF32FF302D34623064FF2D39FF3665382D38FF353330FF38353030FF32313934FF000000FF0000000000F70000FD region_epoch { conf_ver: 5 version: 1244 } peers { id: 15142 store_id: 1 } peers { id: 15143 store_id: 4 } peers { id: 15144 store_id: 5 } })
raft state key: \001\002\000\000\000\000\000\000;%\002
raft state: Some(hard_state { term: 30 vote: 15143 commit: 3076 } last_index: 3076)
apply state key: \001\002\000\000\000\000\000\000;%\003
apply state: Some(applied_index: 3076 last_commit_index: 3075 commit_index: 3076 commit_term: 30 truncated_state { index: 3051 term: 7 })
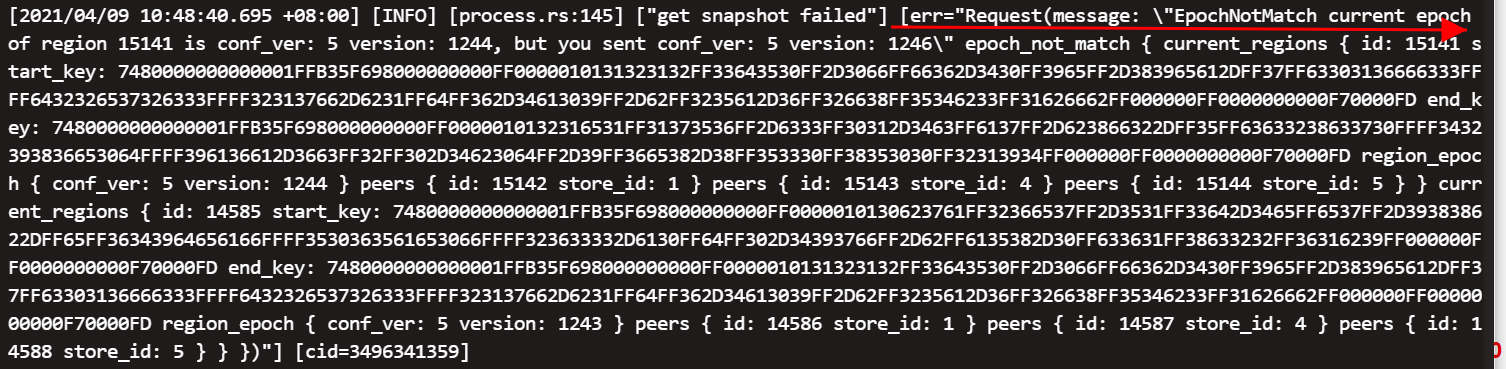
是什么原因呢?
[get snapshot failed][err=Request(message:“EpochNotMatch current epoch of region 15141 is conf_ver: 5 version: 1244, but you sent conf_ver: 5 version: 1246”)]
这个错误是因为 pd 中记录的 region epoch 版本信息比 tikv 上的 region epoch 版本高,pd 中记录的是 1246 ,但是 tikv 上还只有 1244 。
通过 pd-ctl 看 region 15141 的信息和通过 tikv-ctl 看 region 15141 的信息也确认是这样的。
出现这个错误一般有集几种原因:
修复方式:
可以尝试一下通过 pd-ctl 执行 config set use-region-storage false 并且切换一下 pd leader ,让 pd 中的 region 信息清理掉,让 tikv 上的 region 重新上报心跳信息来完成 pd 与 tikv 之前的 region 信息一致。
执行这个操作,会影响写入嘛