【问题澄清】
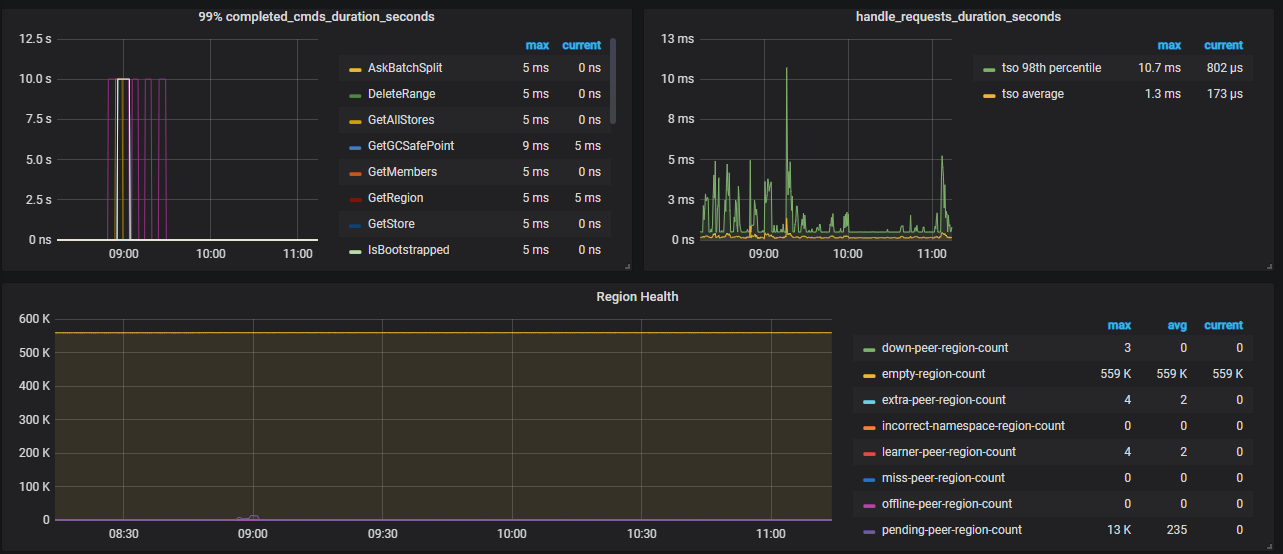
检查监控,发现 [overview - pd - region health[empty-region-count]] 空 region 达到了 559K,但是已经开启了 region merge,空 region 也没有明显的下降,这是为何?
【知识点引入】
参数解释:
- pd 参数解释:
< v3.1 使用
namespace-classifier 默认是 table,默认情况下,region merge 不会进行表表合并,所以在集群中有大量的 drop/truncate table, create table, drop database 的时候需要修改该参数(namespace-classifier = " default")
>= v3.1 使用
enable-cross-table-merge 默认 false,如果为 true,则表示可以合并不同表中的两个区域,仅当 key type 为 “table” 时此选项才有效。
tikv 参数:
-
split-region-on-table,默认值为 true,开启按 table 分裂 Region的开关,为了配合合并空 region 需要将其设置为 false。
【操作】
- tidb-ansible 部署,在中控节点修改 pd.yml 然后执行 ansible-playbook rolling_update.yml --tags=pd,tikv 来使修改生效。
- tiup 部署,使用
tiup cluster edit-config cluster-name在[service_configs] pd/tikv修改参数,通过tiup cluster reload -R pd,tikv将参数生效,(PS:reload 不是 restart,当前 reload 有些参数可能不生效,未来版本将 reload 默认调用 pd-ctl 去执行)。当前为了保证修改参数的准确性,这边推荐tiup ctl或者pd-ctl修改 pd 参数。
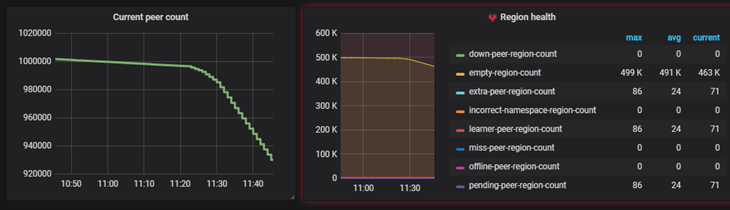
【参数效果】
peer 和 empty region count 在逐渐减少
【继续优化】
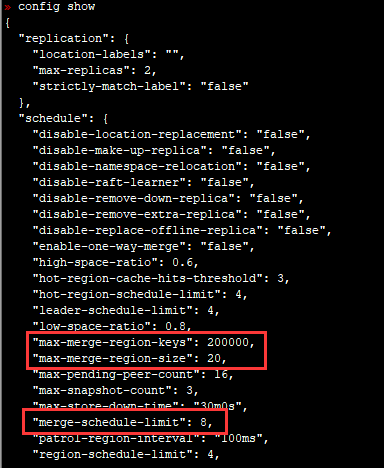
- 上图中,影响 region 合并的参数为 merge-scgedule-limit,当前设置为 8 ,可以在集群空闲时将此参数调大加快 merge 速度。
- 可以调整 replicaChecker 检查 Region 健康状态的运行频率,patrol-region-interval <= 50ms(最小 10ms),合并完成建议恢复到默认值 100ms。
- 3.0 版本之后值得关注其他 scheduler 线程数,避免线程之间的争抢
- 对于有 addPeer 或者 addLeaner 相关调度,可以适当调整 store limit 参数,参数中 的实际意义均表示每分钟与 region 相关调度的上限个数。
可使用 pd-ctl -u ip:port stores show limit 查看修改结果
【知识扩展】
如果开启 region merge,通过 pd-ctl 开启此功能,v3.0 版本已经默认开启。
>> pd-ctl config set max-merge-region-size 20
>> pd-ctl config set max-merge-region-keys 200000
>> pd-ctl config set merge-schedule-limit 8
【参考案例】
- https://asktug.com/t/topic/34272
- https://asktug.com/t/topic/34283/15?u=户口舟亢
- https://asktug.com/t/topic/34744/7