【 TiDB 使用环境`】生产环境
【 TiDB 版本】 5.3.1
【附件】
pd监控模板tso 过高,如何优化
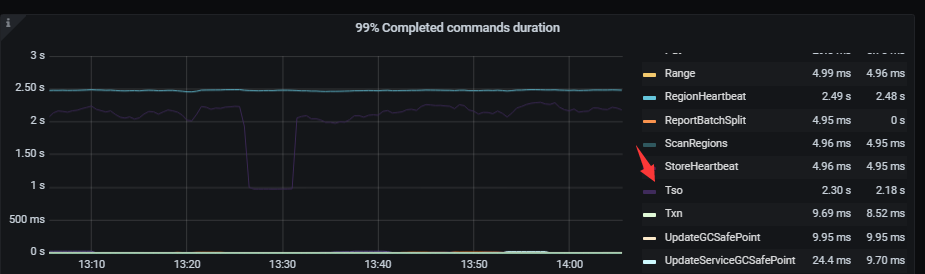
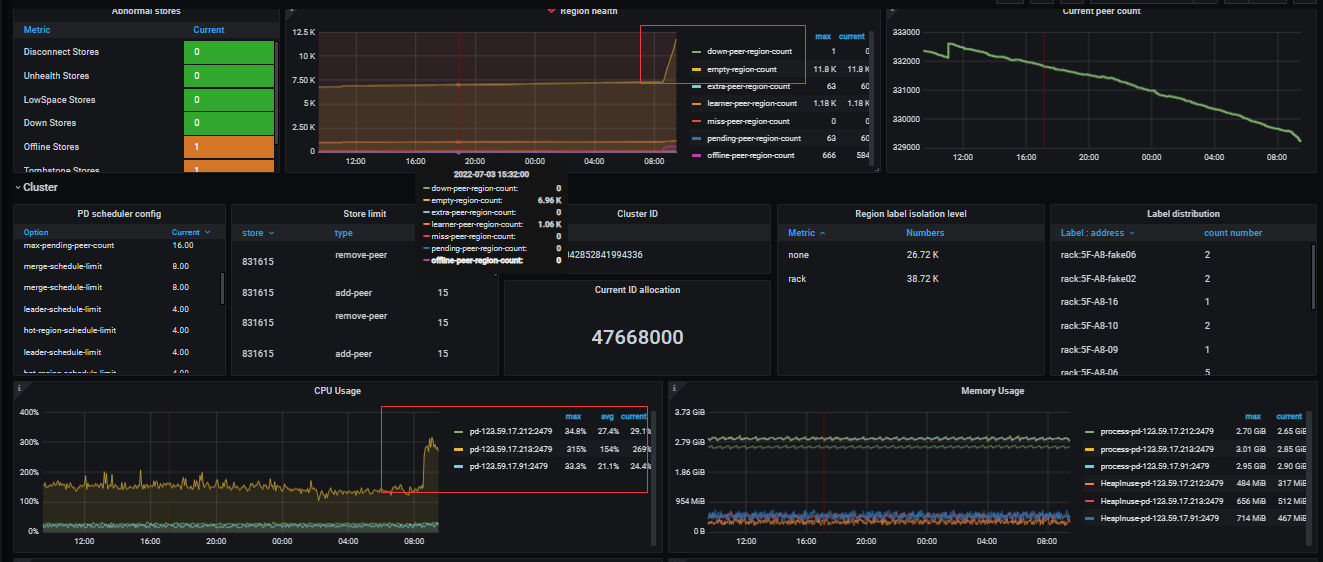
pd监控
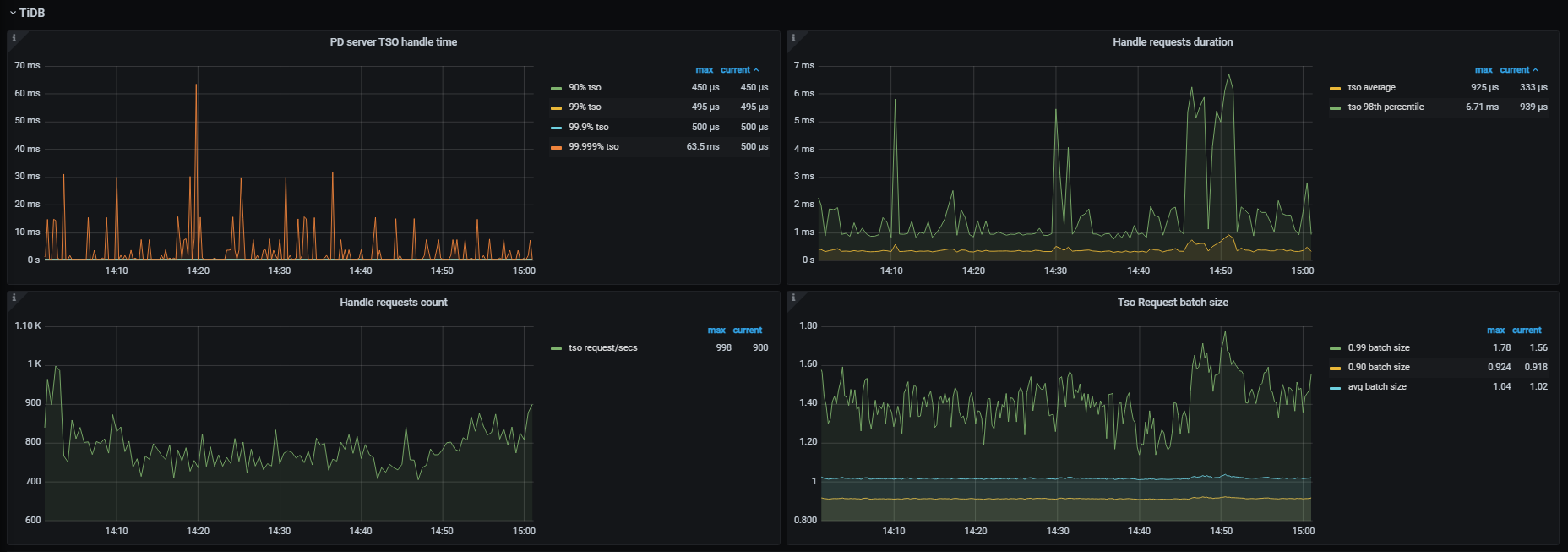
tidb 监控
需要分别检查TiDB侧和PD侧,看是谁压力太大引起的,另外还需要看一下TiDB到PD之间的网络延迟情况
就是因为TiDB侧和PD侧 监控看不出什么,pd到tidb 走的内网,才发帖的。 唯一的猜测是 tidb 和pd 有部分节点不是万兆, 但是带宽也没有打满或者丢包
pd监控 etcd相关
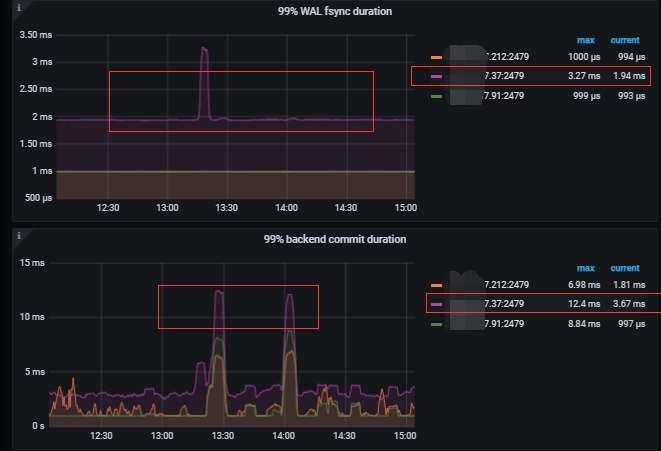
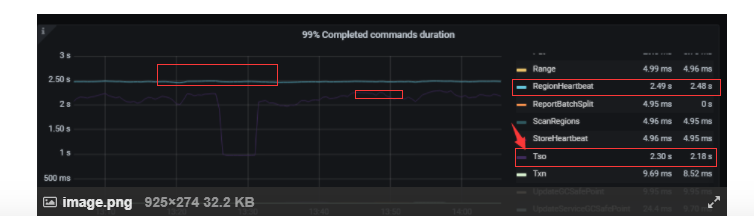
regionheartbeat 跟 TSO 是谁影响谁 ? 两个的duration都非常高 。
pd里这个统计跟tidb是不是没关系? 这里的TSO 怎么跟 tidb里的 pd tso 差别那么大?
凌晨业务低谷这个duration 都特别高 。

换掉了 特别慢的 37节点

PD里面的TSO RegionHeartbeat 依然高高在上
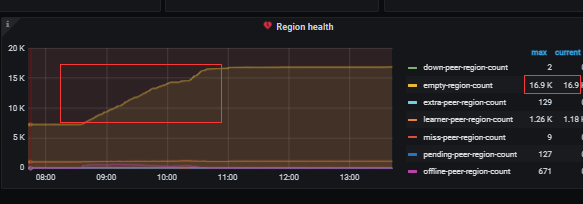
tso处理时间不高,但是延迟较高,可能的原因是pd的cpu过高,空region或者region数量过高,region频繁选举都可能是原因,空region的话,看看pd调度上region合并是不是没有调度,或者调度过慢?
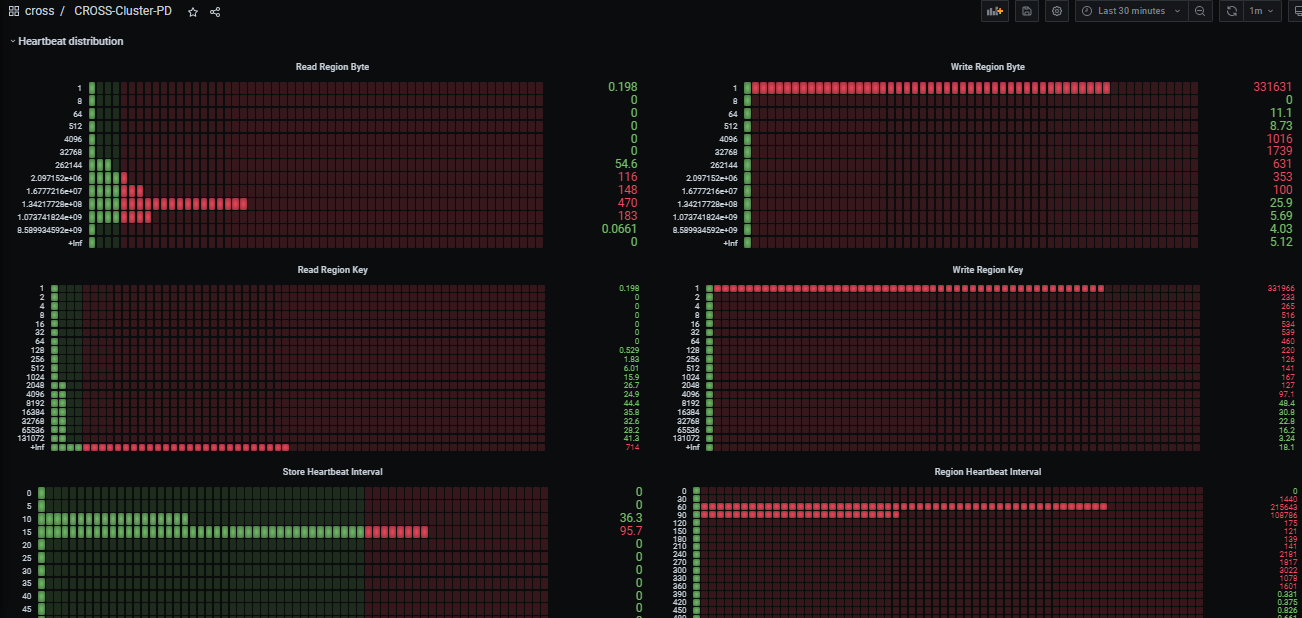
empty-regions 前几天13K 下到 7K左右 ,今天 下线一个tikv 又从7K涨到16.8K 了。
“schedule”: {
“enable-cross-table-merge”: “true”,
“enable-debug-metrics”: “false”,
“enable-joint-consensus”: “true”,
“enable-location-replacement”: “true”,
“enable-make-up-replica”: “true”,
“enable-one-way-merge”: “false”,
“enable-remove-down-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“high-space-ratio”: 0.6,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“hot-regions-reserved-days”: 0,
“hot-regions-write-interval”: “10m0s”,
“leader-schedule-limit”: 4,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.85,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 16,
“max-snapshot-count”: 3,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 2048,
“region-score-formula-version”: “”,
“replica-schedule-limit”: 64,
“scheduler-max-waiting-operator”: 3,
“split-merge-interval”: “1h0m0s”,
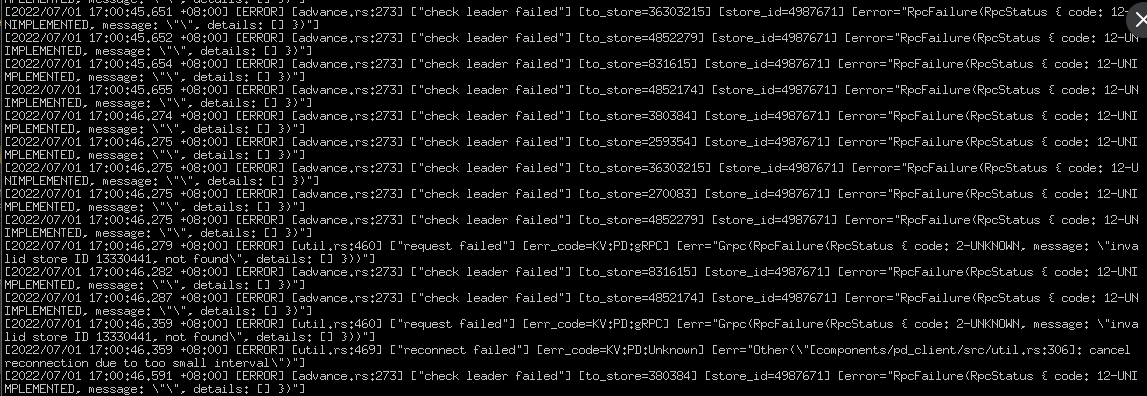
tikv 好多这种错误有关系吗?
[2022/07/04 13:44:14.279 +08:00] [ERROR] [advance.rs:273] [“check leader failed”] [to_store=36303215] [store_id=507533] [error=“RpcFailure(RpcStatus { code: 12-UNIMPLEMENTED, message: "", details: [] })”]
[2022/07/04 13:44:14.283 +08:00] [ERROR] [advance.rs:273] [“check leader failed”] [to_store=270083] [store_id=507533] [error=“RpcFailure(RpcStatus { code: 12-UNIMPLEMENTED, message: "", details: [] })”]
这两篇文章可以看下
看过了,总结就是网络问题
我把pd和tidb 都迁移到万兆的机器,现在监控指标下来了。
那就是网络导致的
网络没问题,应该是大量空region导致的
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。