在查找数据库中某一批数据时,总是查询40秒后报 【9005 - Region is unavailable】 的错误,查数据库中的其他数据正常。一共3个tikv,在其中一个tikv中有不少epoch_not_match的警告。
[2021/04/02 05:10:09.063 +00:00] [WARN] [endpoint.rs:527] [error-response] [err="Region error (will back off and retry) message: \"EpochNotMatch current epoch of region 4800001 is conf_ver: 5 version: 791, but you sent conf_ver: 11 version: 801\" epoch_not_match { current_regions { id: 4800001 start_key: 7480000000000006FF9C5F698000000000FF0000040419A8BC54FF7300000003B5C9ACFF1F2E801000000000FC end_key: 7480000000000006FF9C5F698000000000FF0000040419A922D2FF5B00000003B60551FF2EE6006000000000FC region_epoch { conf_ver: 5 version: 791 } peers { id: 4800002 store_id: 1 } peers { id: 4800003 store_id: 7001 } peers { id: 4800004 store_id: 7002 } } current_regions { id: 4602013 start_key: 7480000000000006FF9C5F698000000000FF0000040419A82AE1FF0400000003B596A4FFF70B806000000000FC end_key: 7480000000000006FF9C5F698000000000FF0000040419A8BC54FF7300000003B5C9ACFF1F2E801000000000FC region_epoch { conf_ver: 5 version: 790 } peers { id: 4602014 store_id: 1 } peers { id: 4602015 store_id: 7001 } peers { id: 4602016 store_id: 7002 } } }"]
怀疑是region 4800001出问题了,请问这个有没有办法恢复的?
如果无法恢复的话,有没有办法清掉那些有问题的数据,不然每次查都会等待40秒,然后报错。
这道题我不会
2021 年4 月 6 日 02:30
2
EpochNotMatch:该错误是说 Region 的版本过期。
检查机制实现是,每个 Region 信息都有 Epoch 信息,包括两个字段:
conf_ver 代表配置项版本,新增或删除 peer 时,该属性会自增
version 代表 region 的版本,当 region 被合并或拆分时,该值会自增
TiDB 的在请求 TiKV 时会在请求中附上 Epoch,KV 会校验 Epoch 如果不匹配则返回 EpochNotMatch 错误, 并在错误中附带自己知道的最新 Region 信息。
如果使用了 TiDB 那么 TiDB 在收到报错后会进行 backoff 重试,不用特别担心,可以参考下:https://docs.pingcap.com/zh/tidb/stable/tidb-troubleshooting-map#11-客户端报-region-is-unavailable-错误
你好,根据上面的链接,我的问题可能属于下面这种情况:epoch not match 理由打回,见案例 case-958 (TiKV 内部需要优化该机制)。Region is Unavailable 的错误。
这道题我不会
2021 年4 月 7 日 03:44
4
请问下你这边出现 epoch not match 时,前端和后端的报错信息和 case-958 都是吻合的吗?如果是的话需要排查下 apply 慢的原因,可以参考下:
在 TiDB Server 端做完 SQL 的解析,以及冲突检测后,会将相应的请求通过 gRPC 发生给 TiKV 进一步进行事务处理两阶段提交,Raft Log 的发送以及 Apply,以及 RocksDB 的数据存储。
当我们在谈论两阶段提交,我们在谈论什么?
提交的是什么?
写入的算子 Insert / Update / Delete 在执行过程中对于写入的数据编码为 Key-Val…
如何看以前的日志的,由于tikv的pod删了重新生成过,对应的log也看不到了,但可以排除内存不足、没有leader、tikv busy的原因,因为目前运行良好,新生成的数据可用,也没有apply慢的情况,就是查固定某一批旧的数据的时候会报Region is Unavailable。
这道题我不会
2021 年4 月 7 日 07:38
6
有两个疑问地方:Region is Unavailable 时,日志里都是提示 EpochNotMatch 吗?还是说有其他报错信息。
1.不是每次都报,那可能不是epoch_not_match的问题?
2.是在查固定某个表的某些数据的时候报错,表上其他数据正常。
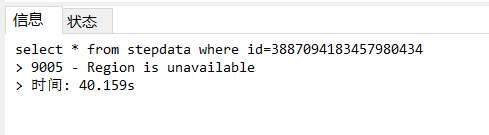
通过show table t regions查看,综合自己对报错数据的大致排查,怀疑表的id在3887094183457980434与3890916794226966566之间的数据有问题。
可以确定是id 在 3887094183457980434 与 3890916794226966566 之间的数据有问题了,我查id<3887094183457980434 的数据的数量和查id> 3890916794226966566 的数据的数量都没问题,但查id在 3887094183457980434 与 3890916794226966566 之间的数据的数量的时候报错了。
这道题我不会
2021 年4 月 8 日 02:42
9
查id在 3887094183457980434 与 3890916794226966566 之间的数据报错内容是 epoch_not_match 还是其他报错内容?
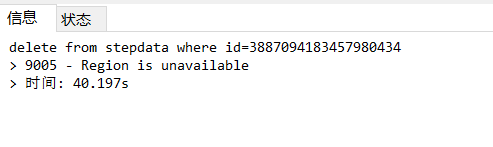
id在 3887094183457980434 与 3890916794226966566 之间的数据用sql语句查的时候报 9005 - Region is unavailable 。epoch_not_match是在tikv的日志里看到的,可能和Region is unavailable无关。Region is unavailable的问题,那批有问题的数据修复也修复不了,删也删不掉。sql语句去查询、修改、删除数据的时候,只要有牵扯到那批数据的,都会报 9005 - Region is unavailable 的错误。
yilong
2021 年4 月 8 日 07:53
11
你好,我查了所有3个tikv的 bad region, 都显示 all regions are healthy。
yilong
2021 年4 月 9 日 07:29
13
是tiup安装的吗? tiup ctl pd 命令查看下 region 看看 PD 里记录的信息
不是tiup安装,是部署在Kubernetes上的。region.txt (613.9 KB)
» region check miss-peer
» region check down-peer
» region check pending-peer
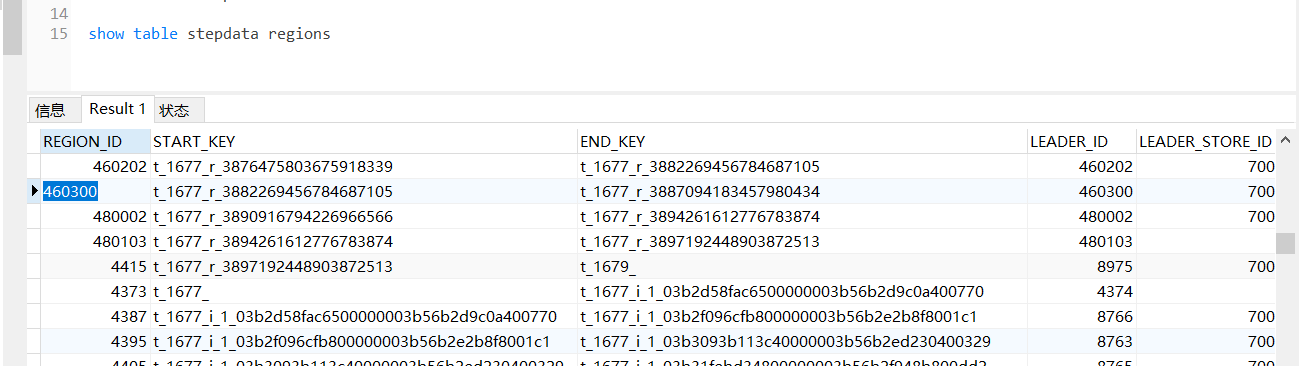
region460300是null,但show table region能显示那个region。
» region sibling 460300
» region sibling 480002
» region 460300
感觉show table region时缩略了regionid的最后一位吧,问题region看上去可能是4800001。
» region sibling 4800001
» region 4800001
版本是v4.0.7。tableregion.xls (53 KB)