在 TiDB Server 端做完 SQL 的解析,以及冲突检测后,会将相应的请求通过 gRPC 发生给 TiKV 进一步进行事务处理两阶段提交,Raft Log 的发送以及 Apply,以及 RocksDB 的数据存储。
当我们在谈论两阶段提交,我们在谈论什么?
- 提交的是什么?
写入的算子 Insert / Update / Delete 在执行过程中对于写入的数据编码为 Key-Value 并先写入事务的 In-Memory Buffer,写入的数据包含两类:
- 普通数据插入
- 索引数据插入
普通数据和索引数据使用不同的编码方式转换 Key 和 Value,如何将数据编码成对应的 Key-Value 的细节与监控以及原理无关,这一部分可以暂时忽略,统一理解为 Key-Value 即可。
两阶段提交的本质就是将 In-Memory Buffer 中的 Key-Value 通过 tikvclient 写入到 TiKV 中。
- 如何提交?
两阶段提交顾名思义就是将事务的提交分成两个阶段:
Prewrite
Commit
在每个 Transaction 开启时会获取一个 TSO 作为 start_ts,在 Prewrite 成功后 Commit 前获取 TSO 作为 commit_ts,如下图:
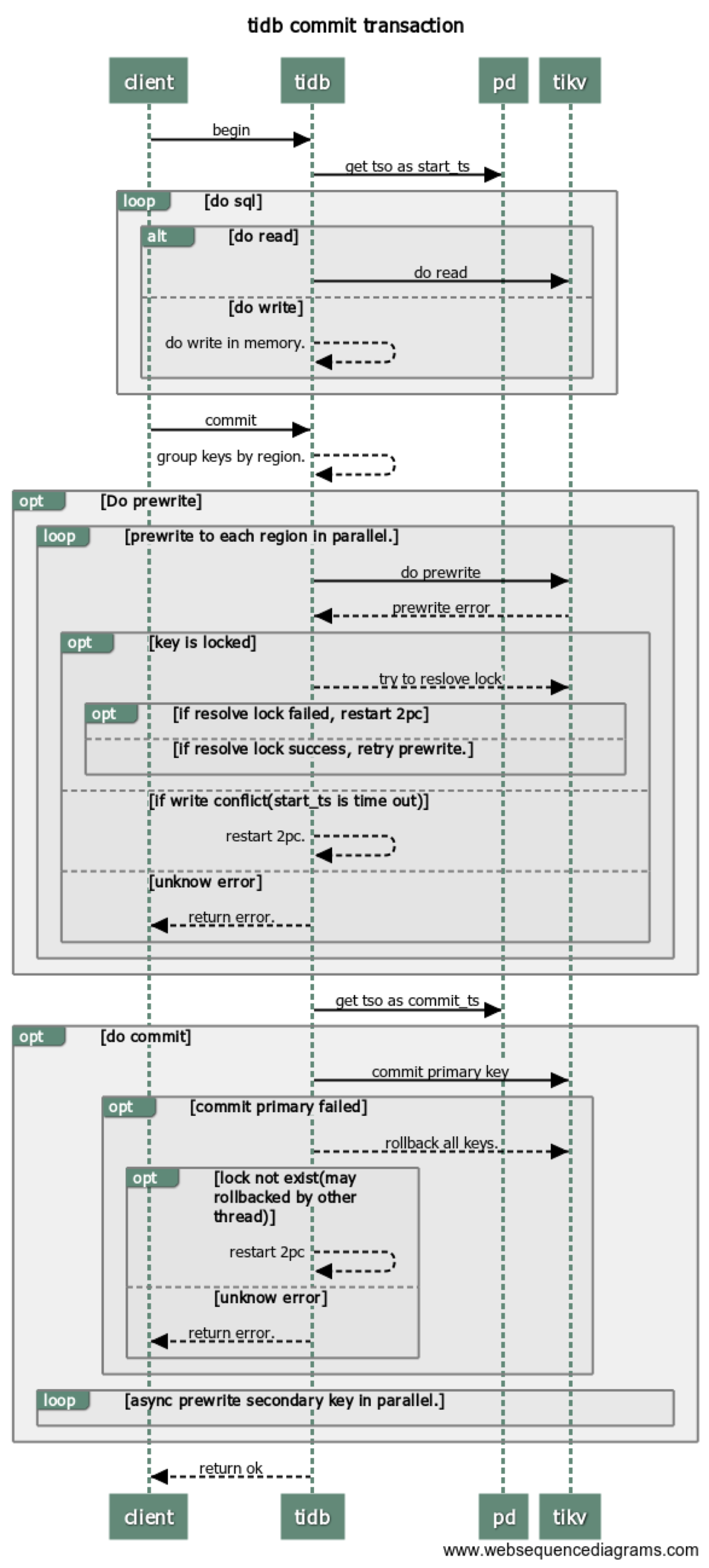
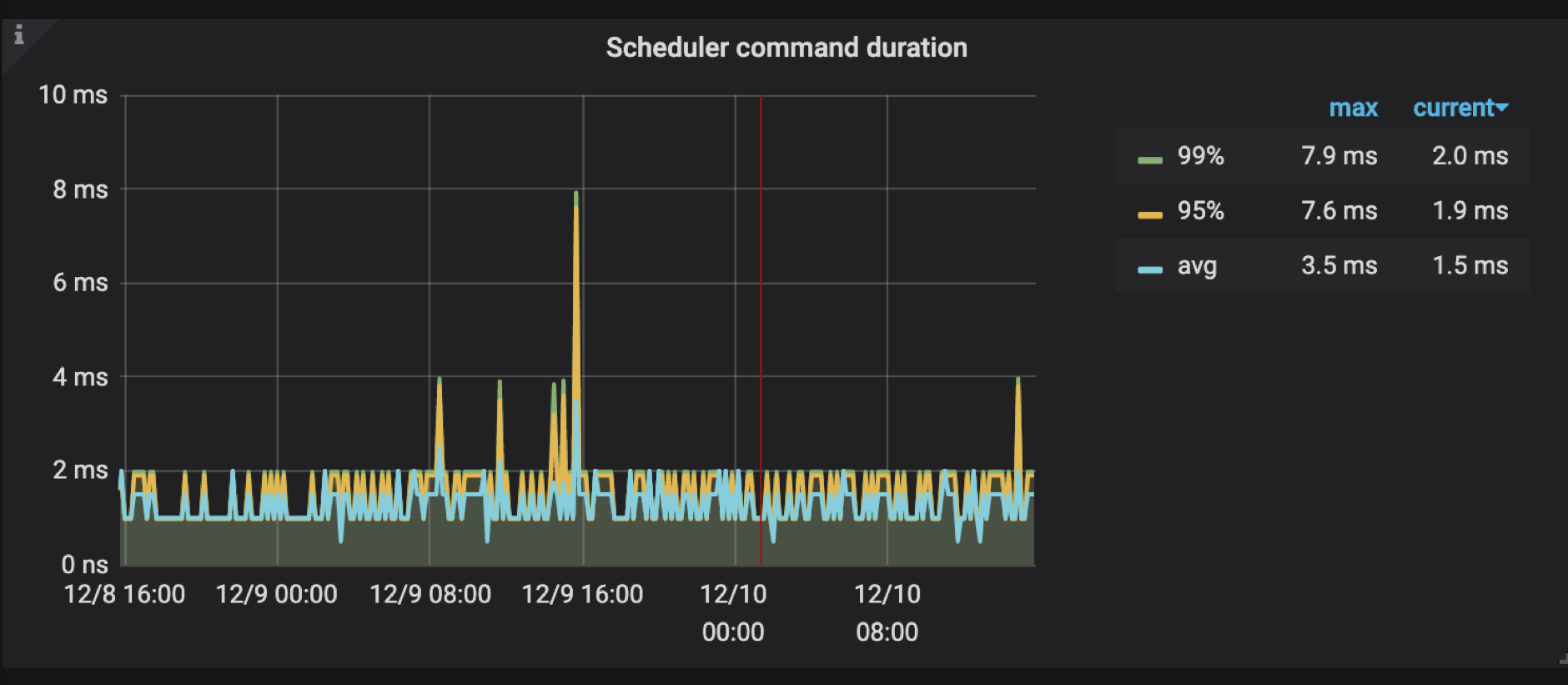
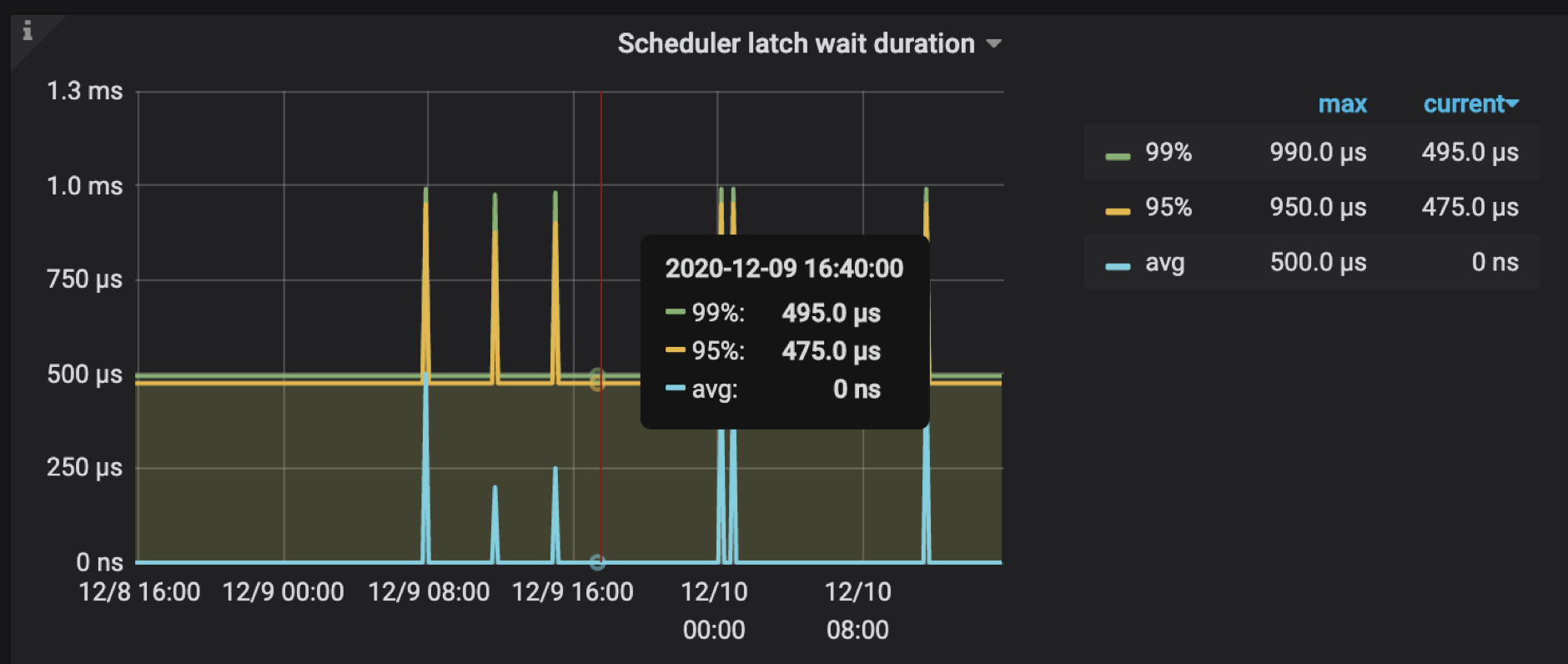
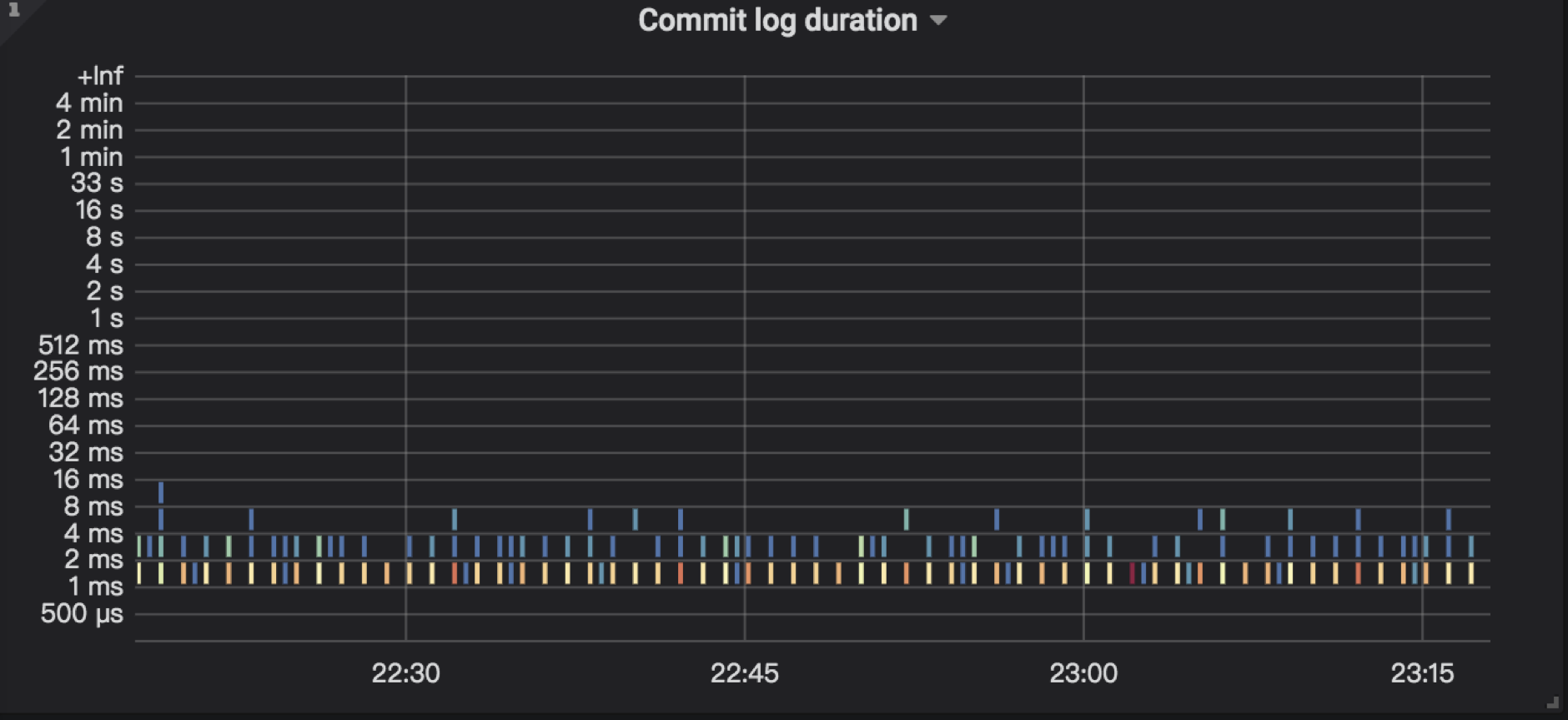
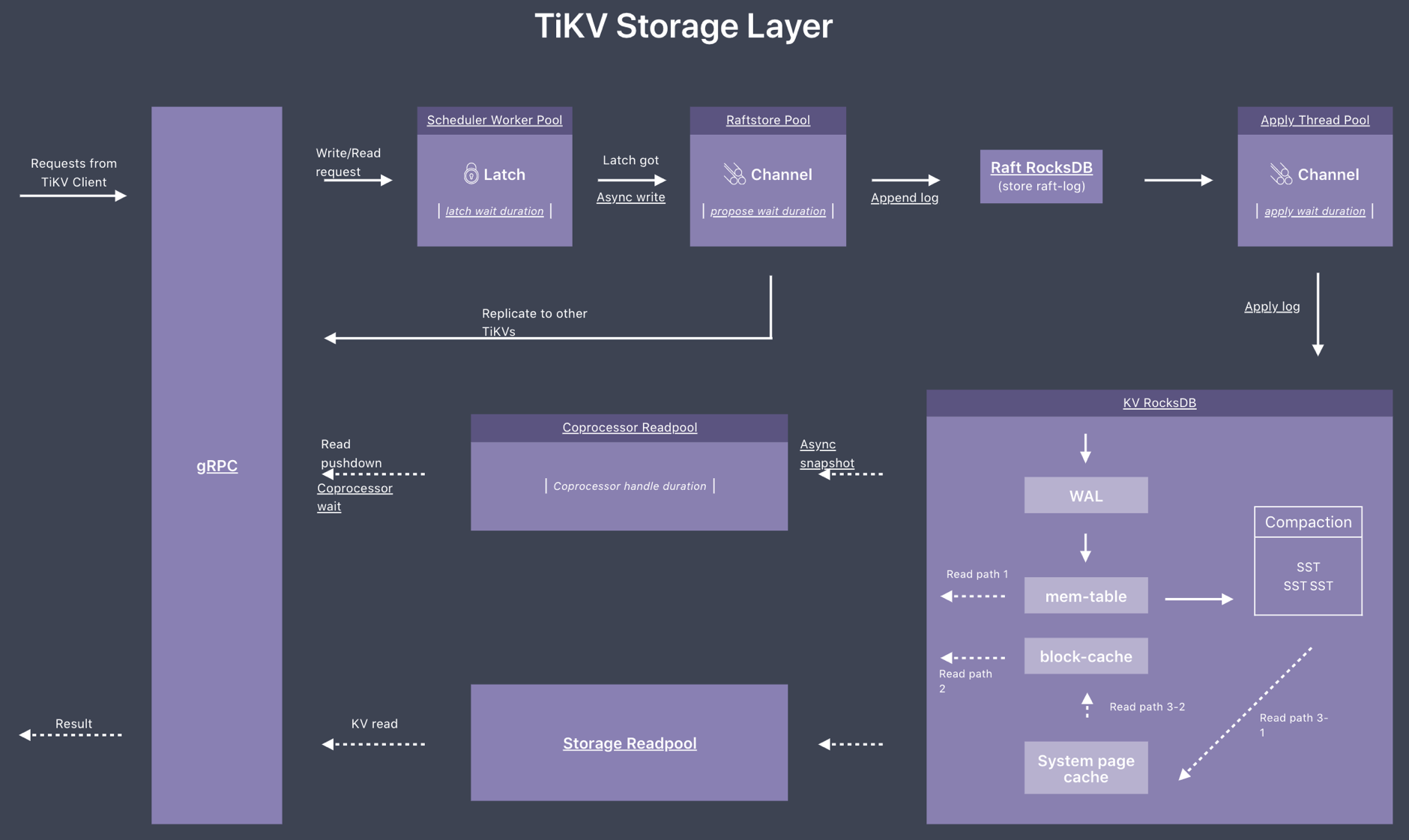
并且不论是两阶段提交的 prewrite 还是 commit 阶段,都会走相同的 TiKV 写入数据流程:通过 Raft 来确保数据的一致性,以及 RocksDB 来实现数据的持久化。下图为 TiKV 写流程示意图,分别包括了 Scheduler 、Raftstore 以及 RocksDB 等相关内容:
-
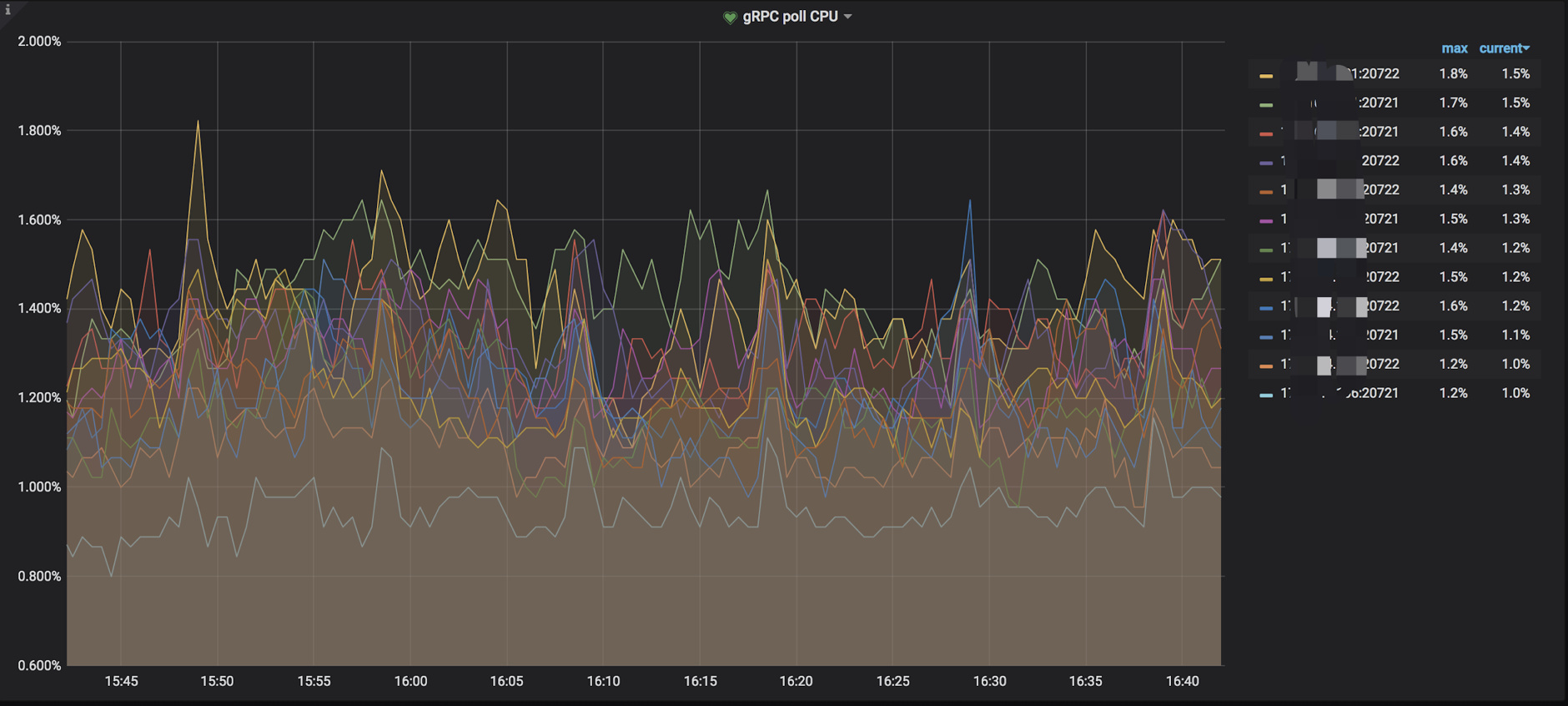
gRPC
-
KV 的请求类型
➢ Raw KV
Raw KV 操作包括 raw put、raw get、raw delete、raw batch get、raw batch put、raw batch delete、raw scan 等普通 KV 操作。
如果是写入操作,没有事务处理部分,会直接调用 async_write 接口发送给底层的 KV 存储引擎。
➢ Txn KV
Txn KV 操作是为了实现事务机制而设计的一系列操作,如 prewrite 和 commit 分别对应于 2PC 中的 prepare 和 commit 阶段的操作。以 prewrite 为例:
Scheduler
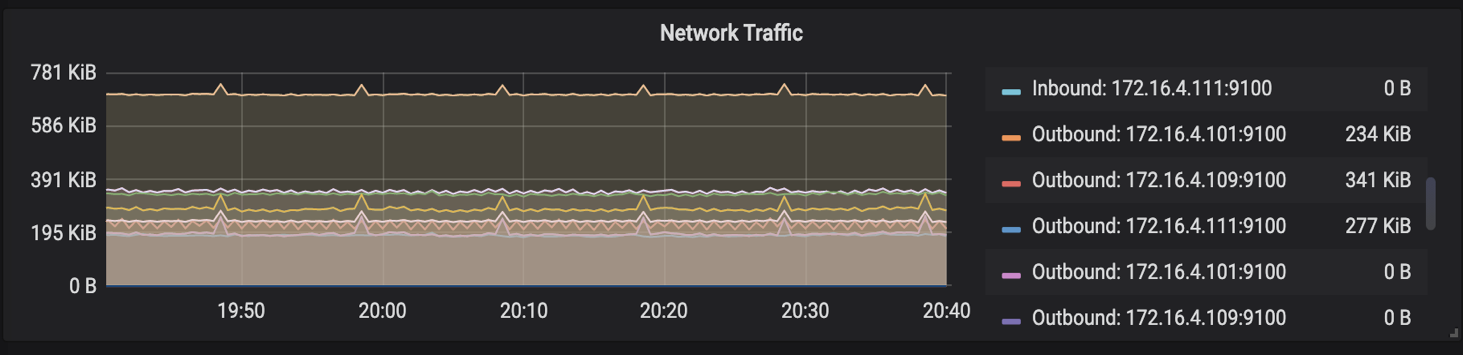
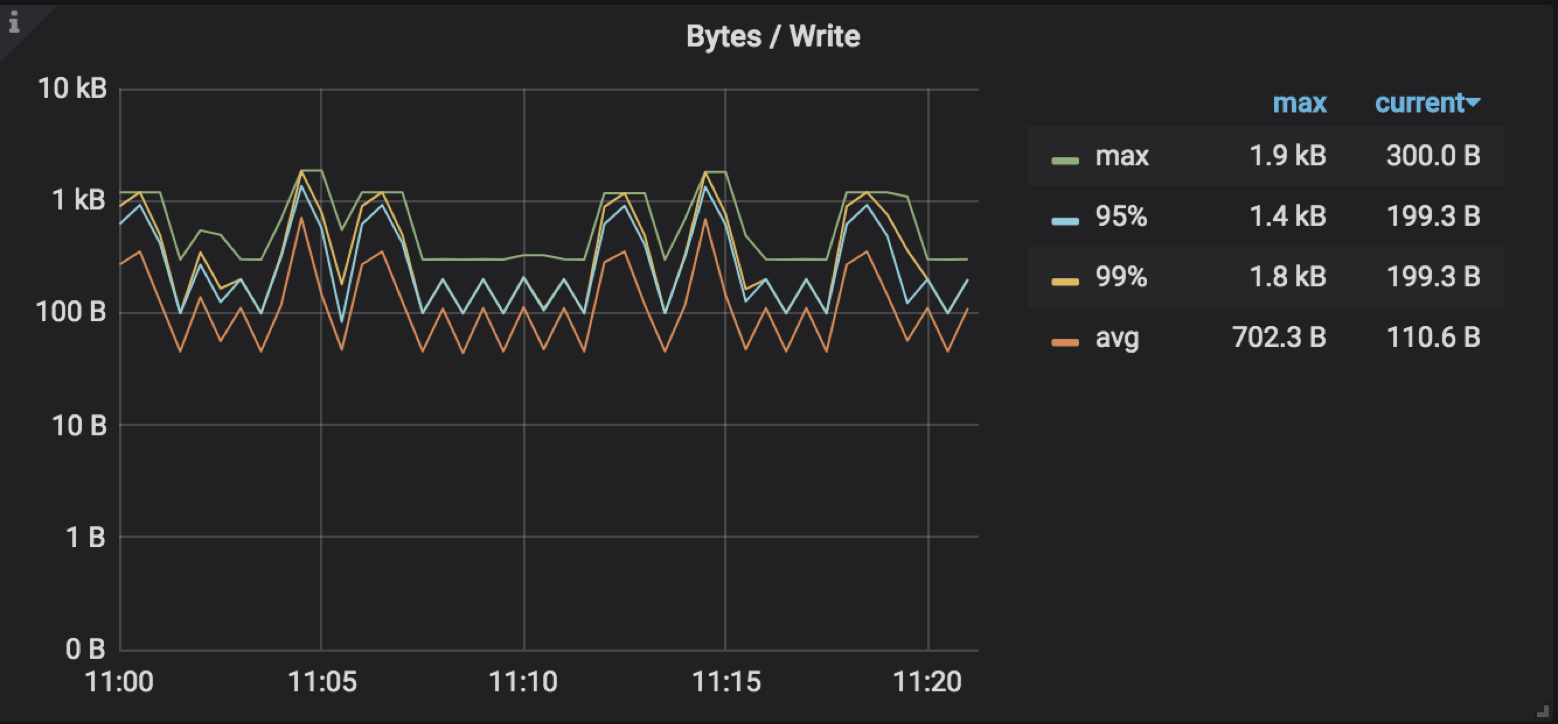
统计 Scheduler 内所有写入请求的写入流量
Scheduler 收到 prewrite 请求的时候首先会进行流控判断,如果 Scheduler 里的请求过多,会直接返回 SchedTooBusy 错误,提示等一会再发送,否则进入下一步。
获取内存锁 Latches
在事务模式下,为了防止多个请求同时对同一个 key 进行写操作,请求在写这个 key 之前必须先获取这个 key 的内存锁。每个 Latch 内部包含一个等待队列,没有拿到 latch 的请求按先后顺序插入到等待队列中。
获取 latch 成功之后把 prewrite 请求交给 scheduler worker pool 进行处理。
scheduler worker pool 收到 prewrite 请求之后,主要工作是从拿到的数据库快照里确认当前 prewrite 请求是否能够执行,比如是否已经有更大 ts 的事务已经对数据进行了修改,具体的细节可以参考 TiKV 官方博客 《TiKV 事务模型概览》。当判断 prewrite 是可以执行的,会调用 async_write 接口执行真正的写入操作。
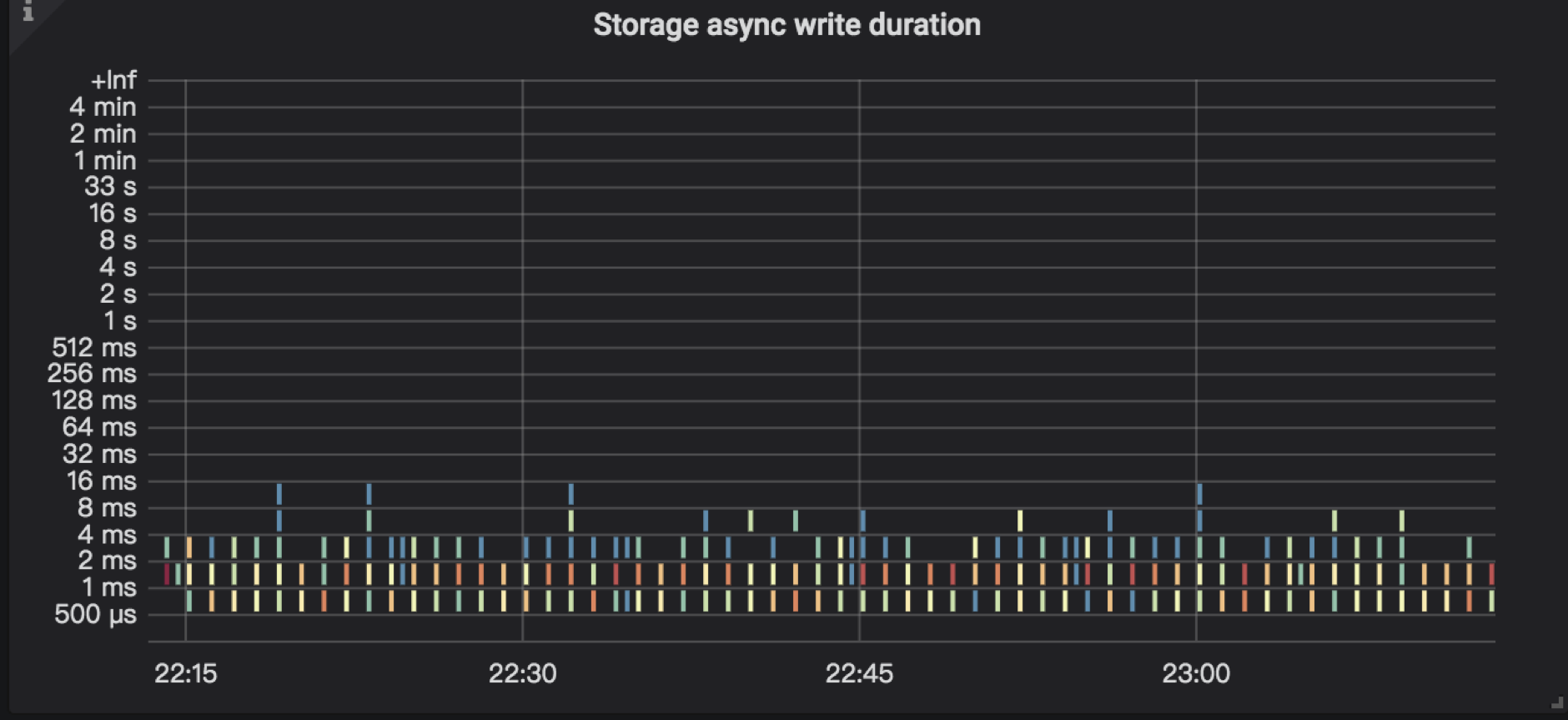
- async write
async write 包括 raft log 的 propose,append 以及 apply 等关键流程结点。这个部分主要涉及下面的模块:
IO:两个 RocksDB 实例
➢ Raft RocksDB 用于保存 raft 日志
➢ KV RocksDB 用于保存 key-value 数据
CPU:两个线程池(每个线程池默认为两个线程)
➢ raft 线程池
➢ apply 线程池
Network:leader 向 follower 同步日志
async write 具体的流程细节如下:
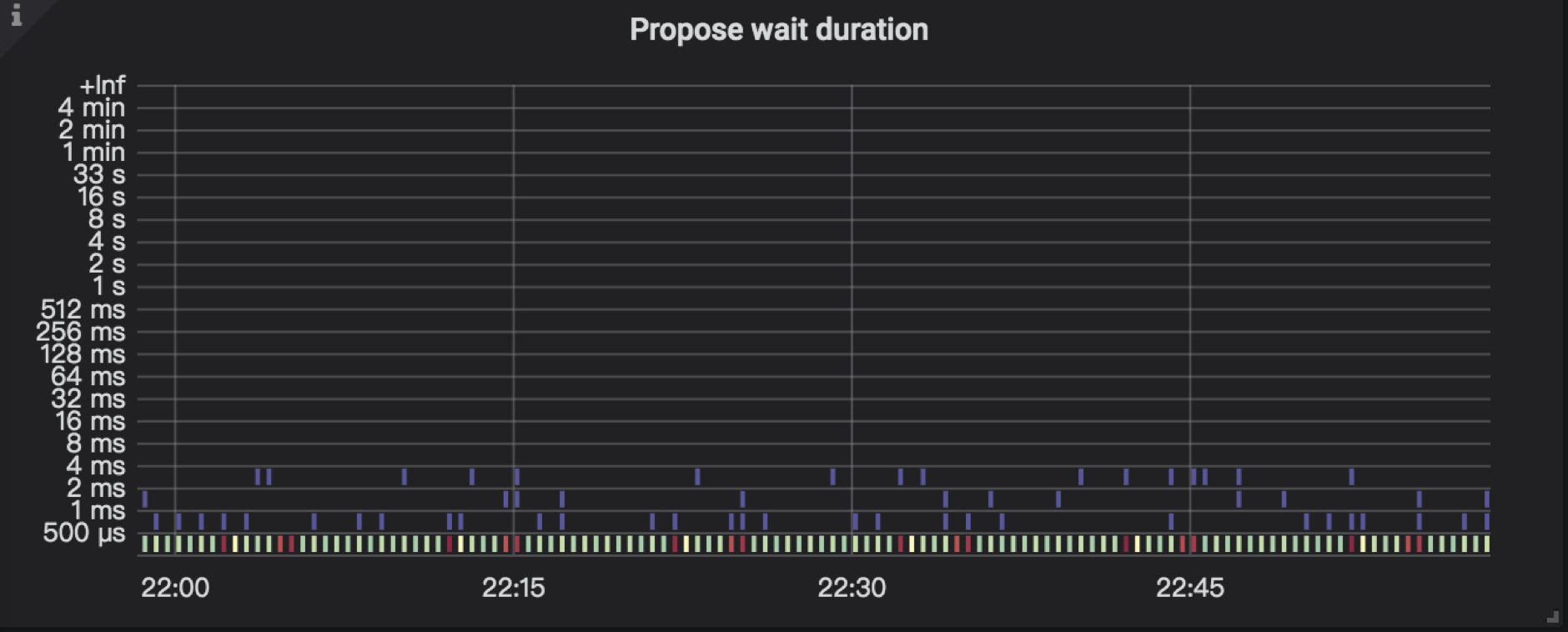
➢ propose
发送请求给 raftstore
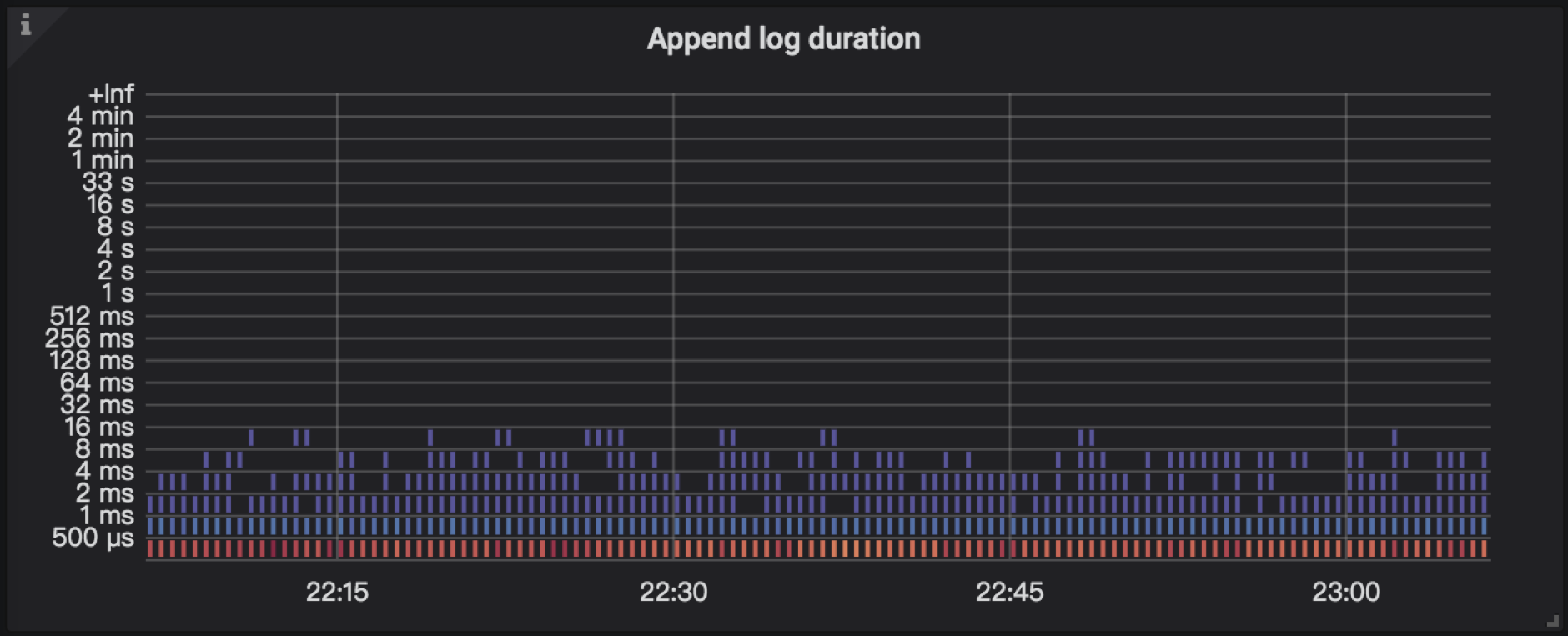
➢ append log
指把 raft log 写入到 raftdb 中。
➢ commit log
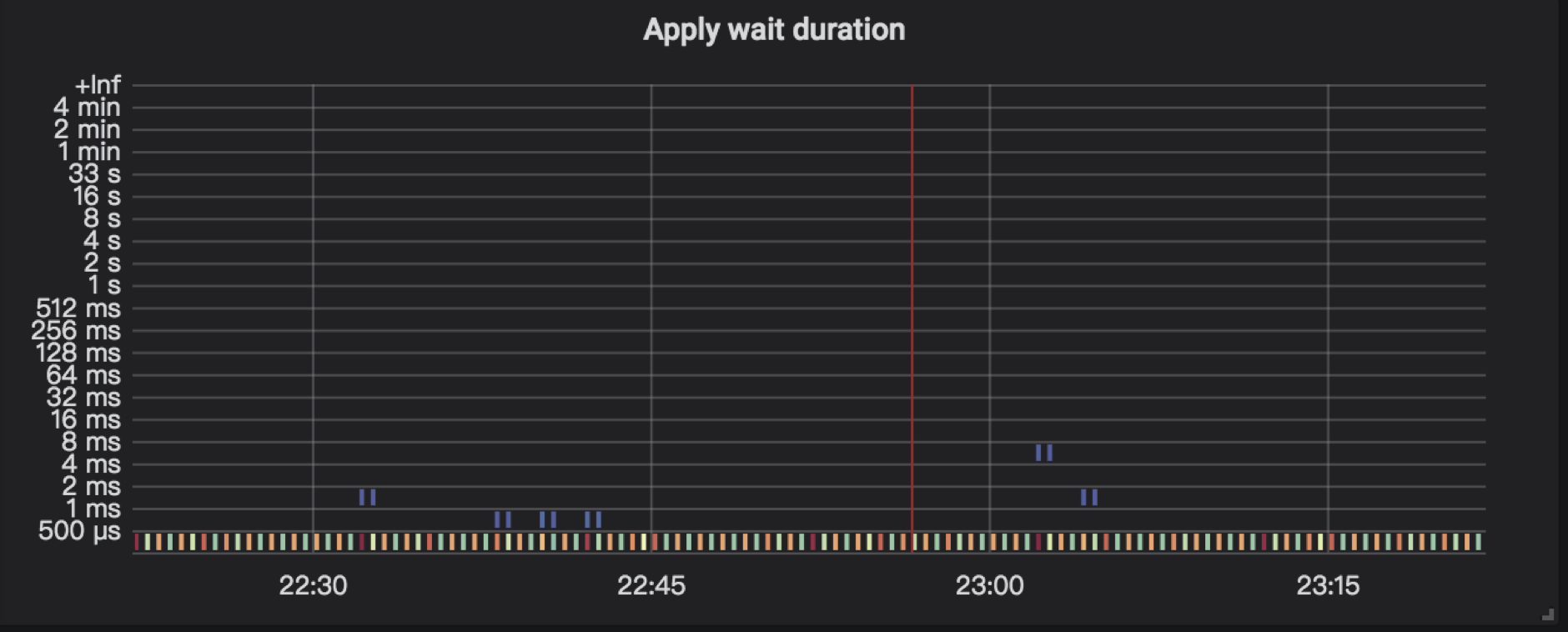
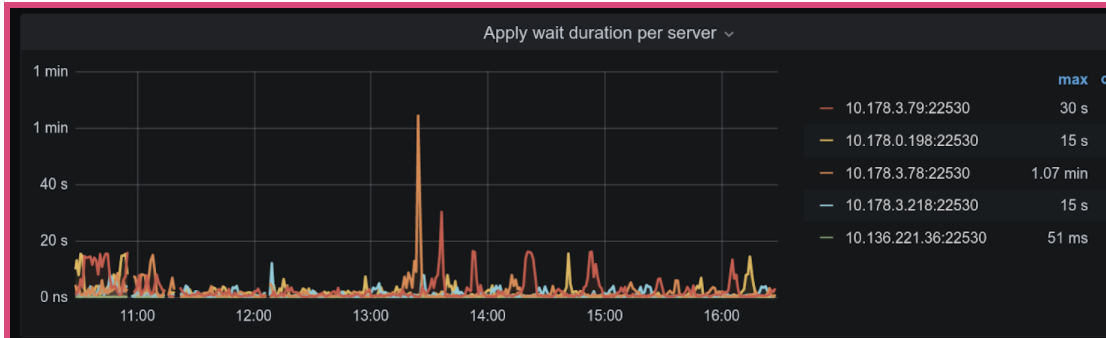
➢ apply wait log
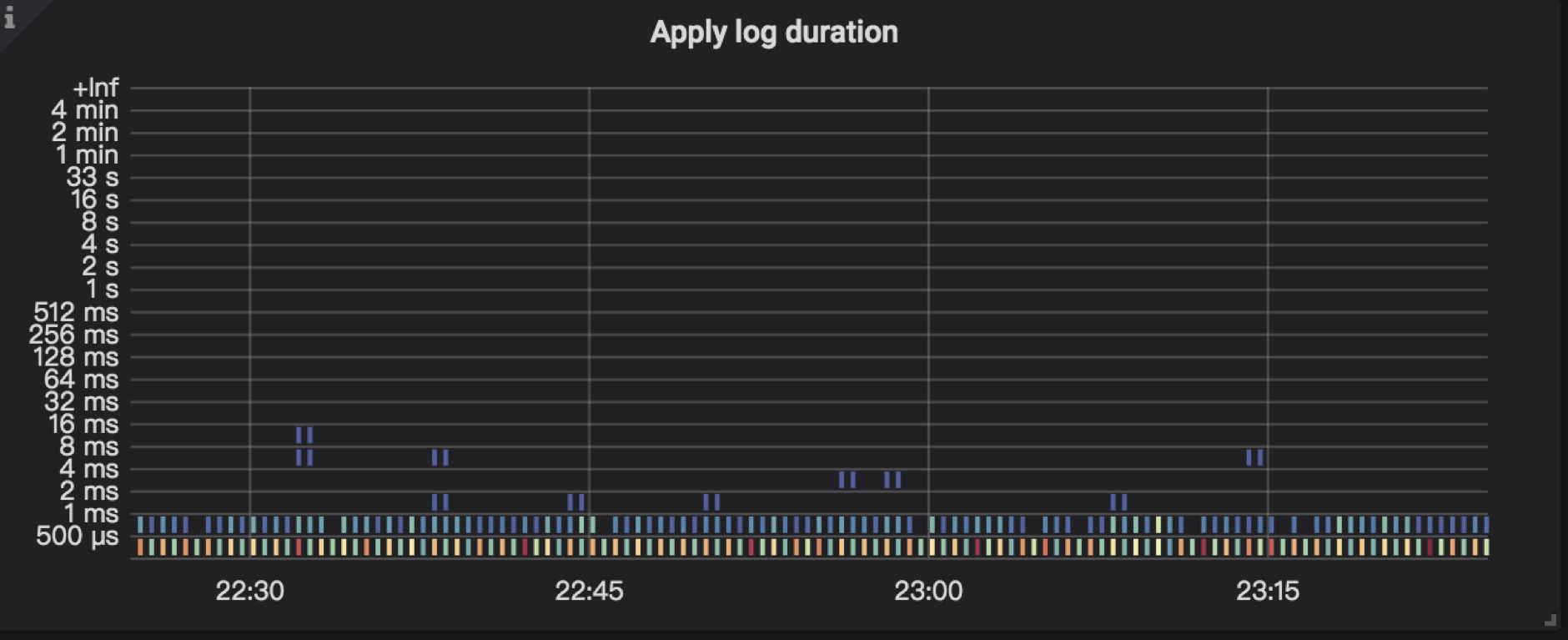
Raft log commit 后,会等待 apply ,这里可能会因为资源繁忙而出现等待的情况。
➢ apply log
当资源充足时,此时会 apply 这条 Raft log,而 apply log 是指把用户数据写入到 RocksDB KV。
- 当 async_write 执行成功或失败之后,会调用 Scheduler 的 release_lock 函数来释放 latch 并且唤醒等待在这些 latch 上的请求继续执行。