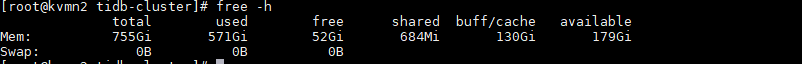【 TiDB 使用环境】
V5.4
【概述】 6.17日使用java多线程脚本,起100个线程,通过JDBC连接,往TIDB里插入1.2T(3019172987条)数据,6.18完成数据写入,tikv长时间占用内存不释放
【现象】 服务无异常,但是内存被tikv大量占用,且长时间不释放,tidb_analyze_version参数已改,storage.block-cache参数已设为100G
![]()

【 TiDB 使用环境】
V5.4
【概述】 6.17日使用java多线程脚本,起100个线程,通过JDBC连接,往TIDB里插入1.2T(3019172987条)数据,6.18完成数据写入,tikv长时间占用内存不释放
【现象】 服务无异常,但是内存被tikv大量占用,且长时间不释放,tidb_analyze_version参数已改,storage.block-cache参数已设为100G
![]()
从你截图里没看到PD进程,只看到3个TiKV
你这明明是tikv-server,这点内存占用是正常的
tikv-server负责数据的持久化,不停的插数据是会消耗内存的,比较正常,题主是有其他什么疑问吗
不好意思看差了,是TIKV
插入数据后,数据最终落盘,缓存在内存中的数据不会主动释放么
我设置每个TIKV节点的缓存是100G, [storage.block-cache]capacity = “100GB”。但是现在这个值已经超出了100G,超过的内存不会释放掉么?
blockCache,主要用来缓存读取最近更新的数据,增加读取命中率和速度,不用通过 memtable 以及 SST 文件去扫描…
大量数据的插入,需要通过 raft 实现分布式的协定,这是普遍的一种操作,N 个节点之间会相互分发数据,以及最终持久化 (所以 tikv 的配置要求会比较高,对于网络要求也是如此)
如果慢的话,我建议你观察下 磁盘IO,是不是早就撑不住了,导致 wirtestall 了,会有流控来保证底层不会出毛病…
查看了一下从数据开始插入到目前的监控数据,磁盘的IOPS是有明显的一个波动,而且从波峰往下跳转时,确实还在数据插入程序的执行过程中,此时是触发了降速,数据仍在进行落盘么?
后续如果再有这种大量数据大插入,应该如何控制可以减少writetall的发生呢?
内存单位不是M吗,这里不是才用了53.8G吗,而且写入消耗内存和你设置的这个参数的配置不直接相关吧,
增加 IO 能力,增加 schedule Pool 资源, 增加内存 ![]()
不过,分布式的方案是采用增加节点的方式来避免热点问题的,合理的打散请求,分散到各个节点上效果会更好。【单节点的资源使用总会有瓶颈的】
[RocksDB 简介 | PingCAP Docs]除了这些我记得还有一些writestall的问题和解决方案,你先看下能不能解决你的问题(https://docs.pingcap.com/zh/tidb/stable/rocksdb-overview#writestall)
明白,有个概念啦
好的![]()
又找到一个,看起来是从表结构入手,还是先调参提高性能,没办法了再看看优化sql表插入数据经常延迟很高, lock_rpc很大 - TiDB / 性能调优 - TiDB 的问答社区 (asktug.com)
嗯,这块的优化确实是没有的,其实我就是为了测试普通的表,普通的sql,在执行大批量插入的时候的数据库性能情况
想再问一嘴,blockcache里缓存的是最近更新的源数据,还是sql,或者是log?
都不是… ![]()
就是 K / V
这个K/V,是最近的sql的执行结果么?
对,可以这么理解