ZZH-QK
(ZZH)
1
执行计划如下:
id task estRows operator info actRows execution info memory disk
Insert_1 root 0 N/A 0 time:1.02ms, loops:1, prepare:252.2µs, check_insert: {total_time: 771.5µs, mem_insert_time: 135.9µs, prefetch: 635.6µs, rpc:{BatchGet:{num_rpc:1, total_time:601µs}, scan_detail: {total_process_keys: 0, total_keys: 1, rocksdb: {delete_skipped_count: 0, key_skipped_count: 0, block: {cache_hit_count: 5, read_count: 0, read_byte: 0 Bytes}}}}}, lock_keys: {time:8.98s, region:2, keys:2, lock_rpc:8.976444878s, rpc_count:2} 965 Bytes N/A
索引信息:PRIMARY KEY (lid,create_time) /*T![clustered_index] NONCLUSTERED */
会是哪方面的问题呢?
1 个赞
db_user
(Db User)
2
可以给出个详细的执行计划么,手动执行也这么慢么,explain analyze看下,感觉有可能是mem 转sst的时候忙不过来了,写热点,或者其他问题
1 个赞
db_user
(Db User)
3
另外说明下explain analyze是真实执行的,建议找张备份表来做这个操作
1 个赞
ZZH-QK
(ZZH)
4
不是全部都这么慢,但出现的频率也很高,explain analyze执行结果如下:
±---------±--------±--------±-----±--------------±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------±--------------±----------±-----+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
±---------±--------±--------±-----±--------------±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------±--------------±----------±-----+
| Insert_1 | N/A | 0 | root | | time:3.19ms, loops:1, prepare:71.1µs, check_insert: {total_time: 3.12ms, mem_insert_time: 69.1µs, prefetch: 3.05ms, rpc:{BatchGet:{num_rpc:2, total_time:2.96ms}, scan_detail: {total_process_keys: 2, total_keys: 7, rocksdb: {delete_skipped_count: 0, key_skipped_count: 5, block: {cache_hit_count: 8, read_count: 0, read_byte: 0 Bytes}}}}} | N/A | 816 Bytes | N/A |
±---------±--------±--------±-----±--------------±----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------±--------------±----------±-----+
集群信息如下:
目前接入的数据还很少,QPS还只有100多,写热点可能性应该比较小,但是内存占用好高,mem 转sst是啥?
1 个赞
db_user
(Db User)
5
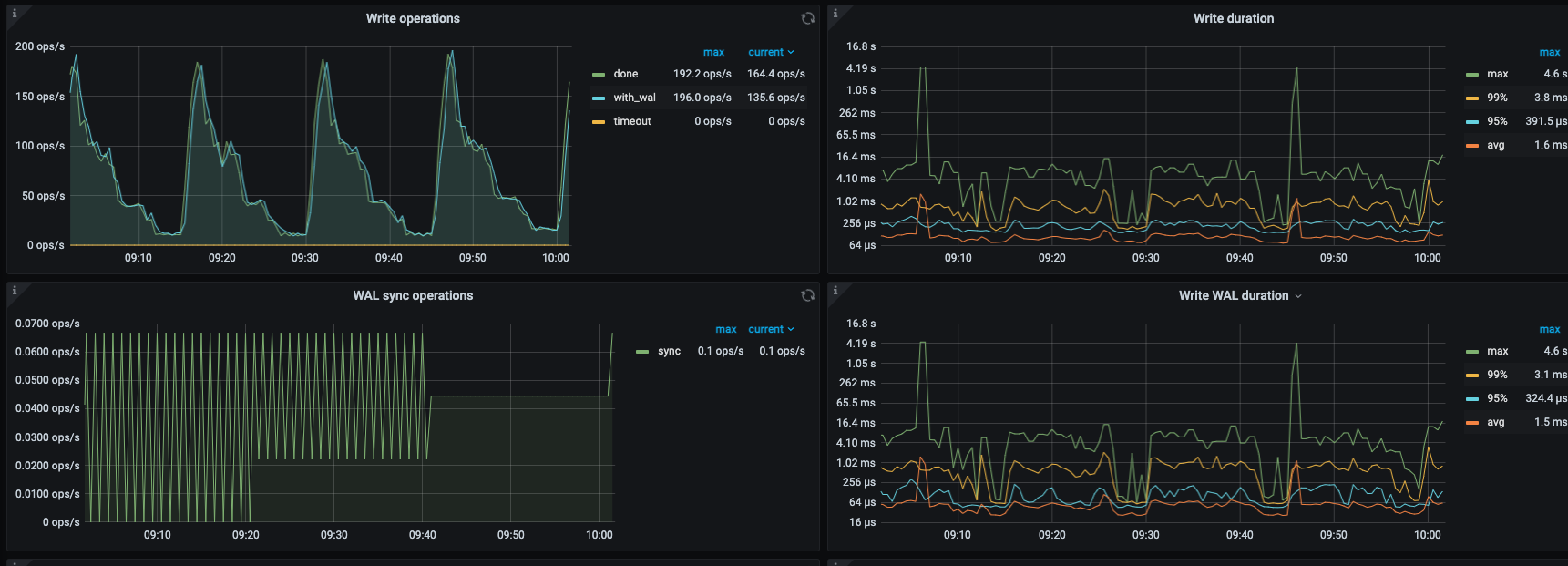
我简写的,写入的时候,会又内存转存到磁盘,如果这个工作过多,忙不过来就会造成WriteStall,限制流量了,所以就慢了,具体分析还要看下插入慢的时间段的具体监控,tikv details里面的thread cpu相关的监控项,磁盘io的监控可以发出来看看
1 个赞
ZZH-QK
(ZZH)
6
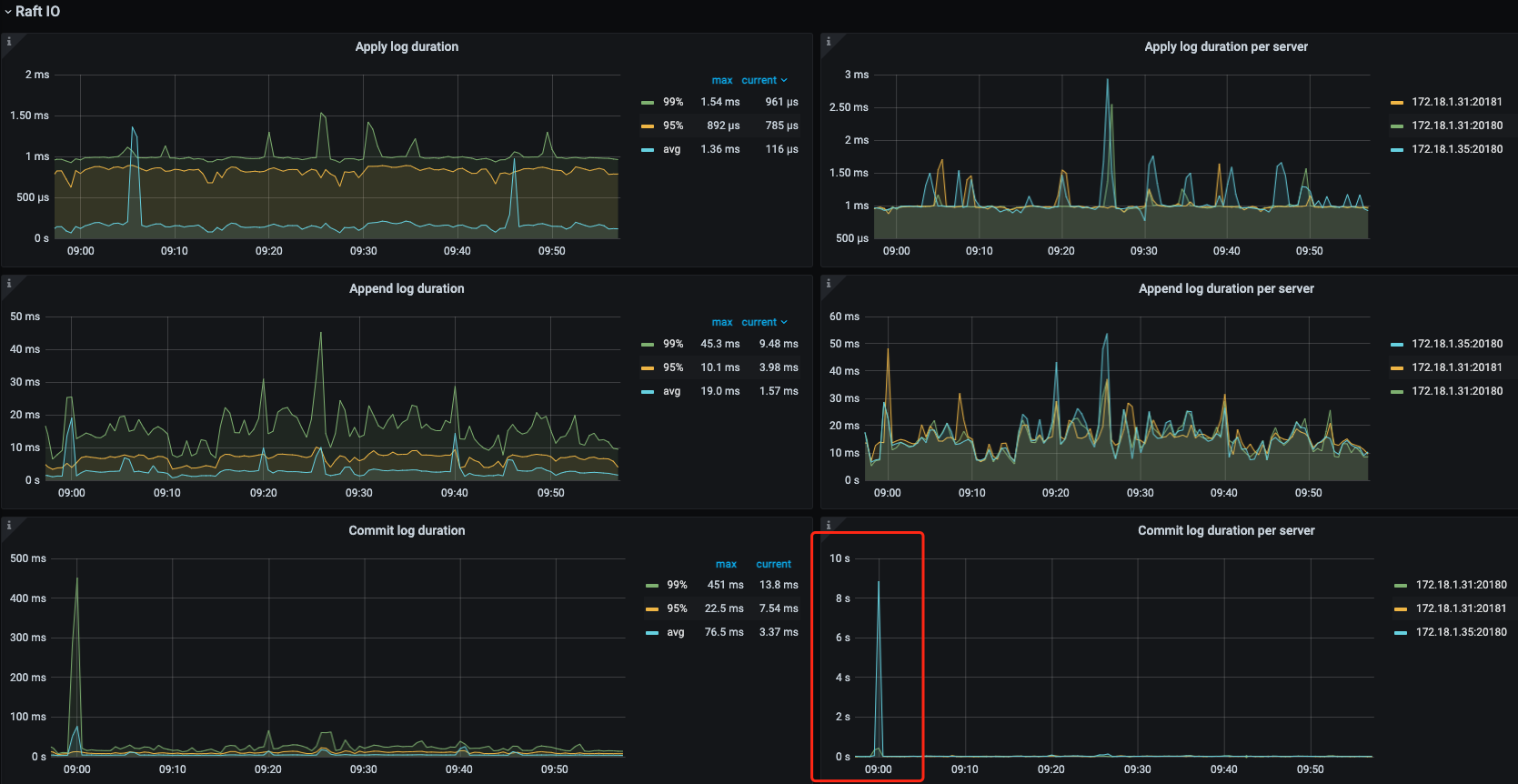
不过写入的并发比较集中,每隔十几分钟运行一次,每次在1-3分钟之内,该表要写入3k多条记录
1 个赞
xfworld
(魔幻之翼)
8
1 个赞
xfworld
(魔幻之翼)
10
1 个赞
db_user
(Db User)
11
看监控像是单台机器写入热点问题,目前看压力在commiy log 这块,可以看下之前提到的thread cpu使用情况和总的cpu使用情况,如果总的cpu小,而thread cpu跑满了,可以调优下相关参数
ZZH-QK
(ZZH)
12
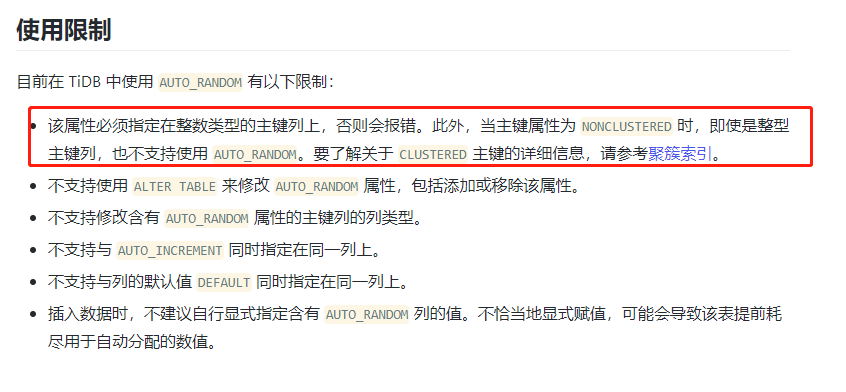
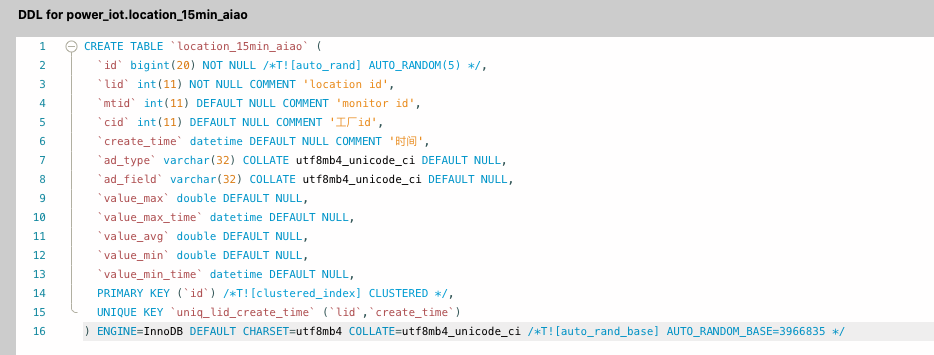
改成用聚簇索引和batch insert了,改善效果很明显 ,现在batch insert偶尔还会出现1-2s耗时
,现在batch insert偶尔还会出现1-2s耗时
ZZH-QK
(ZZH)
13
改成聚簇索引和批量插入后观察了2天,还是有20%的概率出现比较高延迟,具体情况如下:
id task estRows operator info actRows execution info memory disk
Insert_1 root 0 N/A 0 time:11.8ms, loops:1, prepare:1.26ms, check_insert: {total_time: 10.6ms, mem_insert_time: 3.76ms, prefetch: 6.83ms, rpc:{BatchGet:{num_rpc:5, total_time:10.9ms}, scan_detail: {total_process_keys: 300, total_keys: 810, rocksdb: {delete_skipped_count: 0, key_skipped_count: 300, block: {cache_hit_count: 2560, read_count: 0, read_byte: 0 Bytes}}}}}, lock_keys: {time:8.55s, region:4, keys:210, lock_rpc:25.634092514s, rpc_count:4} 164.1 KB N/A
id task estRows operator info actRows execution info memory disk
Insert_1 root 0 N/A 0 time:6.61s, loops:1, prepare:499.9µs, check_insert: {total_time: 6.61s, mem_insert_time: 1.41ms, prefetch: 6.61s, rpc:{BatchGet:{num_rpc:5, total_time:13.2s}, scan_detail: {total_process_keys: 100, total_keys: 210, rocksdb: {delete_skipped_count: 0, key_skipped_count: 40, block: {cache_hit_count: 469, read_count: 0, read_byte: 0 Bytes}}}}}, lock_keys: {time:23.6ms, region:4, keys:70, lock_rpc:38.845329ms, rpc_count:4} 54.7 KB N/A
表信息:
求帮忙看看还可以往哪些方面优化:heart:
xfworld
(魔幻之翼)
14
仅仅是insert ,然后每次batch 都是随机条数,性能差距很大,还是很接近?
基本上要从多个点考虑:
- 硬件性能是否有瓶颈
- 网络是否有瓶颈
- 目前的资源配置是否合理,不合理可能需要调整
这个要查阅granfa 一些指标信息,要做一些调整了
- tidb → tikv rpc 网络延迟排查
- tikv → raft propose 处理延迟排查
- tikv → apply value 处理排查
最好你自己先排查一下,然后汇总一些问题点,看看怎么帮助你
另外可以参考,将问题比较突出部分的一些资源信息导出
建议你新开一个帖子 
疾风之狼
(疾风之狼)
15
我们数据迁移的时候,导入数据都是batch的方式,并且分成若干个事务,速度比单条insert快很多倍。
system
(system)
关闭
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。