【TiDB 版本】
4.0
【问题描述】
正式生产有三个TIKV节点,三个节点在20:40左右全部宕机,麻烦各位给我诊断一下。
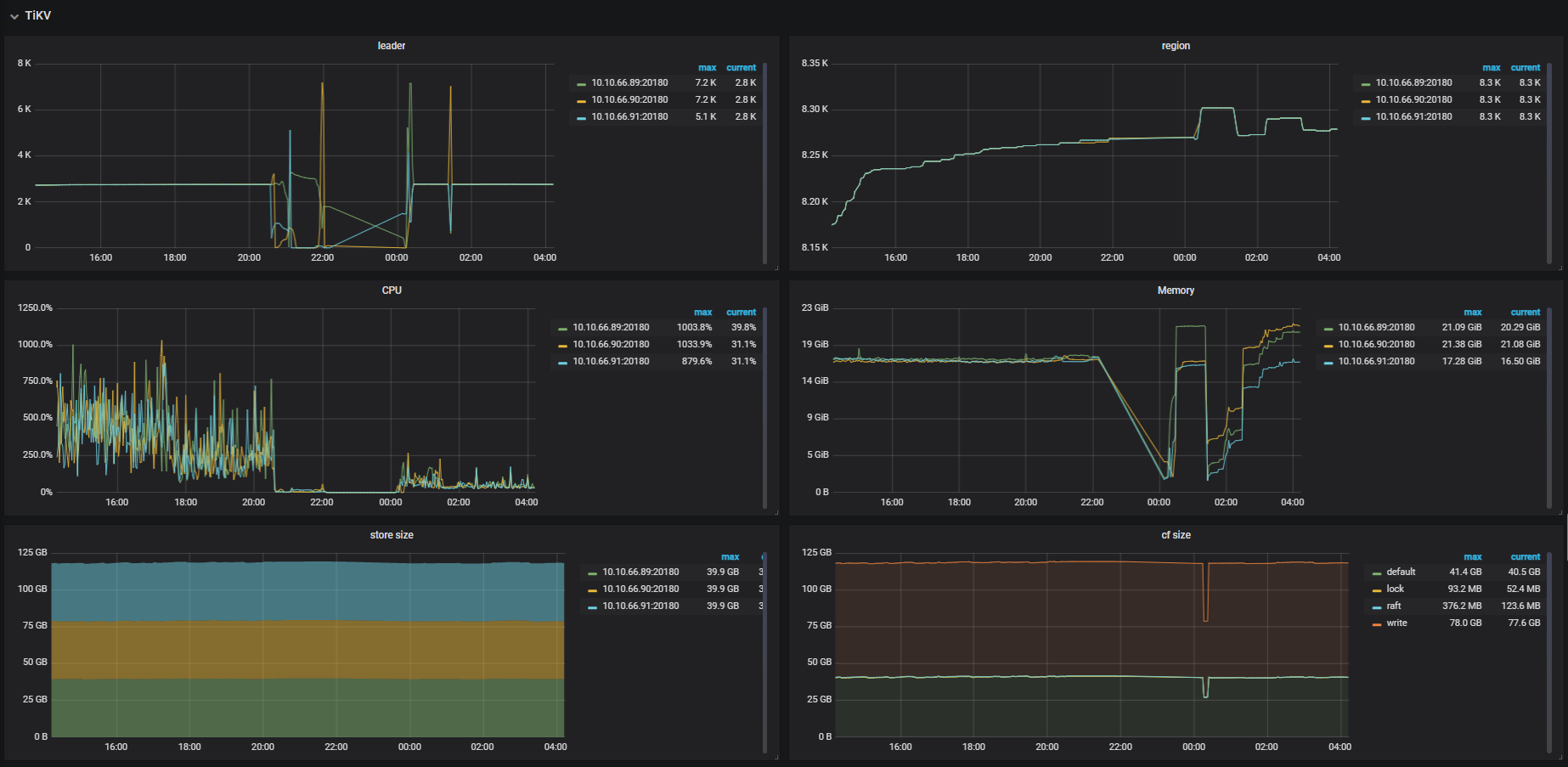
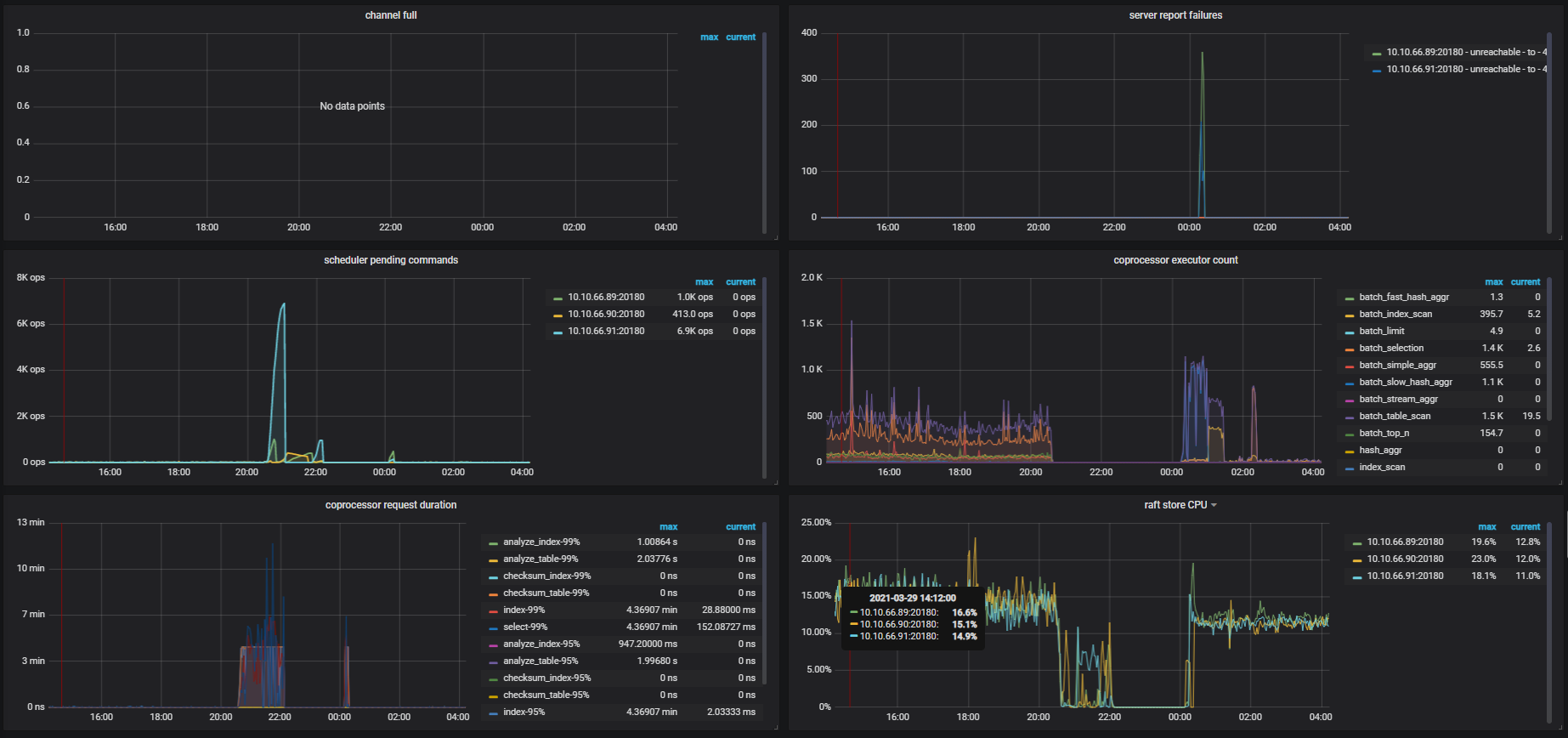
这是故障时间段overview监控
TIDB
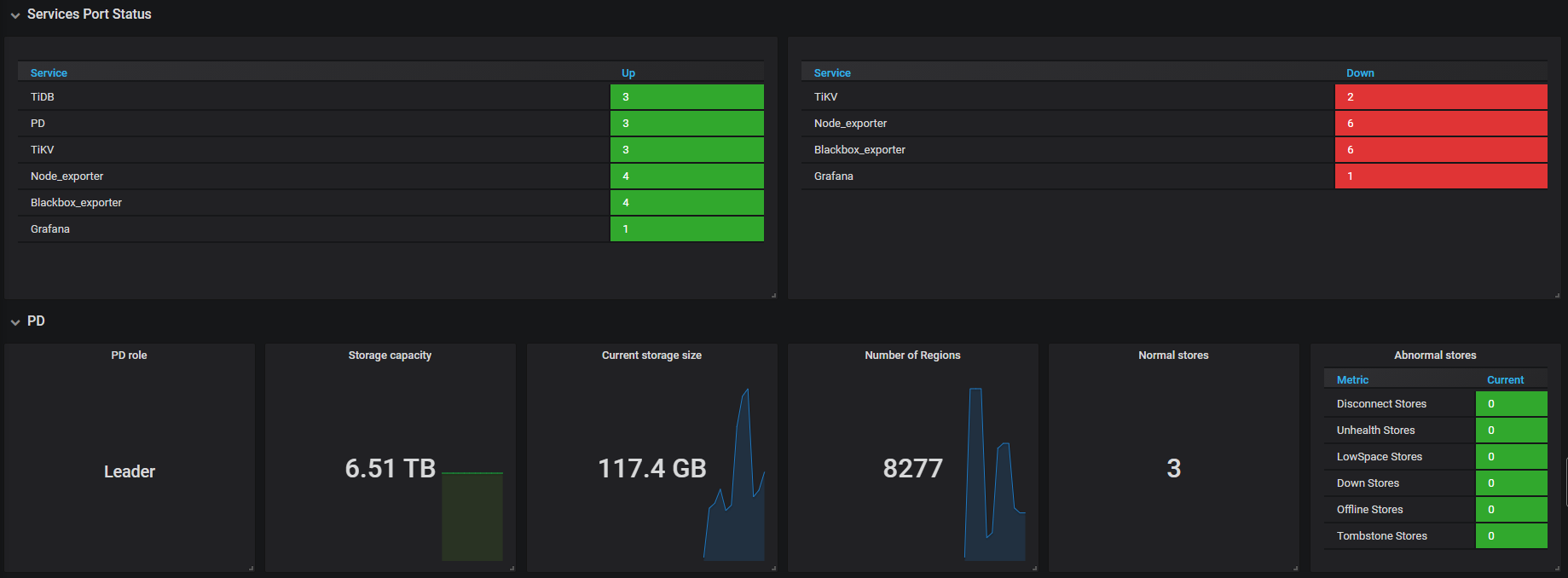
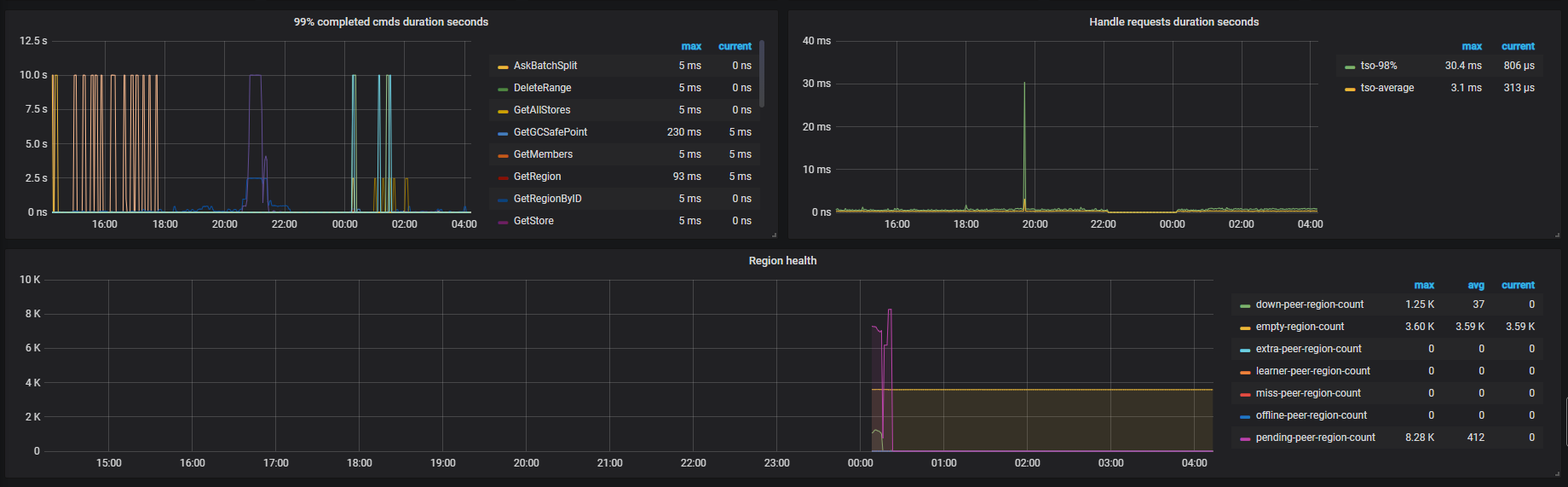
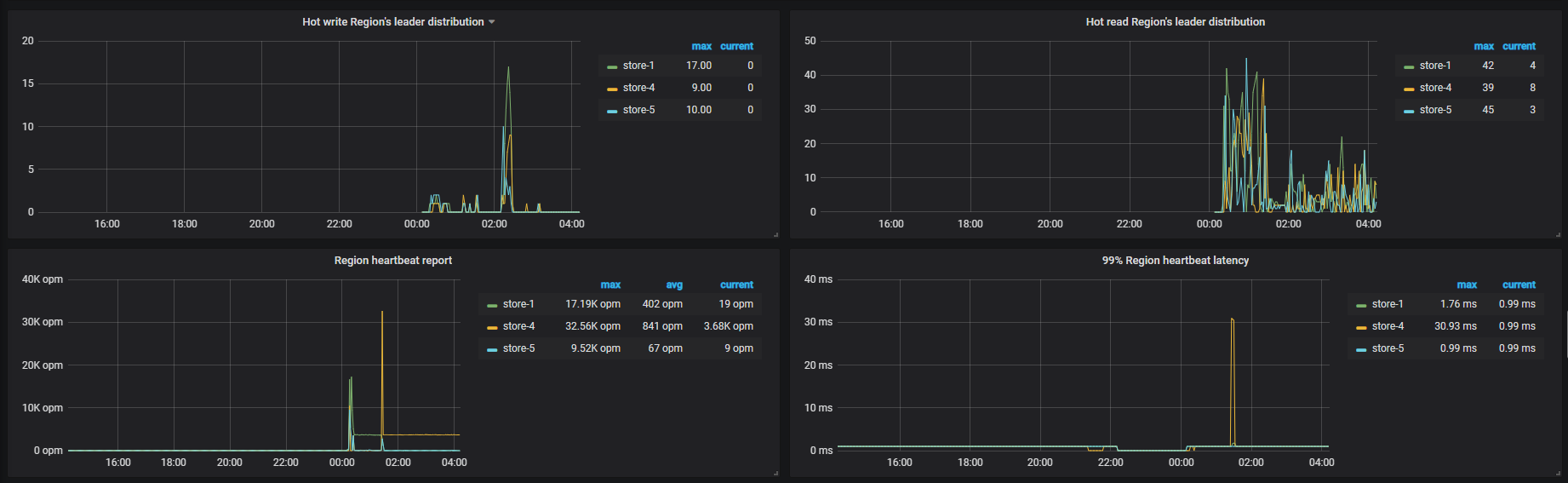
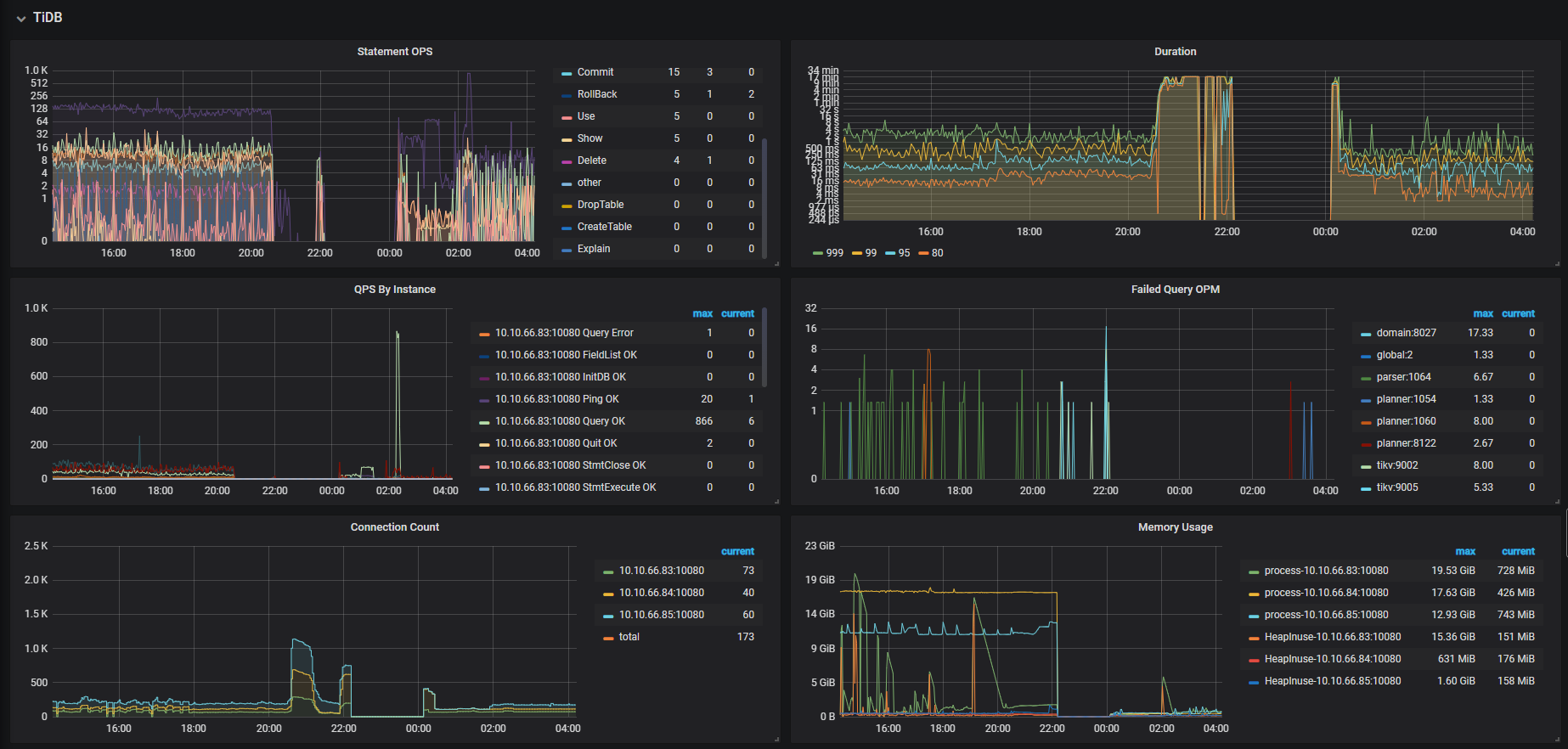
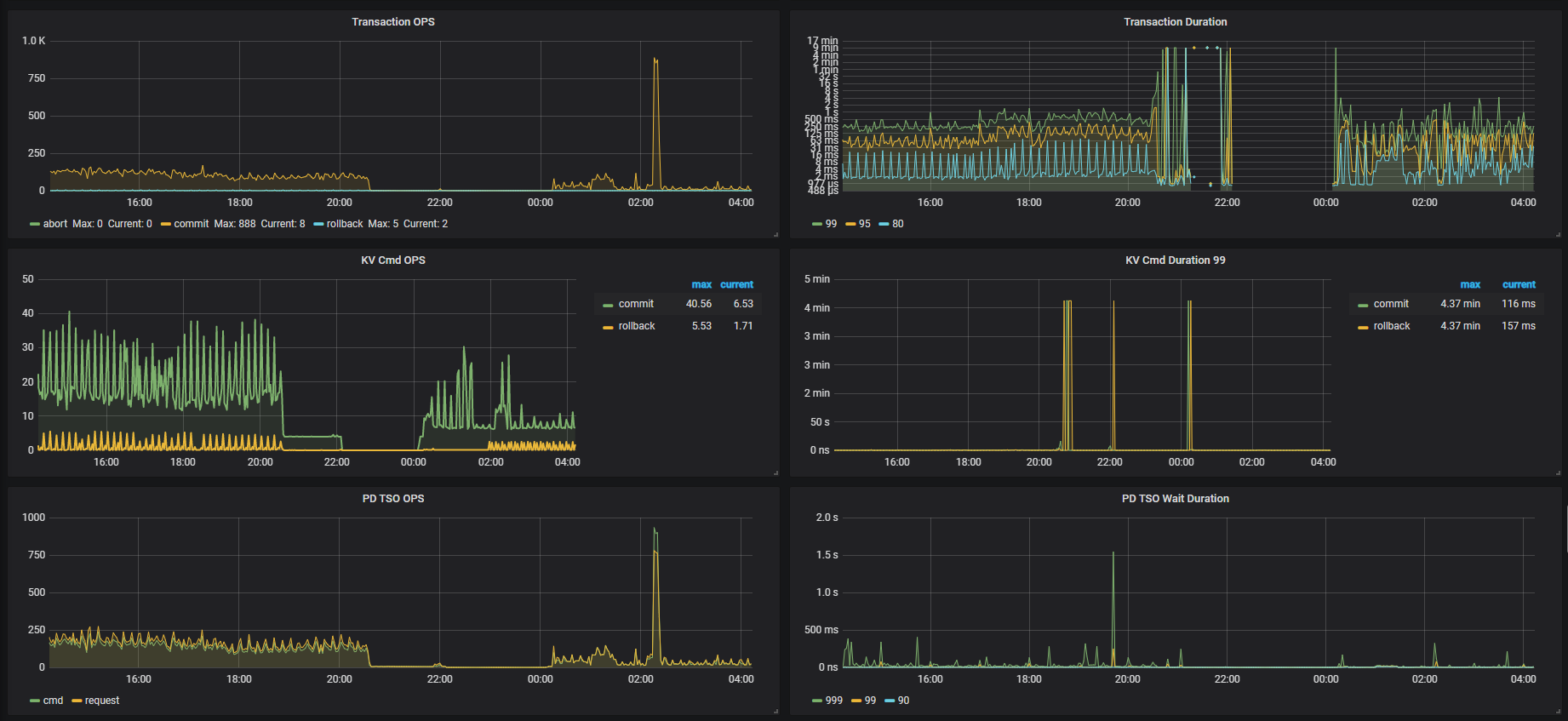
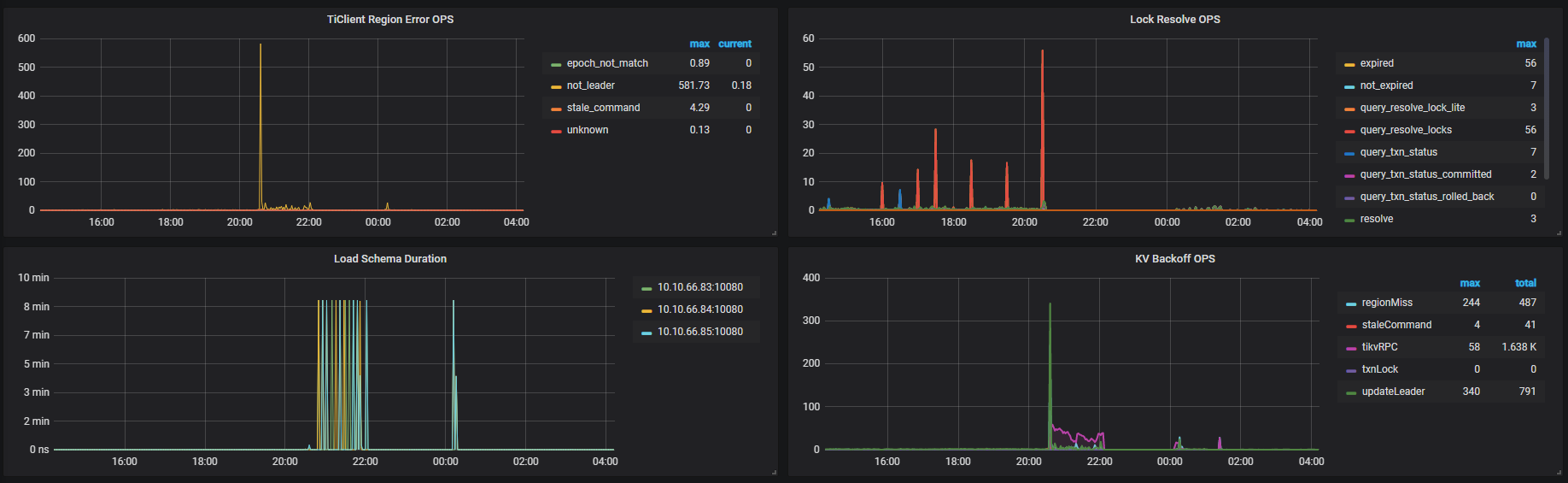
TIKV
1.看了一下没有oom情况
2.这是我日志的百度网盘:https://pan.baidu.com/s/1UOxSzMS5-Hmzayw-bO1Y2g 提取码:i7pz
3.我的TIDB集群中tikv_stderr.log文件是空的。
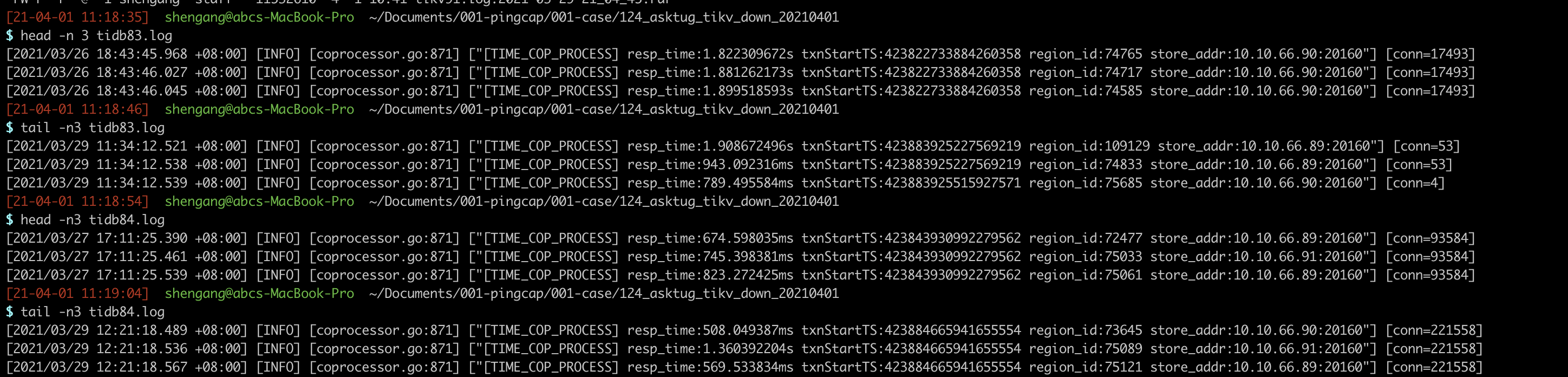
tikv.log日志有点大,麻烦帮我看一下是什么原因导致的集群宕机,感谢!
tidb 和 pd 的日志也麻烦拿一下,拿一下所有节点的,tikv 这个只拿了一个节点。
1、这是83和84节点异常时间段的日志链接: 百度网盘-链接不存在 提取码: kegk
2、这是监控面板数据My-tidb-cluster-Overview_2021-04-01T03_31_42.482Z.json (2.4 MB)
3、异常的时候我这边没做什么操作,业务那边就不清楚了,后面就开始排查问题,在十点左右重启整个集群,重启后还是有故障,最后集群是凌晨三点多才起来的。
其他两个找到了My-tidb-cluster-PD_2021-04-01T06_00_04.643Z.json (2.9 MB) My-tidb-cluster-TiDB_2021-04-01T06_01_13.220Z.json (4.9 MB)
目前看下来怀疑是磁盘 IO 太高导致心跳没有上报,导致 leader 掉底。但是你们监控上的数据,在 22 点之前的数据不存在,不清楚之前是什么情况,无法实锤。
觉得与这个问题比较像:leader抖动问题
能否看出是什么原因导致的IO太高?我看20:30的时候TIDB连接数暴涨到1K,这有影响吗?
这个看不出来原因,你们的磁盘是 SSD 盘吗
你可以看下 node_exporter 监控中各个节点的 disk latency 看下,是否是磁盘访问真的比较慢
嗯,感谢
还有一个问题希望解答一下,我们正式环境和测试环境是在同一个网段的,集群名称也是一模一样,相互之间是否会有影响?
如果端口和目录是分开的,应该运维操作上没有问题。但是机器资源会有争用的情况。
需要考虑有误操作的可能性。
还有TIDB集群恢复的时候具体操作是什么?我们开始恢复的时候一直失败,在整个集群宕机的情况下,是否应该先起两个节点再起最后一个节点?感谢
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。