lmy012
2021 年3 月 15 日 07:29
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】V4.0。4
【问题描述】最近2个星期,集群的leader抖动的非常厉害。具体情况是这样的
二、集群自从上线以来,磁盘IO也是比较高的,以下是最近半个月的磁盘IO情况。
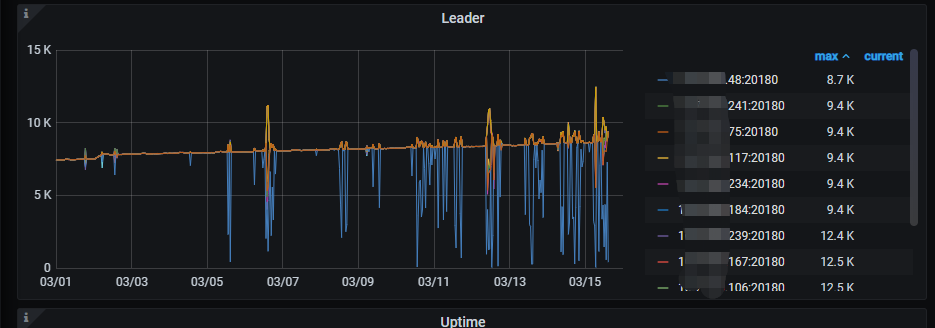
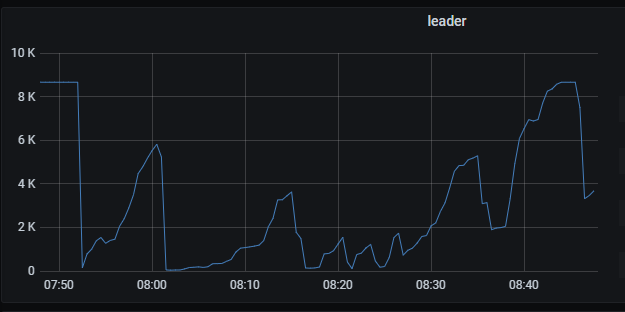
三、自从3月5号开始,集群中的leader数就抖动的非常厉害,如下:
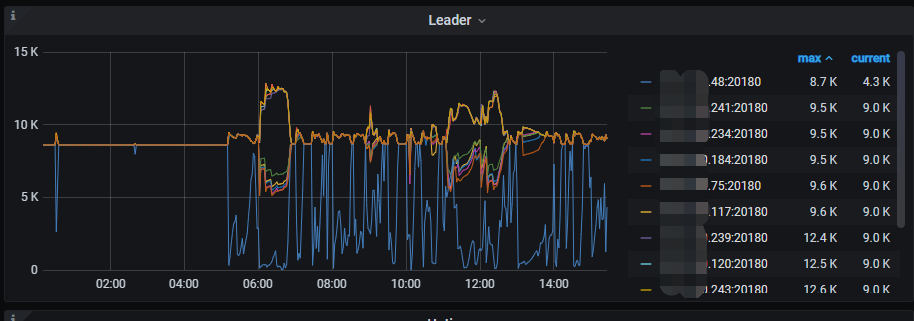
最近一天的情况
集群上线大半年,之前虽然磁盘io很高,但是leader数基本不会抖动,还请帮忙看看是什么原因造成的。谢谢。
overview、tidb、tikv的监控截图(最近12小时的监控截图)百度网盘-链接不存在
lmy012
2021 年3 月 15 日 08:05
2
看了下ip48那台tikv节点的日志,主要存在以下报错信息
lmy012
2021 年3 月 15 日 08:54
4
zhenjiaogao:
node-exporter 的 grafana
不知道为啥,展开面板数一直显示位0,导致没办法导出
如果使用上面的工具无法导出,请尝试将时间范围缩短到 10:00 ~ 12:00 时间段导出看下是否可以 ~
lmy012
2021 年3 月 15 日 09:17
6
还是不行哦,换了2台电脑试也不行,请问下现在你那边可以导出吗?
咱们换个浏览器试试看可以吗?比如用谷歌 ~
如果更换浏览器还是不行的话,请先将下面的信息,导出成 pdf:
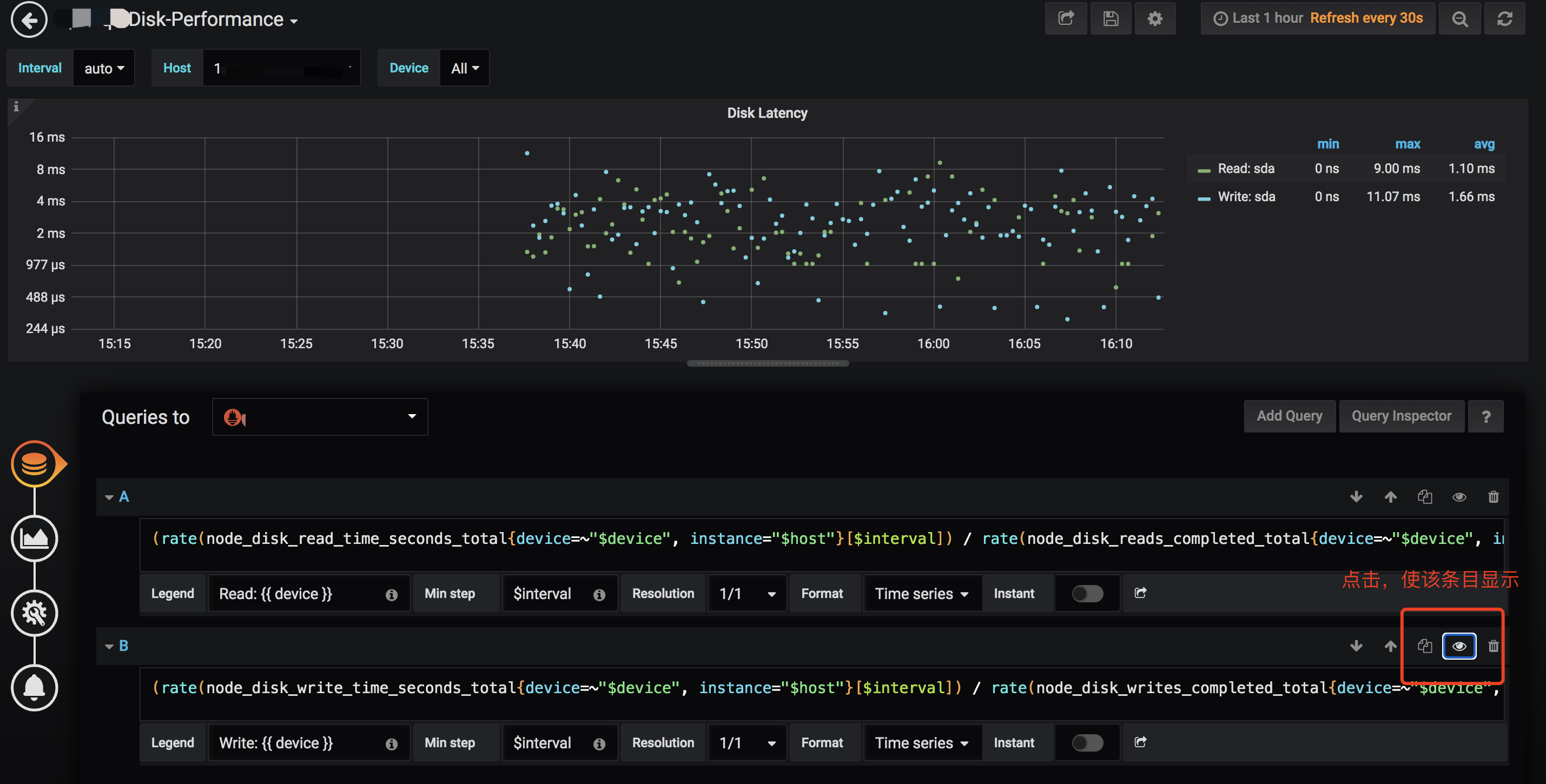
x.x.x.48 这台 TiKV Server 的 disk-performance 的 grafana 监控,注意默认情况下,write latency 不显示,请通过上面的方式将 write latency 显示
x.x.x.48 这台 TiKV Server 的 node-exporter 的 grafana 监控
PD Server ,TiKV-Details ,TiDB Server 的 grafana 监控完整的导出 ,之前的监控只有部分监控信息
另外,咱们这个环境使用的磁盘是什么类型的盘?SATA ,还是 SATA SSD?
lmy012
2021 年3 月 15 日 09:44
8
我一直用的是谷歌,以前导出过json格式的,现在导不出来了……
lmy012
2021 年3 月 16 日 00:56
10
zhenjiaogao:
node-exporter
选取了昨天16::30-18:30的监控截图,这个时间点也是比较明显的抖动,还请通过百度网盘获取下监控截图。
链接:百度网盘 请输入提取码
lmy012
2021 年3 月 16 日 01:18
11
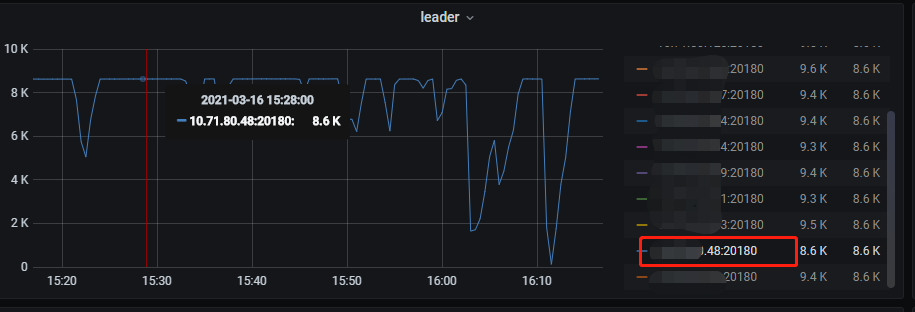
另外,从今天早上的io、leader监控上看,io高、leader同时段会抖动,不确定是因为io导致leader抖动,还是因为leader抖动了导致io升高
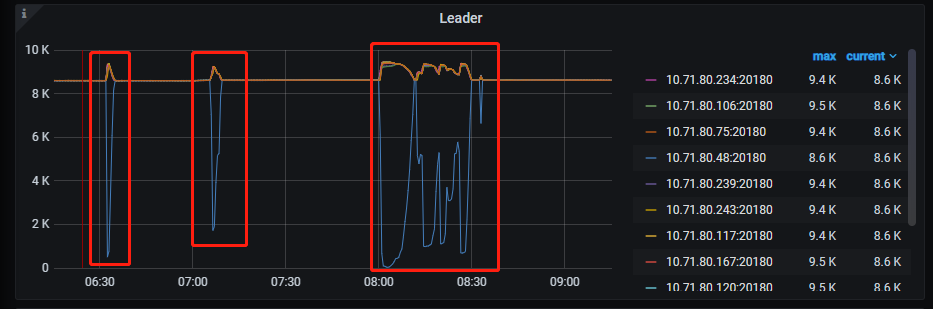
可以在 leader 会掉底的 tikv 节点上, grep -i welcome tikv.log 看下 tikv 有没有重启的情况。
或者在 tikv-details 监控项下,只显示 leader 掉低的 store (红框中的 store)的 leader 以及 uptime 监控信息 :
lmy012
2021 年3 月 16 日 08:20
13
GangShen:
grep -i welcome tikv.log
这台掉底的就是48那台主机,这台主机的tikv在3月4号有过重启
那可以提供一下完整的 pd leader 节点日志以及 leader 掉底的这个 tikv 节点日志看下么
lmy012
2021 年3 月 16 日 11:06
15
可以的,需要提供哪个时间段的?还是我自己找某个时间段即可?
选择一段 leader 抖动比较严重的时间段吧,日志时间也需要覆盖对应的时间段。
lmy012
2021 年3 月 17 日 01:05
17
链接:百度网盘-链接不存在
目前看下来的话还是 48 这个节点磁盘 write latency 抖动升高导致 leader 抖动。
raft 协议中,如果 follower 节点在一定时间内没有接受到 leader 发送的心跳信息,会触发超时选举。这个从 tikv 日志中也可以确认
[2021/03/17 07:51:25.066 +08:00] [INFO] [raft.rs:1739] ["[term 281] received MsgTimeoutNow from 35633931 and starts an election to get leadership."] [from=35633931] [term=281] [raft_id=35355712] [region_id=741956]
[2021/03/17 07:51:25.066 +08:00] [INFO] [raft.rs:1177] ["starting a new election"] [term=281] [raft_id=35355712] [region_id=741956]
[2021/03/17 07:51:25.066 +08:00] [INFO] [raft.rs:807] ["became candidate at term 282"] [term=282] [raft_id=35355712] [region_id=741956]
received MsgTimeoutNow 这个表示接受心跳消息超时。tikv.log 中有大量类似的消息,证明有比较多的因为心跳超时触发的 leader 选举。
建议可以检查一下磁盘情况,必要的话可以缩容并扩容,更换磁盘观察一下。