【 TiDB 使用环境`】生产环境
【 TiDB 版本】
v5.1.0
【遇到的问题】
为解决生产TiDB数据库磁盘可用空间越来越少问题,先准备对生产数据库进行扩容,有没有类似es命令,可以查看扩容进展,比如进行中、完成情况?
【 TiDB 使用环境`】生产环境
【 TiDB 版本】
v5.1.0
【遇到的问题】
为解决生产TiDB数据库磁盘可用空间越来越少问题,先准备对生产数据库进行扩容,有没有类似es命令,可以查看扩容进展,比如进行中、完成情况?
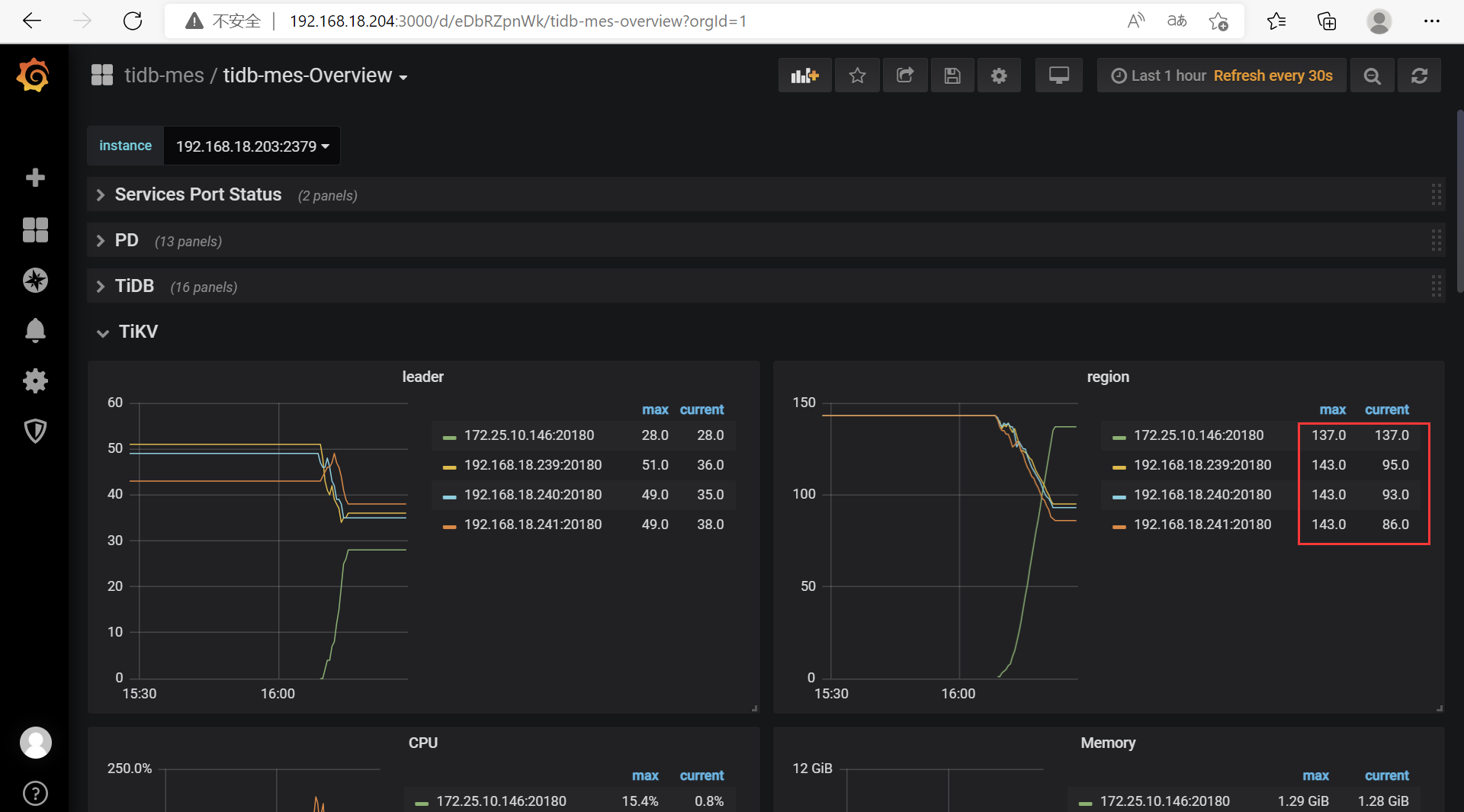
这种情况就需要扩容tikv节点了,扩容的时候很快就会完成,但是等region迁移时间会花的比较久。根据grafana中的overview可以观察tikv的region和leader面板的情况,来判断迁移是否完成
我现在测试TiDB扩容,我需要使用tiup cluster edit-config tidb-mes命令把查到的信息全部都编辑到topology.yaml中吗?还是只编辑新增tikv信息即可:
新tikv信息:
tikv_servers:
扩容的步骤是这样的,创建一个扩容用的拓扑文件,写入你要扩容的节点信息,就是你写的这个tikv的这些,然后执行扩容命令就行。tiup cluster edit-config是修改配置用的,不要直接修改节点信息
使用 TiUP 扩容缩容 TiDB 集群 | PingCAP Docs
官方的操作手册写的很清楚了,你扩容的配置文件就写你需要扩容的组件就行,不用把初始的配置文件复制到扩容的配置文件中。
意思是只需要写新tikv信息,其他信息不需要填写吗?那后期配置文件是不是以scale-out.yaml为主还是以topology.yaml为主,即:
[tidb@tiup ~]$ vi scale-out.yaml
tikv_servers:
是这样写,要扩容什么就写什么信息。扩容完成后,整个集群的拓扑文件会发生改变,会把你扩容的信息自动加到集群的拓扑文件中
好的,谢谢!
在es中可以使用如下命令查看文档同步数量,TiDB有没有命令查询region数量?
curl -X GET “http://x.x.x.x:10501/_cat/shards”|grep RELO
curl “y.y.y.y.:10501/_cat/allocation?v”
在tidb中我一般就是看region数量差不多一致就算是迁移完成了。但是你现在这个有点奇怪,新增的tikv节点的配置和其他tikv节点一致吗
配置不一样,新tikv节点配置高点。
可以在Grafana上看,当然也有HTTP接口来看
https://download.pingcap.com/pd-api-doc.html
最终region数量是否相等还和store的score相关
那就说的通了,因为tidb会给store打分,而新的tikv节点配置高,所以store的分数会高,那region数量就会更多,所以目前看是正常的
确实是这样,这个是测试环境,生产环境配置就一样了。还有请教一下操作期间对cpu、io都有所增加,但是这个是测试环境,就不知道生产实施后对业务影响可大?
这个影响我没测试过,region迁移肯定是对线上环境有影响的,但是一般影响不会太大。
担心这个的话,可以选择业务低峰期扩容tikv,然后调整参数,加速region迁移速度。
调度速度受限于 limit 配置。PD 默认配置的 limit 比较保守,在不对正常业务造成显著影响的前提下,可以酌情将leader-schedule-limit或region-schedule-limit调大一些。此外,max-pending-peer-count以及max-snapshot-count限制也可以放宽。
已经扩容成功了,数据在自动均衡,感觉速度有点慢,我按如下参数调整不知可合适?其中 max-pending-peer-count以及 max-snapshot-count是调大还是调小?
(2)、已经修改值
config set leader-schedule-limit 32
config set region-schedule-limit 4096
config set max-pending-peer-count 32
config set max-snapshot-count 16
我觉得可以,你先调整看看效果和集群状态。那两个参数是调大。
我已经将值调整到如下设置,感觉还是有点慢,MQ没有堵,IO 50%左右,继续观察,看是否可以调整更大点:
config set leader-schedule-limit 96
config set region-schedule-limit 8192
config set max-pending-peer-count 96
config set max-snapshot-count 96
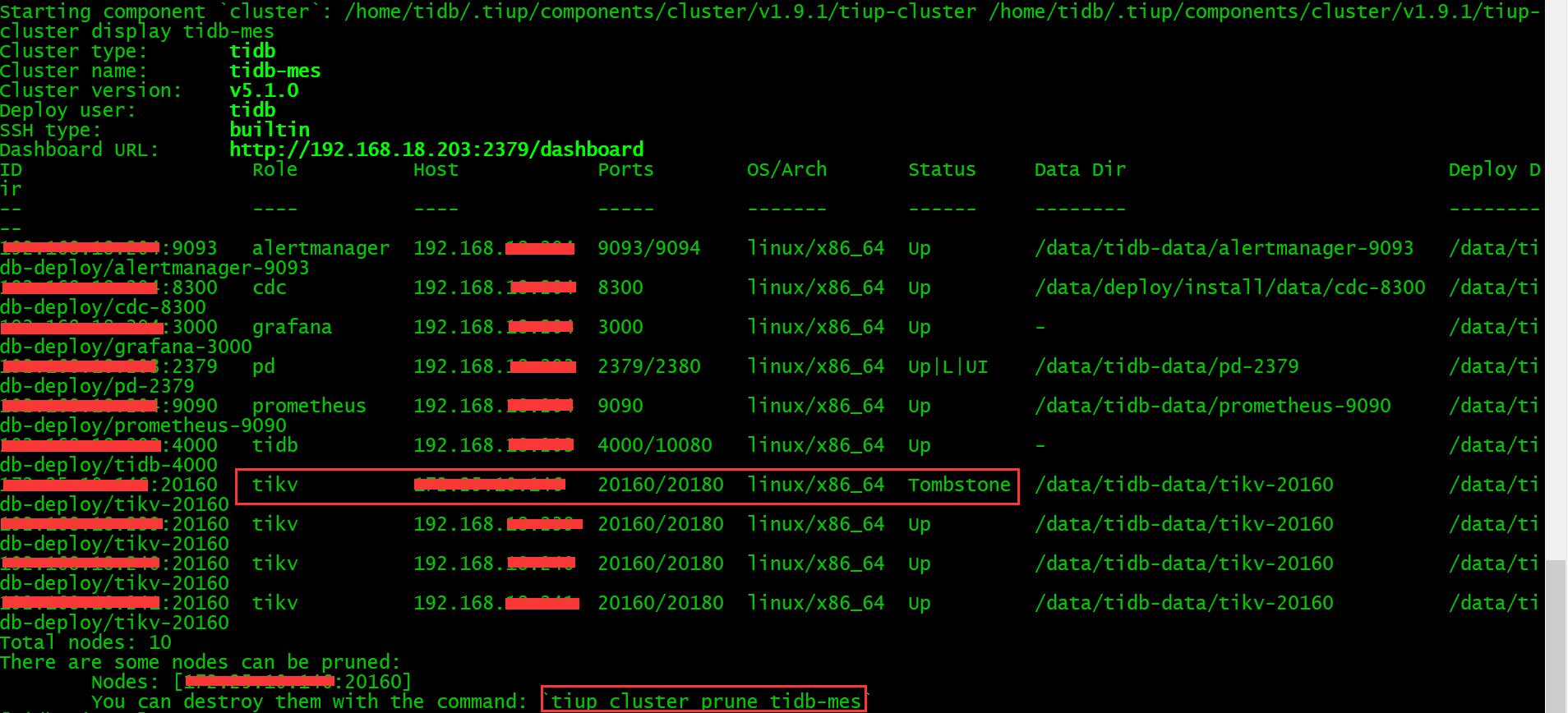
还有我在测试环境执行缩容后,缩容节点还存在,是否需要用命令(You can destroy them with the command: tiup cluster prune tidb-mes)单独删除(删除命令是不是tiup cluster prune tidb-mes --node x.x.x.x:20160)。
tiup cluster scale-in tidb-mes --node x.x.x.x:20160