高兴的太早了,只是可以正常连接了,表数据还不能访问,在尝试和收集信息。
pd-recover流程就是按照我上边发的k8s环境下的链接步骤做的。

tidb目前patch的replica值是1,但是因为tidb container始终无法ready已经主键自动扩展到了3个。

tidb日志没有其他WARN和ERROR,全是在30s一次重复报这个ccResolverWrapper的信息,请问这个是tidb 4000端口一直无法ready的原因吗
补充一个kebelet的完整片段日志:

kubelet当中与tidb相关的也是在重复这一段。
看了下"ccResolverWrapper: sending new addresses to cc“这个日志是 google.golang.org/grpc 里的Info级别的日志打印。
tidb 报啥错,我不会 k8s![]()
这个解决了吗?我们使用k8s部署的时候也有很多报错,但是目前没有影响使用,tidb一直在抛ERROR
问题就是tidb不报错… debug日志开起来才会有重复的如下输出:
[2022/06/29 18:11:50.878 +08:00] [DEBUG] [config.go:139] [backoff] [base=500] [sleep=1611] [attempts=226]
[2022/06/29 18:11:52.490 +08:00] [DEBUG] [backoff.go:220] ["retry later"] [error="region not found for key \"mBootstra\\xffpKey\\x00\\x00\\x00\\x00\\xfb\\x00\\x00\\x00\\x00\\x00\\x00\\x00s\""] [totalSleep=512652] [maxSleep=1200000] [type=pdRPC] [txnStartTS=434240749430112258]
进到tidb pod能看到连接到2379端口的连接,tidb container里进程也是正常启动状态的,但是4000端口就是起不来,所以tidb container的状态一直是notReady。
最近一段时间尝试过升级tidb-operator到1.2.7,升级tidb到5.1.4版本,现状依旧。
也尝试过tispark读取,但是发现外部spark不能正常访问k8s,需要在同一个k8s集群装spark,然而要求k8s 1.20以上版本。
感觉数据要彻底GG了![]()
您好,看最新的报错是 region 坏了,看下还有其他 peer 吗?切换一下,通过 https://docs.pingcap.com/zh/tidb/stable/pd-control#operator-check--show--add--remove
pdctl region key --format=encode "mBootstra\\xffpKey\\x00\\x00\\x00\\x00\\xfb\\x00\\x00\\x00\\x00\\x00\\x00\\x00s"
显示为null,但是我确实没有删除过pv,目前pv的状态都正常。
您好,没删过那应该还有 peer 有完整数据,按我发的步骤修复一下吧,如果没有 replica 了那只能数据丢了。
不需要查所有 region,只需查不正常的即可,通过 https://docs.pingcap.com/zh/tidb/stable/pd-control#region-check-miss-peer--extra-peer--down-peer--pending-peer--offline-peer--empty-region--hist-size--hist-keys
看了下miss-peers没有,down peer有一些(22个),不过显示的store-id其实状态目前都是Up状态的且其他3个peer正常,应该是failover失败的产物,down状态peer所在的store_id过滤了一下,没有异常的,都在当前集群store列表里。
如果store状态正常但是其上存在down peer,这可能是因为store所在的pv被清理过吗?
那应该没问题了,把 down peer 通过添加 operator 的方式移除掉吧,参考 https://docs.pingcap.com/zh/tidb/stable/pd-control#operator-check--show--add--remove
确认没有状态异常的 region 后,尝试启动 tidb-server 看还有没有报错。
在顺序处置22个down peer的过程中,遇到一个region无法正常处理的场景
下述分别为pdctl表象、pd leader日志,store_id=1的tikv日志
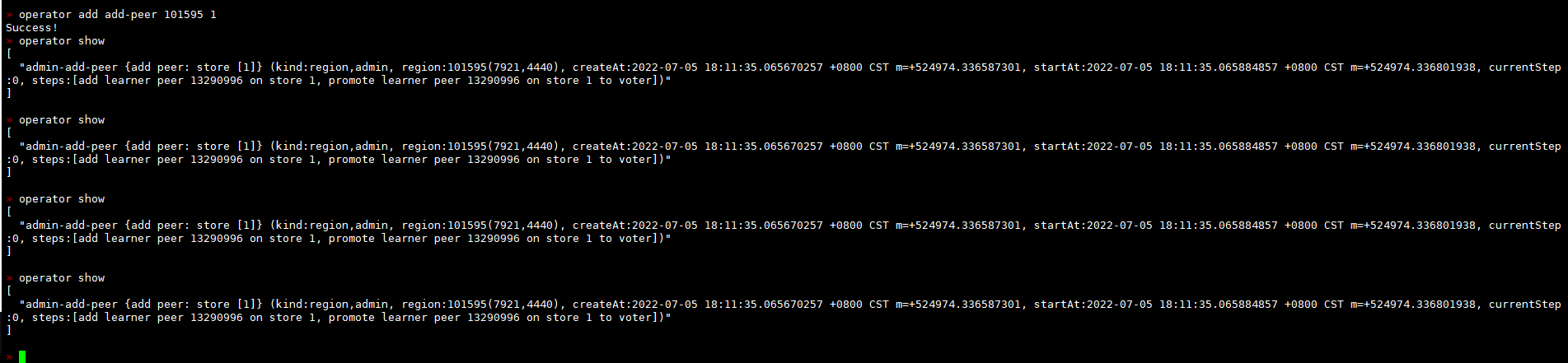
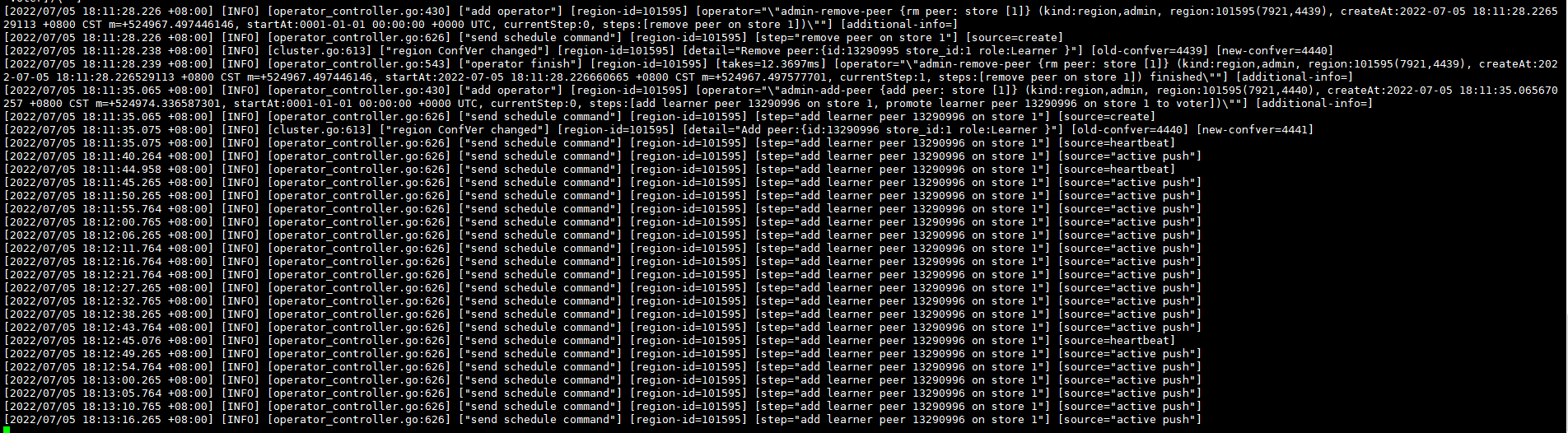
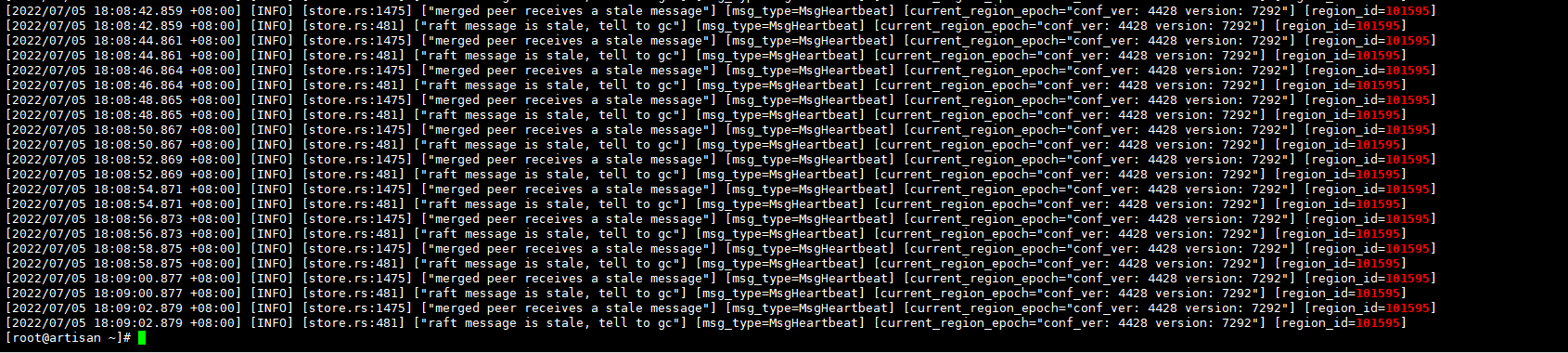
时间不匹配是因为刚才尝试operator remove后重试了下
应该是 operator add remove-peer 吧,remove 掉 down 的 peer,然后 pd 自动补齐。
remove-peer很快,因为之前有等了很久peer数还是2的经验,所以尝试了手动add-peer
这是add-peer最终失败的日志:

那我就先不管remove down peer后peer总数为2的region了
目前清理之后,miss-peer的有14个,看了下应该都是刚才remove-peer之后还未自动补全的,peer数都是2。
down,pending,empty状态的region都没了现在。
重启tidb之后,tidb的日志还是和之前一样报region not found for key \"mBootstra...这个错误。
tikv日志没什么变化pd日志从tidb关闭开始就持续输入如下:


现在自动补齐了吗?
先确认有没有用这个数据目录的 tikv 在 running,如果没有,可以删 LOCK。
region not found for key "mBootstra\xffpKey 我再看一下