【 TiDB 使用环境】生产环境
【 TiDB 版本】5.1.0
【遇到的问题】
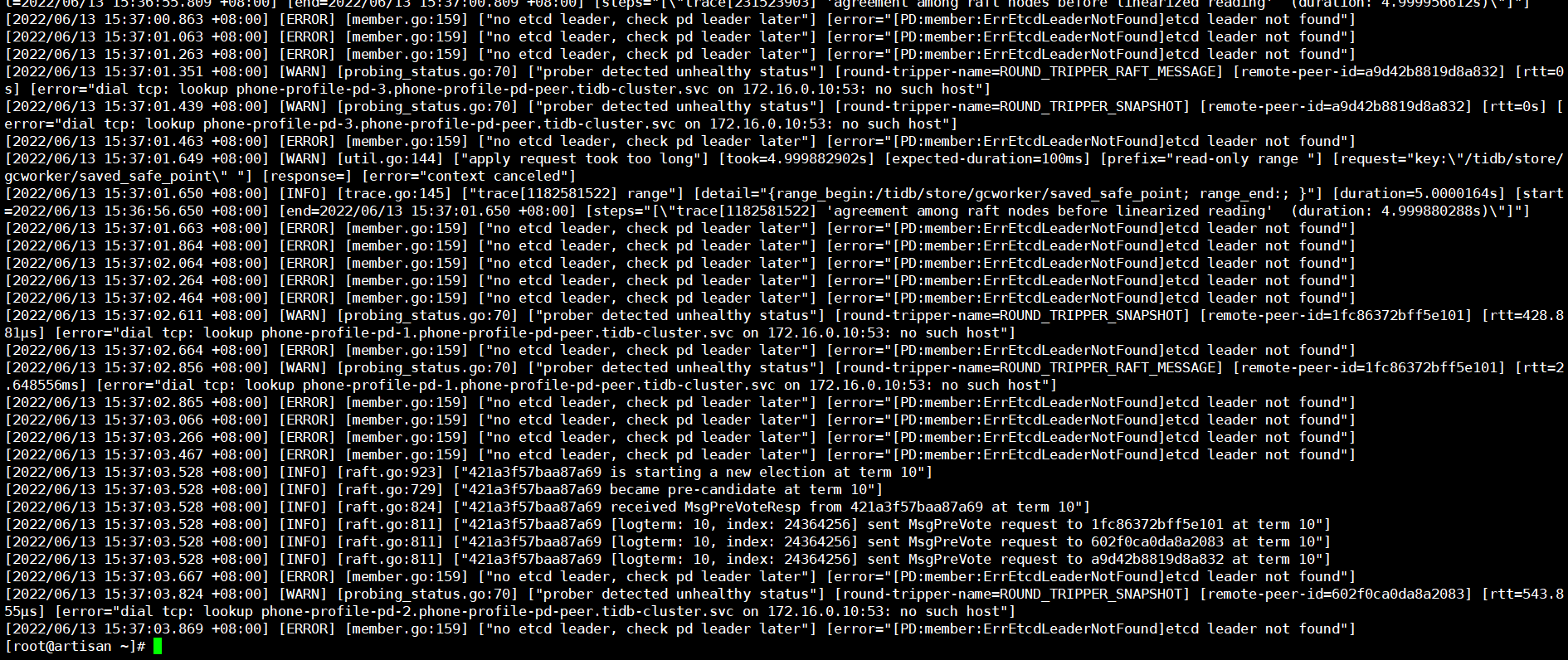
3副本pd,其中1个pod由于存储问题挂掉起不来,其他pod无法承接leader角色
【复现路径】
【问题现象及影响】
请问此时应当如何恢复pd leader呢?
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.1.0
【遇到的问题】
3副本pd,其中1个pod由于存储问题挂掉起不来,其他pod无法承接leader角色
【复现路径】
【问题现象及影响】
怎么是2天前的,现在好了吗看这个:https://docs.pingcap.com/zh/tidb/stable/pd-control#member-delete--leader_priority--leader-show--resign--transfer-member_name
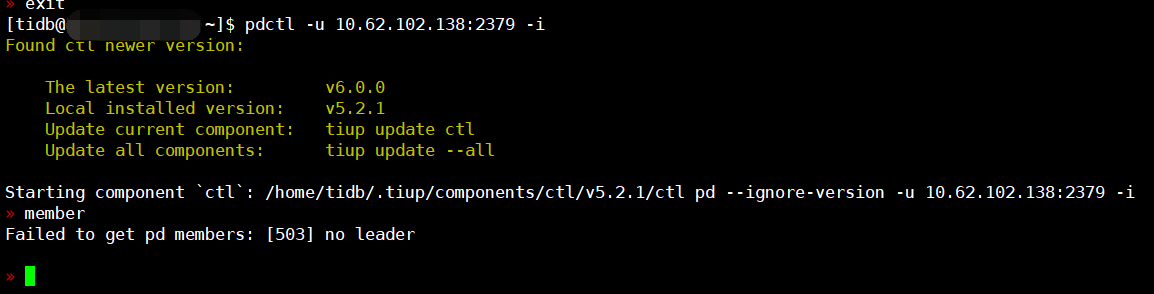
没有leader,所以目前所有指令都返回:[503] no leader …
member leader resign 这个命令也不行对吧
是的 resign和transfer都返回:[503] no leader
正常应该会自动转移的,咱们可以删除这个 pod(缩容),不过你有没有检查 其他2个节点的日志啊(有什么信息?)-- 另外,咱们这是生产环境?业务没有影响吗?
可以先扩容一台,再缩容一下这个,先解决有问题的 pod 吧,看 etcd leader 都没选出来(tiup ctl 有 etcdctl ,可以看看里面的命令)
谢谢回复,使用etcdctl的move-leader也是无效的,官方有在kubernetes上直接新建pd集群接管服务的尝试吗,或者从tikv img文件中直接提取数据的办法。
终于有人有这个问题了,我之前一直有这个问题,但是后面也是没解决,最后是更改了部署方式,你是用什么方式部署的?
rke部署的,kube-controller-manager重启后pod状态恢复正常。
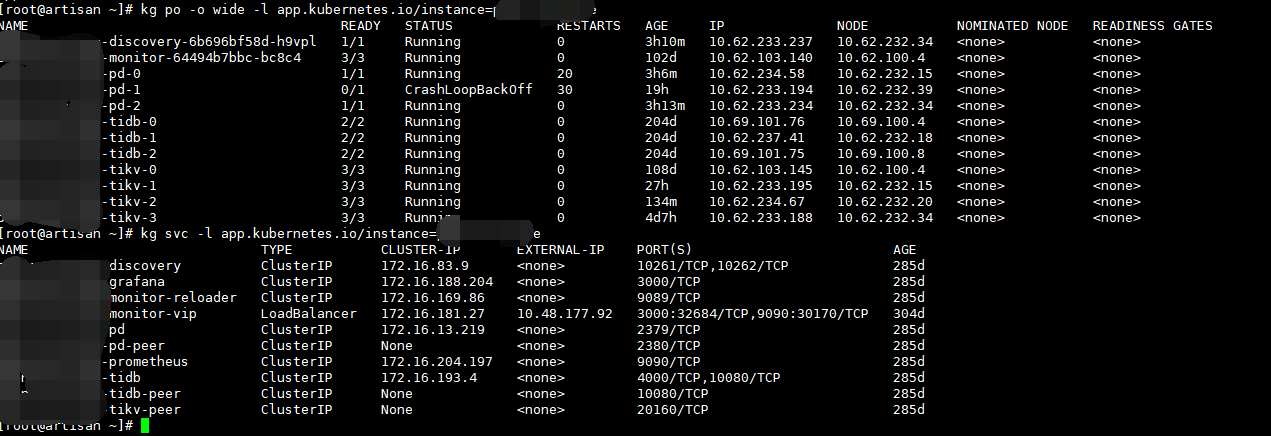
故障发生后3个pd pod还有2个是正常的,剩下一个失败,但这时候就无法选主。
后来把故障pd pod所在的pvc和pv全部清理掉了,现在恢复之后剩下的2个pd pod依然无法选主。
kubeadm部署k8s集群应该会更好些。
缩容扩容也不行吗,不能把这台有问题的 leader 删除吗?
目前修改pd replica没有效果,不会新增新的pd pod。
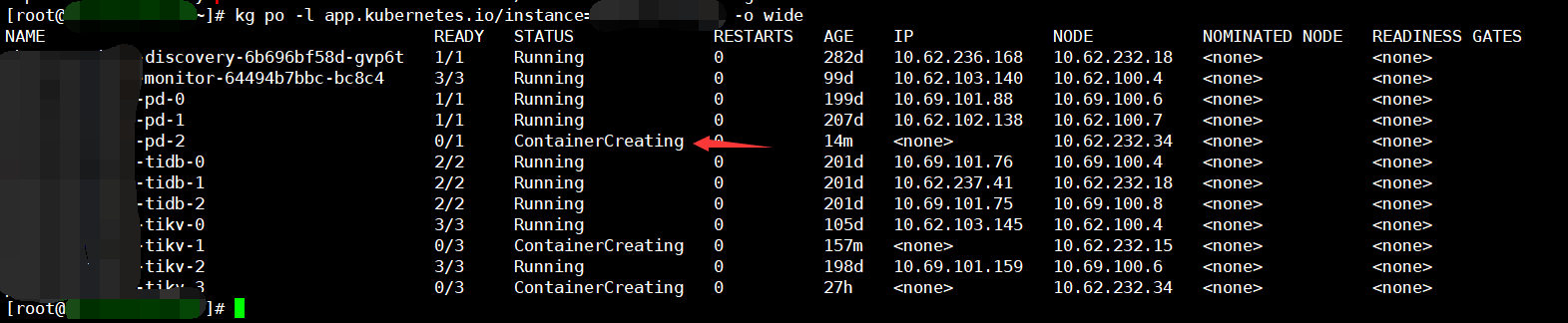
现在pd leader无法选主,怀疑是故障处理期间删除了pd-2的pvc和pv所致,这个pd-2可能是原来的leader,现在数据清掉了,所以看着是Running状态其实是在等从其他2个节点同步数据,而其他2个节点现在也无法决出leader。
至于最初时pd-2失联后pd-0和pd-1为何没有决出leader,现在已经无法知道原因了…
waiting for discovery service to return start args ... etcd server 是单独部署的吗?
我看 最后一张图的日志 leader 是选出来了, 但是 连不上 etcd
kuebctl get svc -o wide -n ${your_namespace}
kubectl get pods -o wide -n ${your_namespace}
图截全
不是 就是按官方文档在k8s部署的普通tidb集群
https://github.com/etcd-io/etcd/issues/9670
pd用的是embed etcd 你看下, pvc yaml贴下看看