为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
Cluster type: tidb
Cluster name: test-cluster
Cluster version: v4.0.9
SSH type: builtin
Dashboard URL: http://192.168.241.26:12379/dashboard
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
192.168.241.7:9093 alertmanager 192.168.241.7 9093/9094 linux/x86_64 Up /home/tidb/deploy/data.alertmanager /home/tidb/deploy
192.168.241.7:3000 grafana 192.168.241.7 3000 linux/x86_64 Up - /home/tidb/deploy
192.168.241.24:12379 pd 192.168.241.24 12379/12380 linux/x86_64 Up|L /disk1/pd/data.pd /disk1/pd
192.168.241.26:12379 pd 192.168.241.26 12379/12380 linux/x86_64 Up|UI /disk1/pd/data.pd /disk1/pd
192.168.241.49:12379 pd 192.168.241.49 12379/12380 linux/x86_64 Up /disk1/pd/data.pd /disk1/pd
192.168.241.7:9090 prometheus 192.168.241.7 9090 linux/x86_64 Up /home/tidb/deploy/prometheus2.0.0.data.metrics /home/tidb/deploy
192.168.241.26:4000 tidb 192.168.241.26 4000/10080 linux/x86_64 Up - /disk1/pd
192.168.241.7:4000 tidb 192.168.241.7 4000/10080 linux/x86_64 Up - /home/tidb/deploy
192.168.241.11:20160 tikv 192.168.241.11 20160/20180 linux/x86_64 Up /disk1/tikv/data /disk1/tikv
192.168.241.53:20160 tikv 192.168.241.53 20160/20180 linux/x86_64 Up /disk2/tikv/data /disk2/tikv
192.168.241.56:20160 tikv 192.168.241.56 20160/20180 linux/x86_64 Up /disk1/tikv/data /disk1/tikv
192.168.241.58:20160 tikv 192.168.241.58 20160/20180 linux/x86_64 Up /disk1/tikv/data /disk1/tikv
192.168.241.59:20160 tikv 192.168.241.59 20160/20180 linux/x86_64 Up /disk1/tikv/data /disk1/tikv
192.168.241.60:20160 tikv 192.168.241.60 20160/20180 linux/x86_64 Up /disk1/tikv/data /disk1/tikv
192.168.241.61:20160 tikv 192.168.241.61 20160/20180 linux/x86_64 Up /disk1/tikv/data /disk1/tikv
Total nodes: 15
【问题描述】
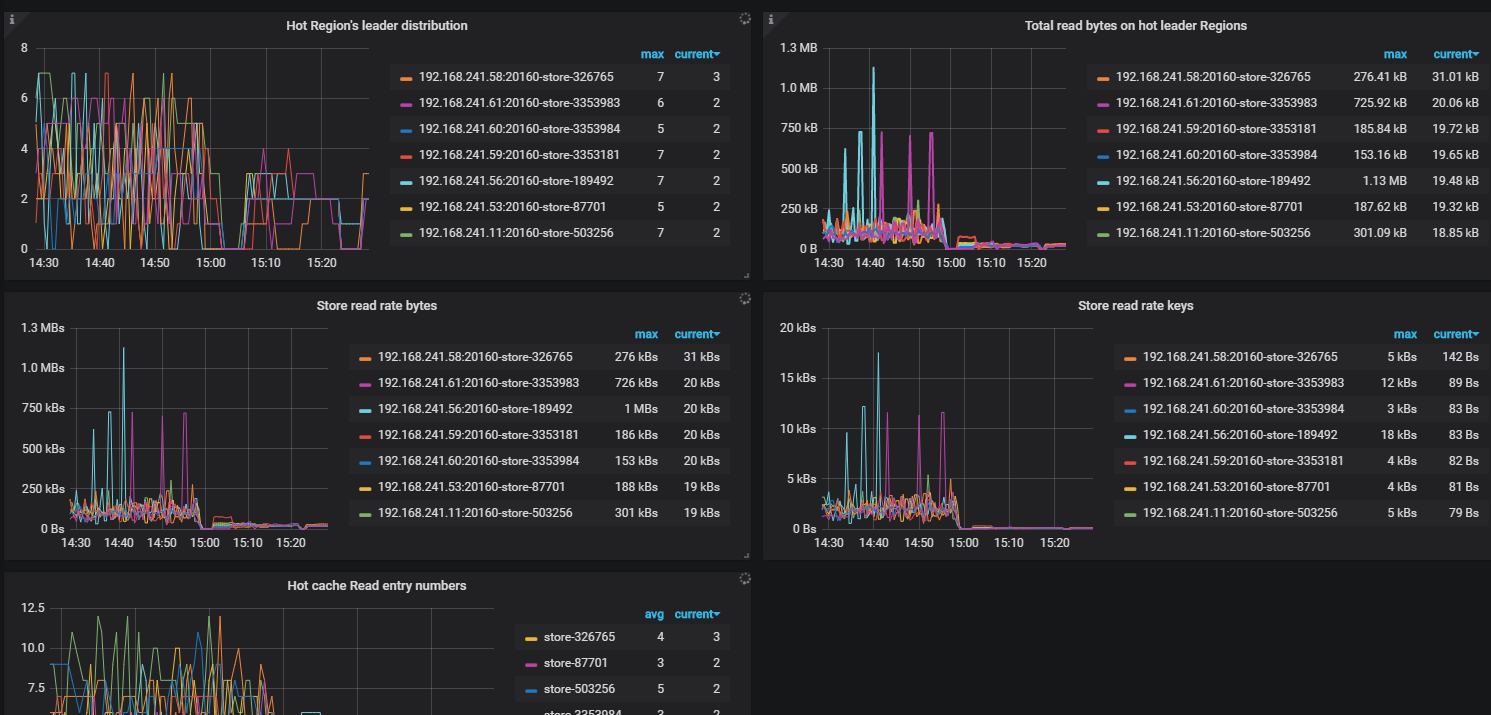
由于性能下降所以增加kv节点来提升性能。
4天前一次性将kv节点由4个增加到7个。今天进行了sysbench测试,发现性能较之前下降不少。
sysbench --config-file=config oltp_point_select --tables=16 --table-size=1000000 run
无其他负载的状态下,之前QPS可以3000,目前测试只有700.
各节点的leader处于平衡状态,region peer还没有平衡(缓慢均衡中),测试时的热点也比较均匀。