foxchan
(银狐)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
2)tikv 单独配置了这个参数,之前在4.0.7 跑一直稳定
[storage.block-cache]
capacity = “50GiB”
3)grafana 监控看到,19号进行的升级,后面的内存趋势,都是tikv集群重启后
4)tikv日志
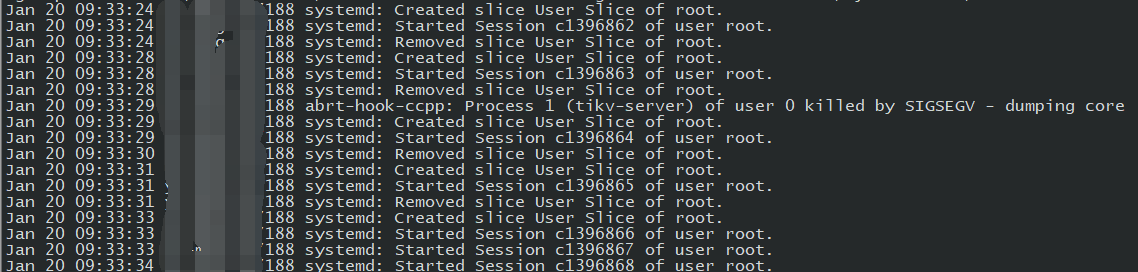
系统日志
发现有kill信息
heming
(何明)
2
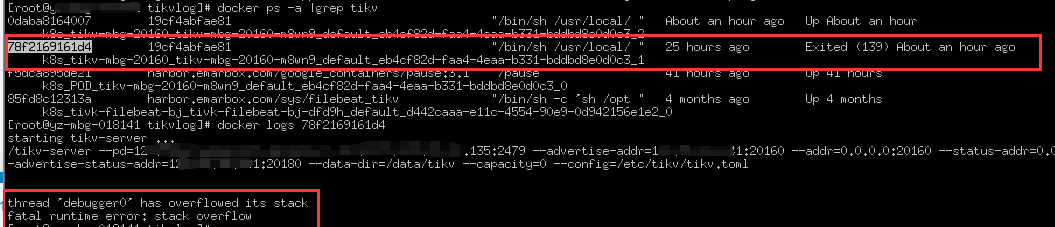
docker 异常退出日志
thread ‘debugger0’ has overflowed its stack
fatal runtime error: stack overflow
小王同学
4
你这边提供的内容都不是很详细,麻烦按照下面内容详细提供下,多谢。
1.按照上面的消息,提供升级 前后的 tikv-details 的监控,标明升级时间,最好前后监控 12 h 左右
2.提供 tikv.log、/var/log/messages、以及找一下 tikv_stderr.log,麻烦提供下文本内容,重启前半个小时
3.集群部署方式是怎样的? TiUP 还是 operator ? 那麻烦提供下具体的版本
foxchan
(银狐)
5
2/没有配置tikv_stderr.log.
3、部署方式是自己写的yaml, tikv是daemonset 模式部署
tikv.log.gz (2.4 MB) messages (221.3 KB)
小王同学
6
升级 tidb 为 4.0.10 后,观察下集群是否还会存在 tikv 异常重启的情况。
foxchan
(银狐)
7
升级 db 升级为4.0.10后,tidb 报错,创建新的tug 升级tidb v4.0.10后,TiDB_server_panic_total
现在降级到4.0.8,tidb 正常了
请问一下是否用的 tidb operator 进行容器管理。
foxchan
(银狐)
10
今天tikv 没有重启
当前组件版本:pd v4.0.10
TIKV v4.0.10
tidb v4.0.8
好的,能麻烦再取一份 tikv os message 日志信息吗
foxchan
(银狐)
12
messages.gz (186.6 KB)
今天的message,并无dump 日志
能否帮我确认一下,升级后 tikv 自动重启了多少次。 我看内存的监控是 :20 号 21 号 tikv 重启时间都是在 09:33:00 左右是吗?
cfzjywxk
(cfzjywxk)
15
@foxchan 你好,请问第一次发生重启,是所有 tikv 节点在同一个时间,都发生了重启么?
cfzjywxk
(cfzjywxk)
19
集群除了 pd tidb tikv 之外,还有部署哪些其他组件呢?
cfzjywxk
(cfzjywxk)
20
@foxchan
可否帮忙在本地 gdb 解一下这个 core 文件,我本地环境不太一样有些信息不完整。
操作步骤:
gdb ./bin/tikv-server core-dump-file
info threads
在结果集里面找一下名字叫做 “debugger0” 的 thread,类似,找到最左边的这个编号
* 107 Thread 0x7faac89d8700 (LWP 2455) "debugger0" futex_wait_cancelable (private=<optimized out>,
expected=0, futex_word=0x7fab2b292778) at ../sysdeps/nptl/futex-internal.h:183
然后切换到该线程(按上面的来看就是 107)
thread xxx
再执行这个命令展开 backtrace
bt
然后贴下结果