还有tiflash v4.0.10, 这个报错是pod ,使用的是官方镜像。alphie linux,编译了gdb,但是运行不了。还有别的方法吗
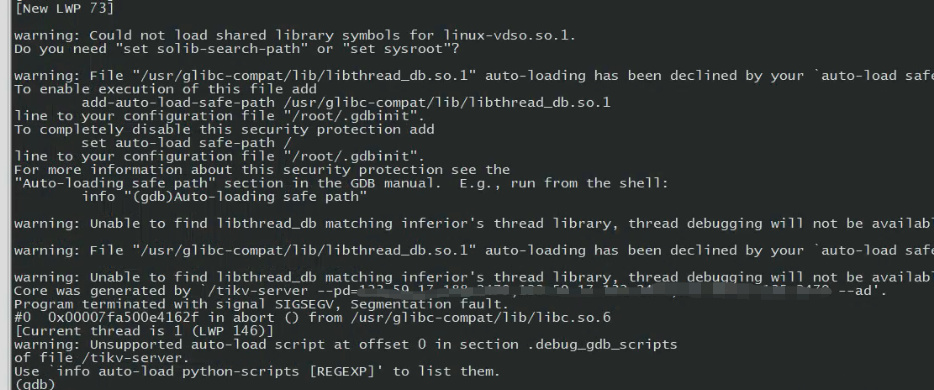
从报错信息来看,是 tikv http status 请求执行的 thread 因为 stack overflow 导致 tikv 进程被终止。v4.0.7 上没有问题的话,可能是之后的修改有影响,但目前暂时还不确定到底是哪一个后台 http 请求触发了什么问题。
目前可以尝试把 stack size 调大
ulimit -s
或者
ulimit -a
可以查看环境的 stacksize 大小,调大到如 20MB 试试,然后再观察一下是否会 stack overflow。
另外 alpine linux 的 default stack size 似乎很小只有 80 KB,可能跟这个配置也有关系
容器当前ulimit 设置,这些都是默认的
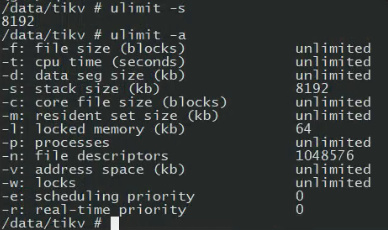
如果我要改这个,要看docker 和k8s 是否支持。还需要重构官方镜像吗?
我先手动改几个pod看看,明天会不会重启
咦这个是已经改过了么? 好像跟 alpine linux 说的默认配置不太一样
嗯如果好改且允许的话,可以改大一下试试。
如果只是一些 stack object 变大了的话,改大估计能解决,是有如递归死循环之类的问题的话,应该还是会挂掉,具体原因还需要再查一下。
感谢反馈
我先手动改了,明天观察下看看。三套集群,就这一套 tikv 同时挂, 另外2套集群 是在 tikv 升级的过程中挂掉。先用这个排查吧。多谢回复
昨天修改了ulimit -20480, 今天下午4.0.10 版本tikv 还是会同时重启,4.0.8版本tikv 没有问题
@foxchan 感谢反馈。这样看确实是有问题,这个环境可以部署 debug 版本的 binary server 么?如果可以我们可能需要出一个 binary debug 版本的 tikv-server,进一步追踪重启前发生的操作。
你们可以提供一下 binary debug 版本的 tikv-server 我们替换其中一两个节点看看
经排查,该问题是 4.0.9 以及 4.0.10 版本的 bug
触发条件:
访问 dashboard,或通过 sql 访问 hardware 系统表触发该问题。该帖子触发是由于打开了 tidb telemetry 功能每 24h 搜集一次统计信息,https://docs.pingcap.com/zh/tidb/stable/telemetry 每次搜集导致所有 tikv node stackoverflow 重启
当前问题解决方式:关闭 tidb 的遥测功能,后续 4.0.11 中会修复该问题。
奇怪 我们也是 v4.0.9 从来没重启过
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。