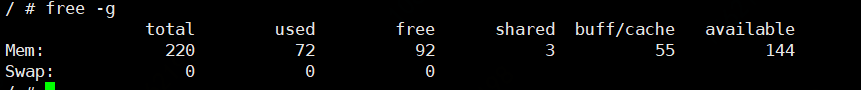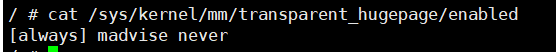为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.8
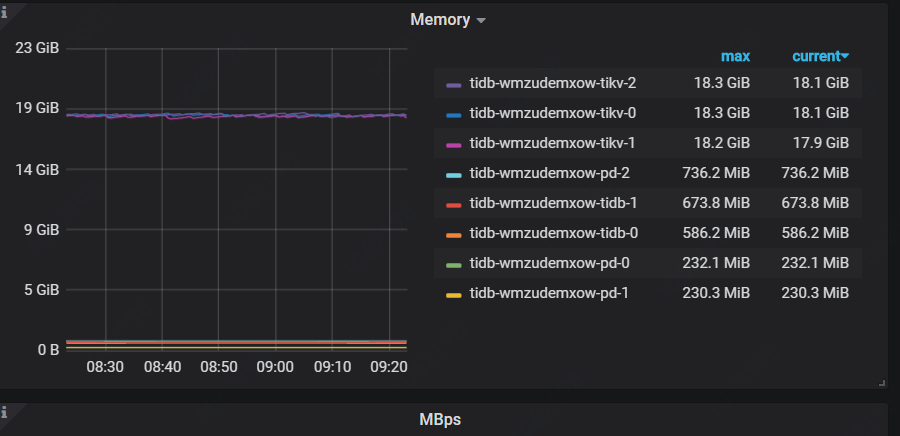
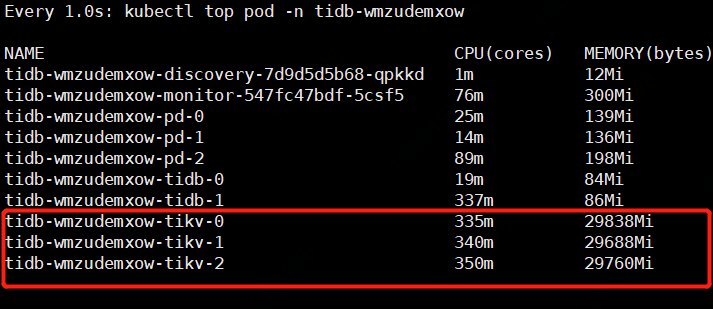
- 【问题描述】:grafana监控显示用了19G,kubectl top显示用了29G
补充答案:
kubectl top pod 得到的内存使用量,并不是cadvisor 中的container_memory_usage_bytes,而是container_memory_working_set_bytes,计算方式为:
- container_memory_usage_bytes == container_memory_rss + container_memory_cache + kernel memory
- container_memory_working_set_bytes = container_memory_usage_bytes - total_inactive_file(未激活的匿名缓存页)
container_memory_working_set_bytes是容器真实使用的内存量,也是limit限制时的 oom 判断依据
单tikv数据才40G左右,怎么就占那么大内存,从哪里看都哪些组件占了?
yilong
(yi888long)
5
那从grafana开始查吧,看看监控的是哪里的数据。 参考这个文档看看能找到吗?多谢
直接通过curl的tikv1的20180端口拿到的。这个数据就是不准的。
yilong
(yi888long)
7
请问您看的是哪个监控项中的 memory? 可以看看 over-view 监控项的 tikv memory 和 system memory 有没有哪个是你想要的监控项
over-view下的tikv memory是17G左右,一样的。system memory没找到。
yilong
(yi888long)
9
好的,有没有其他系统也使用Prometheus的? 看下 Prometheus 是不是取 pod 的内存不准呢?
就是k8s的operator带的grafana,因为经常是tikv oom了,但是看监控,内存还不到分配的一半。
请问有开 THP 吗?它的计算方式是拿 procfs stats 里的 rss,再乘以 page size
这个看样子是开着的。
我们监控里 Prometheus 统计的内存是这样的:
- 从 /proc/self/stats 里获取 rss 字段,是进程实际在内存中使用占用的页数
- 拿这个页数乘以 libc 中给出的 PageSize,计算出字节数
这个数字按理来说应该是比较准确的。
我猜测可能 thp 会影响最终计算出来的字节数的准确性,不过没有验证成功。。。
另外在生产环境中出于其他方面的考量我们也是不建议开启 thp 的,详细的情况可以参考这篇文章 https://pingcap.com/blog-cn/why-should-we-disable-thp/
大概说下我们的环境: 物理机上跑虚机,虚机作为k8s的node。 在k8s里面创建tidb集群。这种情况下几乎都是不准的。tikv拿到的几乎是实际kubectl top看到的一半多一些。
另外默认用operator跑起来的集群,tikv的内存使用量占limit百分比是多少? 我们的环境,刚起来的tikv的pod过不了半小时通过kubectl top看都能达到分配的limit的90%以上。
tikv 默认会设置一个内存大小 40% 的 rocksdb block cache。
看了下之前的回复是说 free -g 看到的是 220G?建议手动配置一下 storage.block-cache.capacity
另外用 top node 的话看到的内存是和监控上一致的吗?我看了一下 top node 查的也是 rss,而 top pod 查的是 cgroup 的 inactive files。
方便的话也可以看一下/proc/${tikv-pid}/smaps,这里面的内存大小应该比 rss 要稍微准确一些。
“storage”: {
“data-dir”: “/var/lib/tikv”,
“gc-ratio-threshold”: 1.1,
“max-key-size”: 4096,
“scheduler-concurrency”: 524288,
“scheduler-worker-pool-size”: 4,
“scheduler-pending-write-threshold”: “100MiB”,
“reserve-space”: “2GiB”,
“block-cache”: {
“shared”: true,
“capacity”: “14417MiB”,
“num-shard-bits”: 6,
“strict-capacity-limit”: false,
“high-pri-pool-ratio”: 0.8,
“memory-allocator”: “nodump”
}
}
看这个配置,storage.block-cache.capacity没200G。
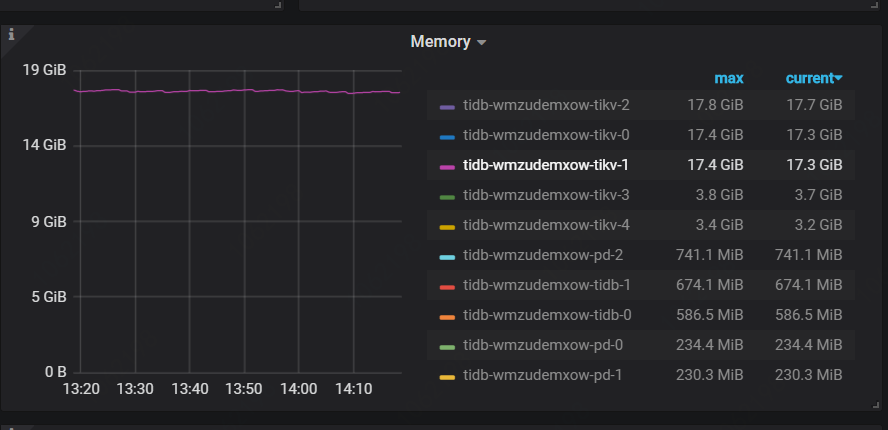
现在是这样的:
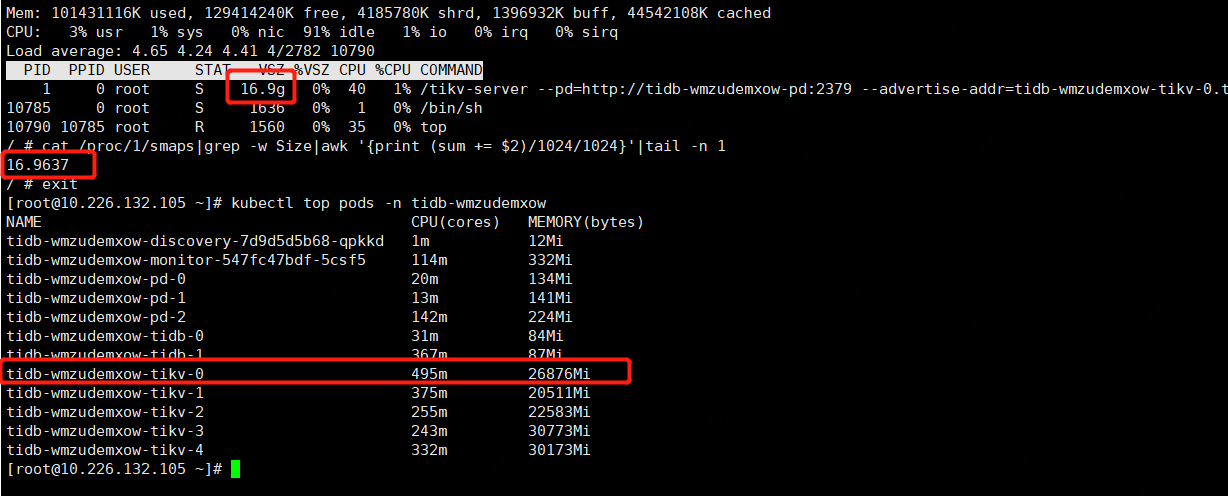
进入docker中,top和cat /proc/1/smaps算出来的是一样的,都是16.9G
通过kubectl top 获取pod的内存使用量是26.2G
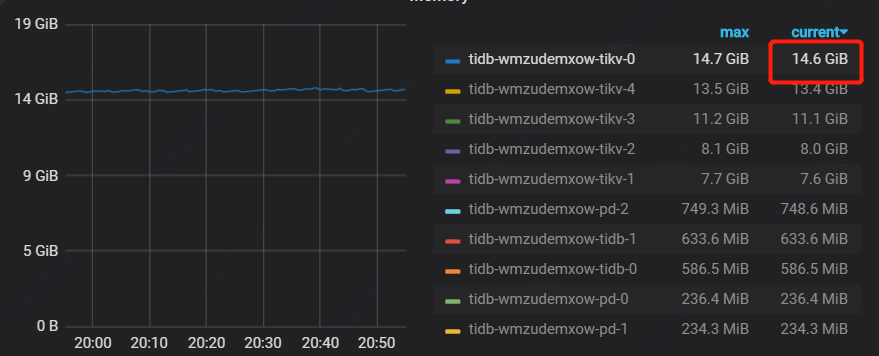
通过grafana看到的是14.6G
三个地方看到的都不一样。关键是k8s是以pod的内存占用oom的。
多余的内存怎么看哪里占用了?关键差别在pod外面和pod内部实际进程使用。
了解,那总结来看内存误差应该是由于 kubectl top 的误差和 linux rss 的误差结合导致的。
关于 oom 的问题,我们在设置了 block cache 大小之后还会有吗?