【 TiDB 使用环境`】生产环境
【 TiDB 版本】5.2.1
【遇到的问题】tidb访问非常慢,但看集群概况,看起来比较正常
【复现路径】上午访问非常慢,然后关闭应用后重启了整了tidb集群,还是访问非常慢,排除慢查询的问题
【问题现象及影响】
当前延迟时间很长,一般都是几十毫秒的,但现在都是1秒以上
截图如下: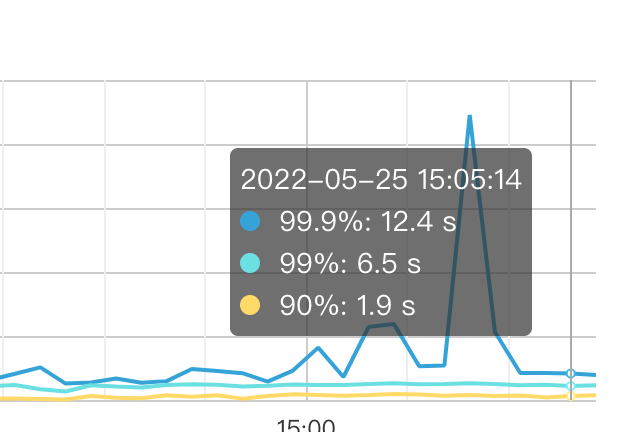
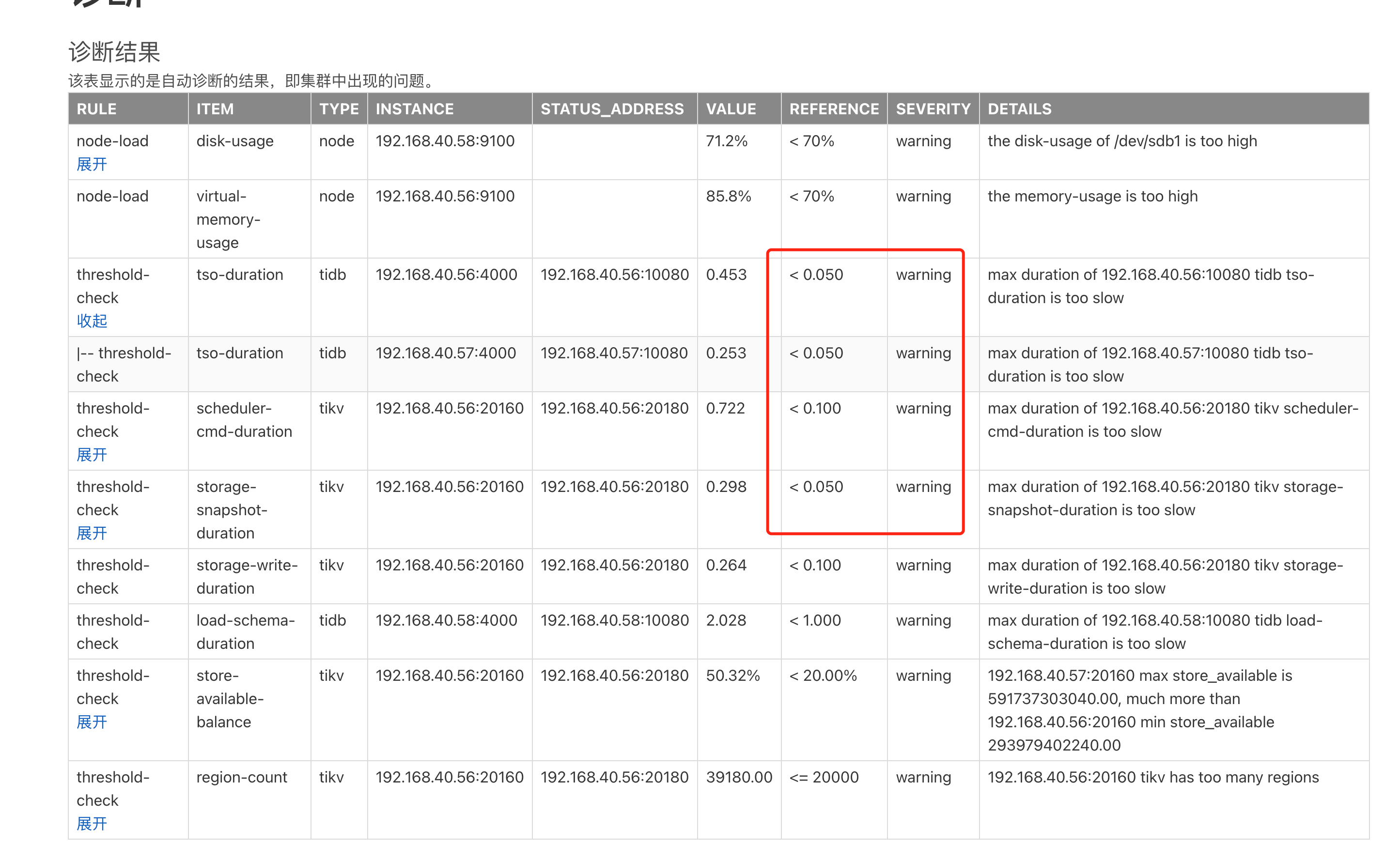
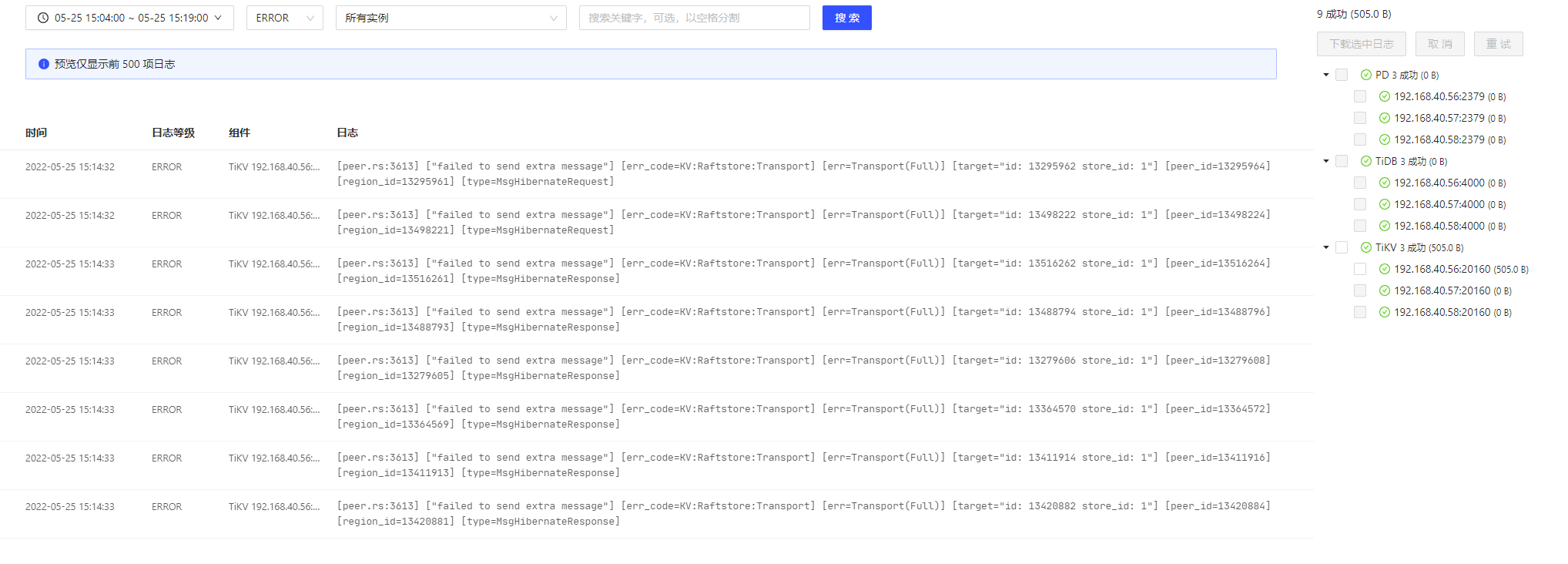
同时我们这边进行了集群诊断,截图如下:
发现一个异常:
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
Min_Chen
(Make the world more reliable)
2
麻烦导出一下 grafana 监控数据,通过工具 https://metricstool.pingcap.com/#backup-with-dev-tools
需要导出的面板:TiKV Detail、Overview、PD、TiDB、Disk Performance
1 个赞
Min_Chen
(Make the world more reliable)
6
PD 的监控请选到 leader 后导出,否则无数据。
另外通过 Clinic 收集一下集群信息,辅助排查。
Min_Chen
(Make the world more reliable)
9
57 58 的 disk performance 和 TiDB 提供一下
Min_Chen
(Make the world more reliable)
11
初步查看监控,集群不慢,只有 .99 的 sql 比较慢 达到 4~8s,麻烦提供慢查询日志,来进一步排查。
看起来都是写入操作,特别慢,平时都是毫秒级,现在要几十秒
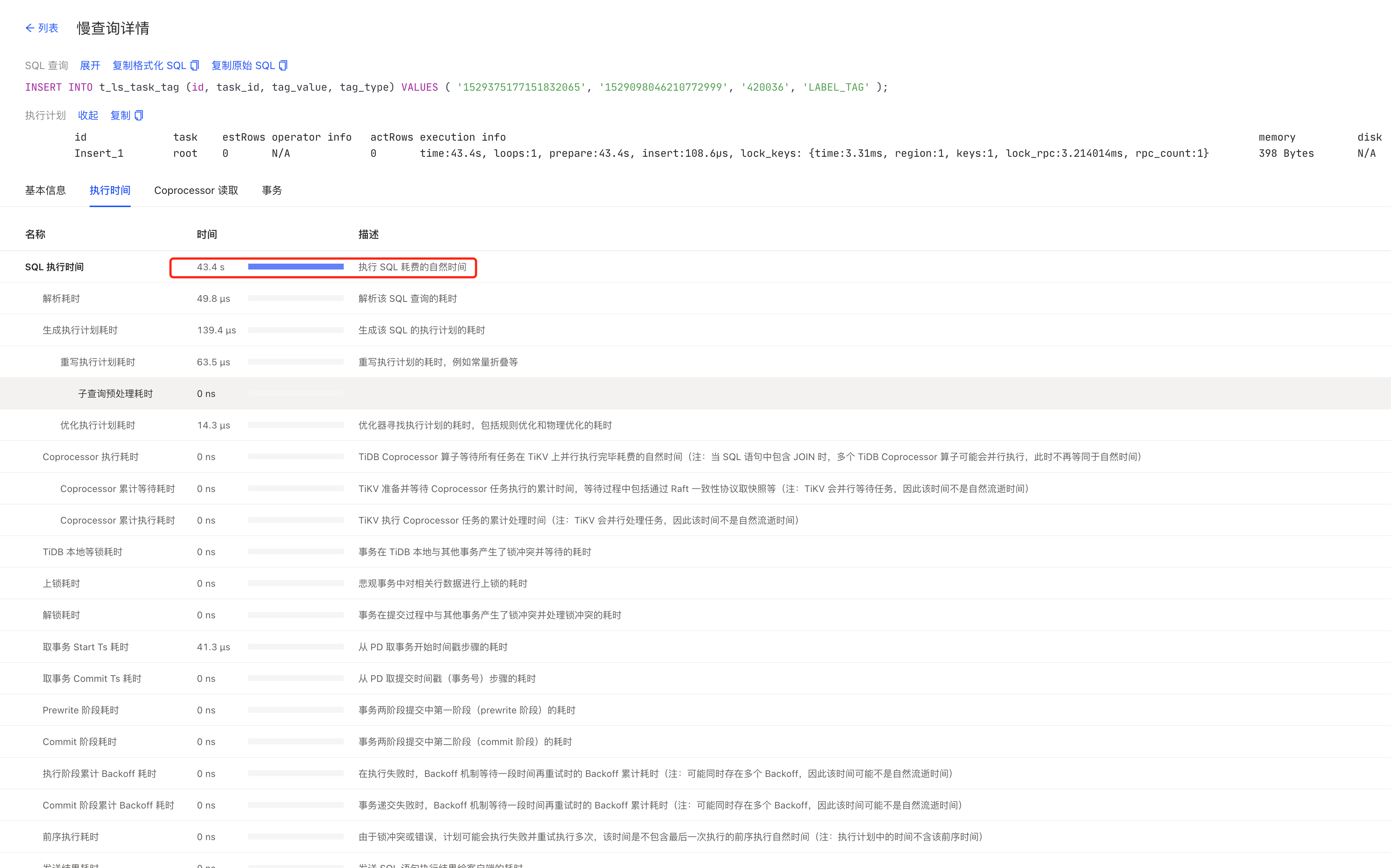
一个写入SQL,需要40多秒,但你们这边步骤没太看清楚:
id task estRows operator info actRows execution info memory disk Insert_1 root 0 N/A 0 time:43.4s, loops:1, prepare:43.4s, insert:108.6µs, lock_keys: {time:3.31ms, region:1, keys:1, lock_rpc:3.214014ms, rpc_count:1} 398 Bytes N/A
主要时间花在prepare了
问题已经解决了,原因是一个SQL里面的in有几十万的数量,导致整个集群出问题。关键这个SQL一直在执行,集群重启还自动恢复执行,在慢日志里面还慢不到。
这个看能不能加某些机制,来避免这种问题发生。