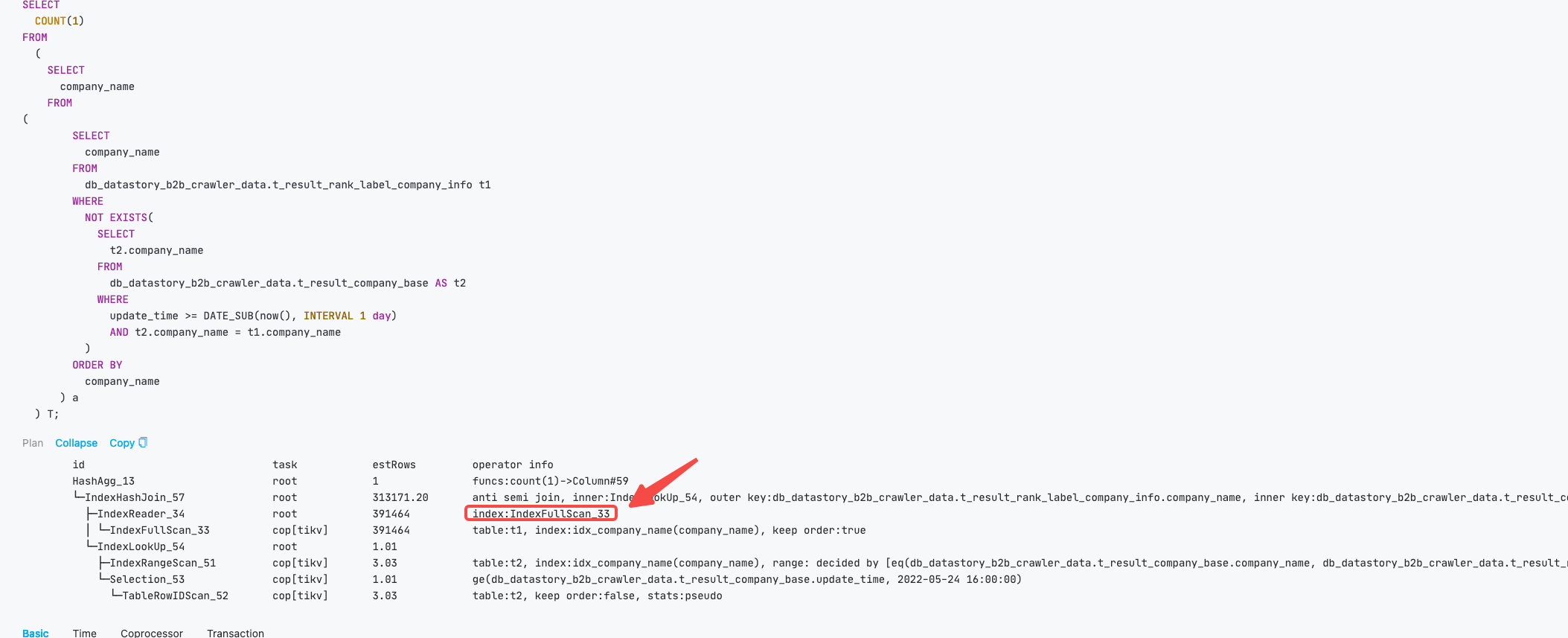
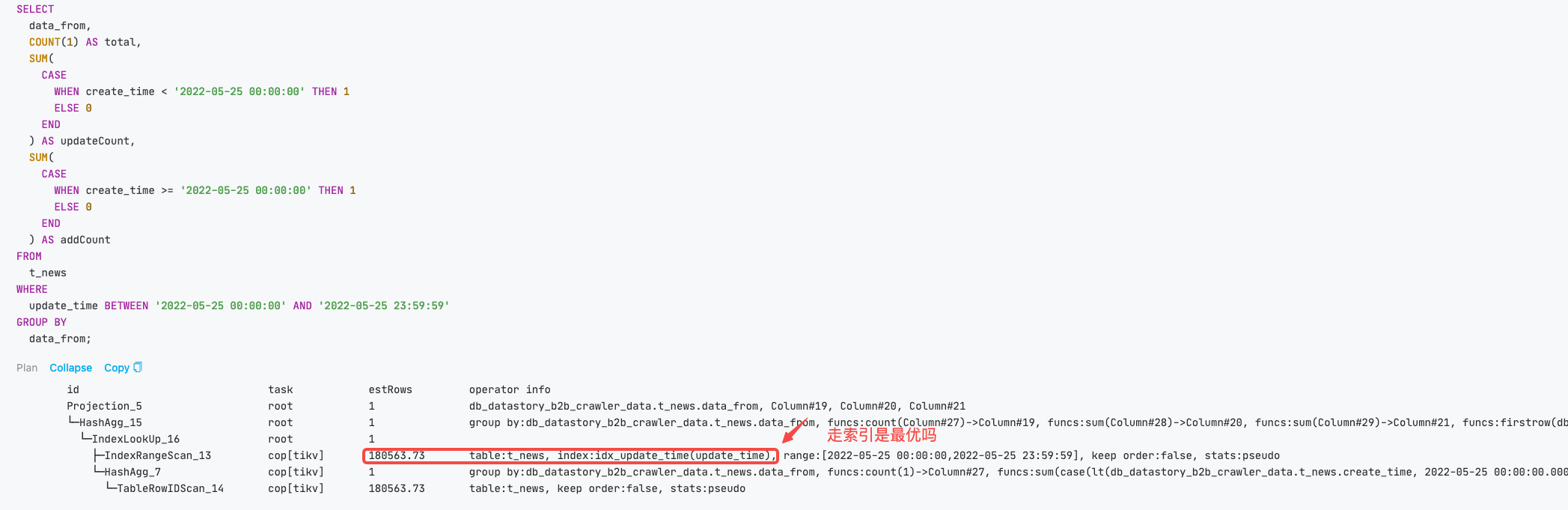
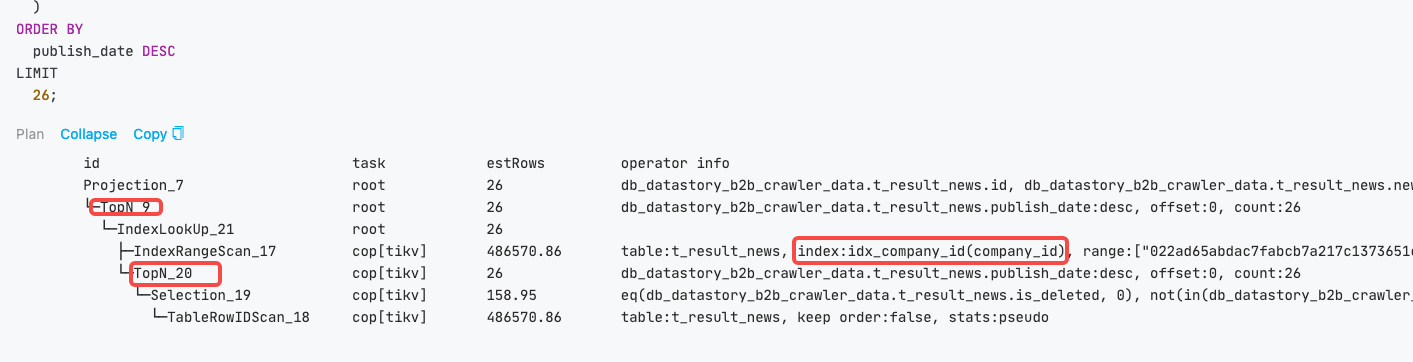
麻烦发下表结构,
t_ls_task_tag
麻烦发下表结构,
t_ls_task_tag
CREATE TABLE t_ls_task_tag (
id bigint(20) NOT NULL AUTO_INCREMENT,
task_id bigint(20) DEFAULT NULL COMMENT ‘task id’,
tag_value varchar(50) DEFAULT NULL COMMENT ‘标签值’,
tag_type varchar(100) DEFAULT NULL COMMENT ‘标签类型’,
PRIMARY KEY (id) /*T![clustered_index] CLUSTERED */,
KEY idx_task_id (task_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin AUTO_INCREMENT=1532048697866573107 COMMENT=‘标注任务标签关联表’;
麻烦你看看
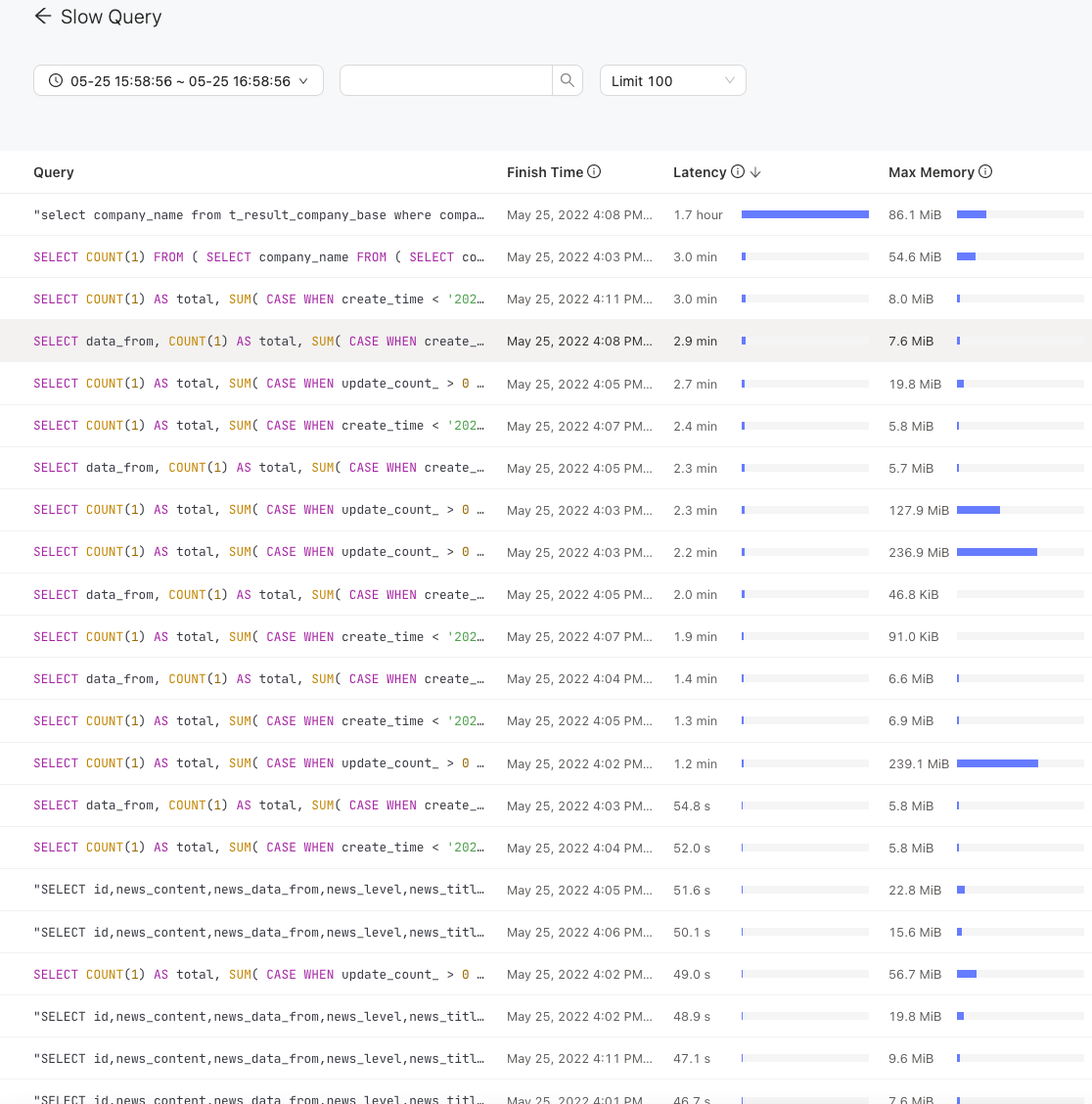
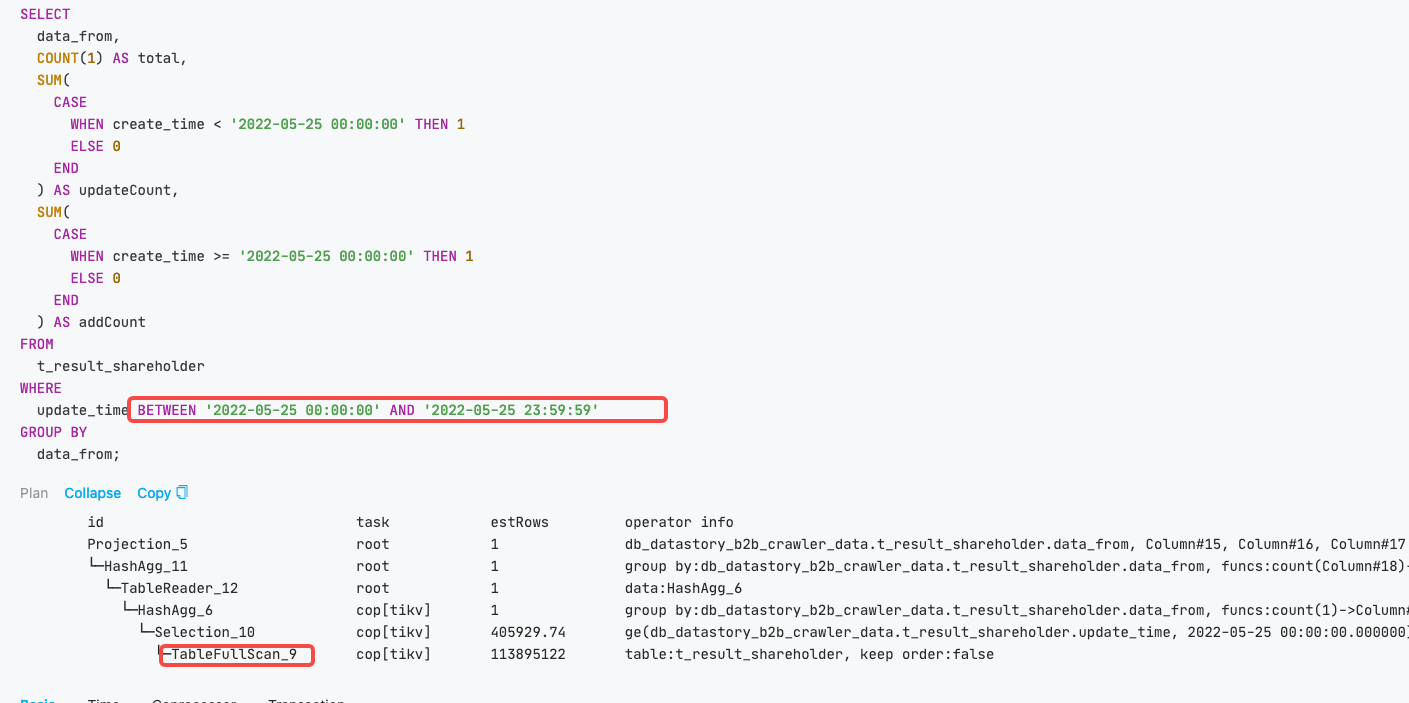
比较好奇问题是否真的解决了,显然现在集群性能不是理想的;10~20 qps 的 SQL Duration 99线达到 7s,并且 TiDB server 的请求 CPU 消耗不均衡;
再者从 slow_query 执行时间倒排取前 100 条看都在 10s 以上,初看下来很多 SQL 可调 (如有泄露业务信息,请及时联系我删除) ;
说回来,如果问题真的解了。没执行完的 SQL 不会记录在 Slow Log 中,可以通过 show full processlist 查看正在执行的 SQL。再者,如果像您说的重启后会恢复执行的情况,对 TiDB 而言是数据库重启后是不会主动恢复某条 SQL 的,也就是说来自于业务。但是执行这么长时间的 SQL 即使执行失败也会记录在 slow log 中,可以翻找 succed = 0 的语句,一定程度察觉该问题。(PS :单纯用 Dashboard 有的版本会漏掉一些 SQL,最好去 information_schema.cluster_slow_query 中,或 tidb_slow_query.log 中查)