foxchan
(银狐)
1
【 TiDB 使用环境`】生产,k8s
【 TiDB 版本】v5.3.1
【遇到的问题】
ticdc owner 无故down掉,频繁重启,集群节点不能同步数据。 下掉异常节点后,集群可以同步。但是无法添加新的cdc节点, 新节点报错 和旧owner 报错一致,怀疑是写etcd 异常
【复现路径】owner 自己挂掉,可以频繁重启 owner 试试,看 会不会导致 etcd txn 异常
【问题现象及影响】
【附件】
新加节点cdc log,
ticdc.log.gz (819.2 KB)
上个tug ticdc同步异常owner降级为worker 重新选owner之后 还是不能继续同步
foxchan
(银狐)
3
重新找机器添加ticdc 节点,还是一样
ticdc节点 到pd网络无问题
新加节点 debug日志
ticdc.log.gz (1.4 MB)
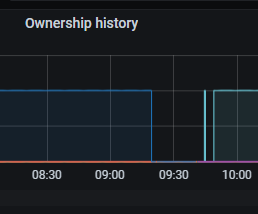
监控图 添加新节点后 集群异常没有owner了, 下掉异常节点后,集群恢复

owner log
owner.log.gz (2.9 MB)
Min_Chen
(Make the world more reliable)
5
从日志中未看出异常,建议看一下原先的 owner 节点的日志,看下为啥丢掉 owner 了
foxchan
(银狐)
6
也不正常啊,新的cdc节点 加不上,每次都报错。集群不同步数据,我要把异常节点下掉 才正常,上个回答 附件 有老owner的日志
Min_Chen
(Make the world more reliable)
7
还是和 etcd 通信不太正常,麻烦所有 cdc 节点开 debug 查看日志。
另外可以尝试使用 【SOP 系列 22】TiDB 集群诊断信息收集 Clinic 使用指南&资料大全 讲日志、监控、拓扑一并收集上来,有助于我们帮忙分析。谢谢。
foxchan
(银狐)
8
clinic 只支持 tiup,我是k8s,有k8s的吗
另外,我这边有定时重启owner 的脚本。 如果发现集群没有owner 就自动找个节点重启。 可能是这个导致etcd txn faild。
根据监控图,owner的选举时间过长,触发了我的监控脚本
system
(system)
关闭
9
该主题在最后一个回复创建后60天后自动关闭。不再允许新的回复。