heming
(何明)
1
【 TiDB 使用环境】生产 【 TiDB 版本】 5.3.1 【遇到的问题】 ticdc owner 出问题 ,降级为worker ,之后 重启问题owner 自动重新选举了owner ,但是还是不能继续同步 【复现路径】做过哪些操作出现的问题`
【问题现象及影响】
同步停了2个小时了 , 做个的操作就是 重启 ticdc owner。 pause / resume task 都没有恢复 。
【附件】
-
相关日志、配置文件、Grafana 监控(https://metricstool.pingcap.com/)
-
TiUP Cluster Display 信息
-
TiUP CLuster Edit config 信息
-
TiDB-Overview 监控
-
对应模块的 Grafana 监控(如有 BR、TiDB-binlog、TiCDC 等)
-
对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。CROSS-TiCDC_2022-05-19T03_10_28.603Z.zip (1.2 MB)
muliping
(Muliping)
2
1 任务信息看一下
cdc cli changefeed list --pd=http://10.0.10.25:2379
2 owner的日志也要发一下。
heming
(何明)
3
[root@yz-mbg-017012 cdc]# cdc cli changefeed list --pd=http://xx.xx.17.37:2479 | more
[
{
“id”: “cbd-user-behavior-analysis-task”,
“summary”: {
“state”: “normal”,
“tso”: 433303111049936914,
“checkpoint”: “2022-05-19 08:29:52.909”,
“error”: null
}
},
{
“id”: “cbd-user-behavior-analysis-task-ht”,
“summary”: {
“state”: “normal”,
“tso”: 433303111049936914,
“checkpoint”: “2022-05-19 08:29:52.909”,
“error”: null
}
}
]ticdc20220519.log.gz (5.6 MB)
heming
(何明)
4
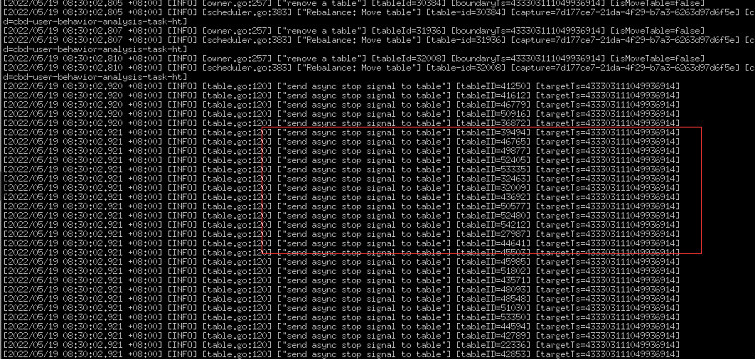
出问题时大量的
[2022/05/19 08:29:57.721 +08:00] [INFO] [owner.go:257] [“remove a table”] [tableId=49477] [boundaryTs=433303111049936914] [isMoveTable=false]
[2022/05/19 08:29:57.721 +08:00] [INFO] [scheduler.go:383] [“Rebalance: Move table”] [table-id=49477] [capture=7d177ce7-21da-4f29-b7a3-6263d97d6f5e] [changefeed-i
d=cbd-user-behavior-analysis-task]
8:30 出现大量的 TS 就是现在停止的位置 433303111049936914
[2022/05/19 08:30:02.922 +08:00] [INFO] [table.go:120] [“send async stop signal to table”] [tableID=56990] [targetTs=433303111049936914]
[2022/05/19 08:30:02.922 +08:00] [INFO] [table.go:120] [“send async stop signal to table”] [tableID=31906] [targetTs=433303111049936914]
[2022/05/19 08:30:02.922 +08:00] [INFO] [table.go:120] [“send async stop signal to table”] [tableID=41372] [targetTs=433303111049936914]
heming
(何明)
5
最新ticdc owner日志 ticdc_newleader_49.log.gz (6.0 MB)
[2022/05/19 11:17:29.564 +08:00] [WARN] [region_worker.go:752] [“The resolvedTs is fallen back in kvclient”] [changefeed=cbd-user-behavior-analysis-task] [EventType=RESOLVED] [resolvedTs=433305745046634515] [lastResolvedTs=433305747078250552] [regionID=27706670]
这些告警不知道是不是问题核心
不知道是不是这个 bug https://github.com/pingcap/tiflow/issues/2867
heming
(何明)
7
怎么查下一个TSO ? 我把 starttso 改到下一个 tso ?
使用新的任务配置文件,增加ignore-txn-start-ts 参数跳过指定 start-ts 对应的事务。
跳过这个 433303111049936914 tso试试 ?
不知道会不会还有别的问题
foxchan
(银狐)
8
这个 cannot get rpcCtx, retry span 什么意思
[2022/05/19 12:32:53.510 +08:00] [INFO] [client.go:926] [“cannot get rpcCtx, retry span”] [changefeed=cbd-user-behavior-analysis-task] [regionID=17243255] [span="[74800000000000c9fff75f728000000004ff248b8f0000000000fa, 74800000000000c9fff75f730000000000fa)"]
[2022/05/19 12:32:53.511 +08:00] [INFO] [client.go:926] [“cannot get rpcCtx, retry span”] [changefeed=cbd-user-behavior-analysis-task-ht] [regionID=17243255] [span="[74800000000000c9fff75f728000000004ff248b8f0000000000fa, 74800000000000c9fff75f730000000000fa)"]
heming
(何明)
9
加了忽略参数 ignore-txn-start-ts = [433303111049936914] 重建了 ,不知道能不能过去 。
还是报这个异常:
[2022/05/19 13:22:17.659 +08:00] [INFO] [region_cache.go:566] [“invalidate current region, because others failed on same store”] [region=20021868] [store=xxx.xxx.1
8.166:20160]
[2022/05/19 13:22:17.659 +08:00] [INFO] [client.go:926] [“cannot get rpcCtx, retry span”] [changefeed=cbd-user-behavior-analysis-task-ht] [regionID=20021868] [spa
n="[748000000000009cff525f72800000000dffd560560000000000fa, 748000000000009cff525f72800000000eff24b1ea0000000000fa)"]
[2022/05/19 14:07:14.601 +08:00] [INFO] [client.go:597] [“EventFeed retry rate limited”] [changefeed=cbd-user-behavior-analysis-task] [regionID=28050342] [ts=4333
08417093533742] [changefeed=cbd-user-behavior-analysis-task] [span="[74800000000000e1ff435f720000000000fa, 74800000000000e1ff435f730000000000fa)"] [tableID=57667]
[tableName=cbd_user_behavior_analysis.tbl_new_pageclose_20220519] [addr=xxx.xx.18.159:20160]
foxchan
(银狐)
10
cdc 一直停在autocommit, 怎么查看cdc 卡在哪里了,什么原因?
foxchan
(银狐)
11
现在重做任务,start-ts=0 cdc 都不同步。
heming
(何明)
12
重建的task 持续报这种错误
[2022/05/19 14:19:16.783 +08:00] [INFO] [client.go:779] [“creating new stream to store to send request”] [changefeed=cbd-user-behavior-analysis-task-ht] [regionID
=12657712] [requestID=303908] [storeID=228943] [addr=123.59.18.163:20160]
[2022/05/19 14:19:16.784 +08:00] [INFO] [client.go:825] [“start new request”] [changefeed=cbd-user-behavior-analysis-task-ht] [request="{“header”:{“cluster_id
“:6802042852841994336,“ticdc_version”:“5.3.1”},“region_id”:12657712,“region_epoch”:{“conf_ver”:10329,“version”:1264},“checkpoint_ts”:433308606348394
595,“start_key”:“bURETEpvYkz/af9zdAAAAAD/AAD5AAAAAAD/AABsAAAAAAD6”,“end_key”:“bURETEpvYkz/af9zdAAAAAD/AAD5AAAAAAD/AABtAAAAAAD6”,“request_id”:303908,“Re
quest”:null}”] [addr=123.59.18.163:20160]
[2022/05/19 14:19:16.785 +08:00] [INFO] [region_worker.go:243] [“single region event feed disconnected”] [changefeed=cbd-user-behavior-analysis-task-ht] [regionID
=12657712] [requestID=303908] [span=”[6d44444c4a6f624cff69ff737400000000ff0000f90000000000ff00006c0000000000fa, 6d44444c4a6f624cff69ff737400000000ff0000f900000000
00ff00006d0000000000fa)"] [checkpoint=433308606348394595] [error="[CDC:ErrEventFeedEventError]not_leader:<region_id:12657712 leader:<id:28055331 store_id:10981 > > : not_leader:<region_id:12657712 leader:<id:28055331 store_id:10981 > > “]
[2022/05/19 14:19:16.785 +08:00] [INFO] [region_range_lock.go:383] [“unlocked range”] [changefeed=cbd-user-behavior-analysis-task-ht] [lockID=47650] [regionID=126
57712] [startKey=6d44444c4a6f624cff69ff737400000000ff0000f90000000000ff00006c0000000000fa] [endKey=6d44444c4a6f624cff69ff737400000000ff0000f90000000000ff00006d000
0000000fa] [checkpointTs=433308606348394595]
[2022/05/19 14:19:16.785 +08:00] [INFO] [client.go:597] [“EventFeed retry rate limited”] [changefeed=cbd-user-behavior-analysis-task-ht] [regionID=12657712] [ts=4
33308606348394595] [changefeed=cbd-user-behavior-analysis-task-ht] [span=”[6d44444c4a6f624cff69ff737400000000ff0000f90000000000ff00006c0000000000fa, 6d44444c4a6f6
24cff69ff737400000000ff0000f90000000000ff00006d0000000000fa)"] [tableID=-1] [tableName=DDL_PULLER] [addr=123.59.18.163:20160]
[2022/05/19 14:19:16.805 +08:00] [INFO] [client.go:1163] [“stream to store closed”] [changefeed=cbd-user-behavior-analysis-task-ht] [addr=123.59.18.163:20160] [st
oreID=228943]
[2022/05/19 14:19:16.884 +08:00] [INFO] [region_cache.go:1072] [“switch region leader to specific leader due to kv return NotLeader”] [regionID=12657712] [currIdx
=0] [leaderStoreID=10981]
[2022/05/19 14:19:16.884 +08:00] [INFO] [region_range_lock.go:222] [“range locked”] [changefeed=cbd-user-behavior-analysis-task-ht] [lockID=47650] [regionID=12657
712] [startKey=6d44444c4a6f624cff69ff737400000000ff0000f90000000000ff00006c0000000000fa] [endKey=6d44444c4a6f624cff69ff737400000000ff0000f90000000000ff00006d00000
00000fa] [checkpointTs=433308606348394595]
muliping
(Muliping)
13
重建task 后的日志完整发一下。
有warn级别的日志吗?
heming
(何明)
14
49的所有日志 。 主要看 13点50以后 task cbd-user-behavior-analysis-task-ht 相关的日志
{
“id”: “cbd-user-behavior-analysis-task-ht”,
“summary”: {
“state”: “normal”,
“tso”: 433308160113770553,
“checkpoint”: “2022-05-19 13:50:53.559”,
“error”: null
}
}
ticdc_newleader_49_lastest.log.gz (7.3 MB)
muliping
(Muliping)
15
日志里面 checkpoint ts 是在正常推进的。
再看一下 cbd-user-behavior-analysis-task-h状态。
有没有在推进。
foxchan
(银狐)
19
现在 cdc 延误7个小时了, 重做任务,跳过 ts都试了。 cdc 也重启了。 还有什么方法能让我的cdc 同步尽快恢复
muliping
(Muliping)
21
changefeed=cbd-user-behavior-analysis-task 这个任务同步了几个表,能拆开吗?