【 TiDB 使用环境`】测试环境,测试pd节点的恢复
【 TiDB 版本】 v5.2.1 v6.0.0 在 无外网的情况下,使用镜像安装tidb集群
【遇到的问题】pd节点在删除所有pd目录的数据后,不会自动重新同步新的数据
【复现路径】做过哪些操作出现的问题
v6.0.0 版本操作
方法1:通过pd日志查找
$ cat /data/tidb/pd-2379/log/pd.log | grep “init cluster id”
$ cat pd.log | grep “init cluster id”
[2021/04/06 17:02:13.223 +08:00] [INFO] [server.go:343] [“init cluster id”] [cluster-id=6947967450173627422]
[2021/04/06 17:10:11.066 +08:00] [INFO] [server.go:343] [“init cluster id”] [cluster-id=6947967450173627422]
alloc-id只能通过pd日志查找
$ cat pd.log | grep “idAllocator allocates a new id” | awk -F’=’ ‘{print $2}’ | awk -F’]’ ‘{print $1}’ | sort -r | head -n 1
9000
防止tiup部署后,在破坏掉pd实例后,pd-server被自动拉起来,影响试验效果,需要做如下修改
1、在/etc/systemd/system/pd-2379.service中去掉 Restart=always或者改Restart=no,
2、执行systemctl daemon-reload 重新加载
$ cat /etc/systemd/system/pd-2379.service
[Unit]
Description=pd service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
LimitSTACK=10485760
User=tidb
ExecStart=/data/tidb/pd-2379/scripts/run_pd.sh
Restart=no
RestartSec=15s
[Install]
WantedBy=multi-user.target
下面开始模拟破坏pd节点
10.10.103.89:21379
10.10.103.89:22379 pd
10.10.103.89:2379
1、将3个目录节点删除
rm -rf pd-21379 pd-22379 pd-2379
2、查看集群状态
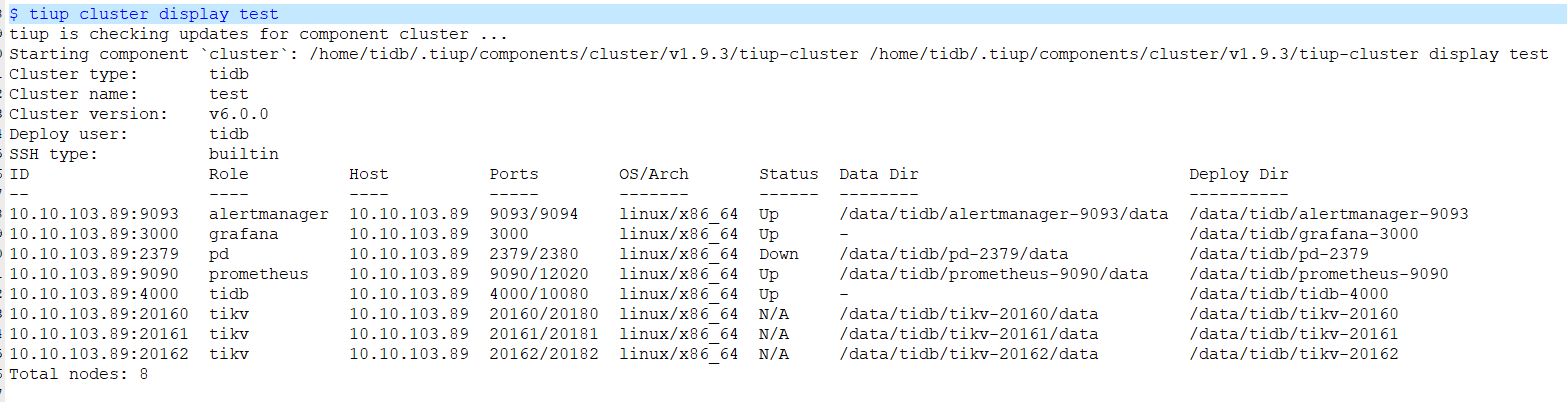
3、通过强制缩容剔除2个节点 10.10.103.89:21379 10.10.103.89:22379
tiup cluster scale-in test -N 10.10.103.89:21379 --force
tiup cluster scale-in test -N 10.10.103.89:22379 --force
$ tiup cluster scale-in test -N 10.10.103.89:22379 --force
tiup is checking updates for component cluster …
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.9.3/tiup-cluster /home/tidb/.tiup/components/cluster/v1.9.3/tiup-cluster scale-in test -N 10.10.103.89:22379 --force
██ ██ █████ ██████ ███ ██ ██ ███ ██ ██████
██ ██ ██ ██ ██ ██ ████ ██ ██ ████ ██ ██
██ █ ██ ███████ ██████ ██ ██ ██ ██ ██ ██ ██ ██ ███
██ ███ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██ ██
███ ███ ██ ██ ██ ██ ██ ████ ██ ██ ████ ██████
Forcing scale in is unsafe and may result in data loss for stateful components.
DO NOT use --force if you have any component in Pending Offline status.
The process is irreversible and could NOT be cancelled.
Only use --force when some of the servers are already permanently offline.
Are you sure to continue?
(Type “Yes, I know my data might be lost.” to continue)
: Yes, I know my data might be lost.
This operation will delete the 10.10.103.89:22379 nodes in test and all their data.
Do you want to continue? [y/N]:(default=N) y
4、查看集群状态
tiup cluster display test
$ tiup cluster display test
tiup is checking updates for component cluster …
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.9.3/tiup-cluster /home/tidb/.tiup/components/cluster/v1.9.3/tiup-cluster display test
Cluster type: tidb
Cluster name: test
Cluster version: v6.0.0
Deploy user: tidb
SSH type: builtin
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
10.10.103.89:9093 alertmanager 10.10.103.89 9093/9094 linux/x86_64 Up /data/tidb/alertmanager-9093/data /data/tidb/alertmanager-9093
10.10.103.89:3000 grafana 10.10.103.89 3000 linux/x86_64 Up - /data/tidb/grafana-3000
10.10.103.89:2379 pd 10.10.103.89 2379/2380 linux/x86_64 Down /data/tidb/pd-2379/data /data/tidb/pd-2379
10.10.103.89:9090 prometheus 10.10.103.89 9090/12020 linux/x86_64 Up /data/tidb/prometheus-9090/data /data/tidb/prometheus-9090
10.10.103.89:4000 tidb 10.10.103.89 4000/10080 linux/x86_64 Up - /data/tidb/tidb-4000
10.10.103.89:20160 tikv 10.10.103.89 20160/20180 linux/x86_64 N/A /data/tidb/tikv-20160/data /data/tidb/tikv-20160
10.10.103.89:20161 tikv 10.10.103.89 20161/20181 linux/x86_64 N/A /data/tidb/tikv-20161/data /data/tidb/tikv-20161
10.10.103.89:20162 tikv 10.10.103.89 20162/20182 linux/x86_64 N/A /data/tidb/tikv-20162/data /data/tidb/tikv-20162
Total nodes: 8
$ tiup cluster display test
tiup is checking updates for component cluster …
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.9.3/tiup-cluster /home/tidb/.tiup/components/cluster/v1.9.3/tiup-cluster display test
Cluster type: tidb
Cluster name: test
Cluster version: v6.0.0
Deploy user: tidb
SSH type: builtin
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
10.10.103.89:9093 alertmanager 10.10.103.89 9093/9094 linux/x86_64 Up /data/tidb/alertmanager-9093/data /data/tidb/alertmanager-9093
10.10.103.89:3000 grafana 10.10.103.89 3000 linux/x86_64 Up - /data/tidb/grafana-3000
10.10.103.89:2379 pd 10.10.103.89 2379/2380 linux/x86_64 Down /data/tidb/pd-2379/data /data/tidb/pd-2379
10.10.103.89:9090 prometheus 10.10.103.89 9090/12020 linux/x86_64 Up /data/tidb/prometheus-9090/data /data/tidb/prometheus-9090
10.10.103.89:4000 tidb 10.10.103.89 4000/10080 linux/x86_64 Up - /data/tidb/tidb-4000
10.10.103.89:20160 tikv 10.10.103.89 20160/20180 linux/x86_64 N/A /data/tidb/tikv-20160/data /data/tidb/tikv-20160
10.10.103.89:20161 tikv 10.10.103.89 20161/20181 linux/x86_64 N/A /data/tidb/tikv-20161/data /data/tidb/tikv-20161
10.10.103.89:20162 tikv 10.10.103.89 20162/20182 linux/x86_64 N/A /data/tidb/tikv-20162/data /data/tidb/tikv-20162
Total nodes: 8
5、启动仅存的pd节点
tiup cluster start test -N 10.10.103.89:2379

这一步启动,是没有启动起来的,而且pd数据目录也没有同步
修改pd节点信息
$ tiup pd-recover -endpoints http://10.10.103.89:2379 -cluster-id 6947967450173627422 -alloc-id 16000
tiup is checking updates for component pd-recover …
A new version of pd-recover is available:
The latest version: v6.0.0
Local installed version:
Update current component: tiup update pd-recover
Update all components: tiup update --all
The component pd-recover version is not installed; downloading from repository.
Starting component pd-recover: /home/tidb/.tiup/components/pd-recover/v6.0.0/pd-recover /home/tidb/.tiup/components/pd-recover/v6.0.0/pd-recover -endpoints http://10.10.103.89:2379 -cluster-id 6947967450173627422 -alloc-id 12000
{“level”:“warn”,“ts”:“2022-05-03T11:29:09.522+0800”,“caller”:“clientv3/retry_interceptor.go:61”,“msg”:“retrying of unary invoker failed”,“target”:“endpoint://client-6ab7221d-1310-4a6c-b033-e627126276a8/10.10.103.89:2379”,“attempt”:0,“error”:“rpc error: code = DeadlineExceeded desc = latest balancer error: all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp 10.10.103.89:2379: connect: connection refused"”}
context deadline exceeded
【问题现象及影响】
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
