集群为:v4.0.8
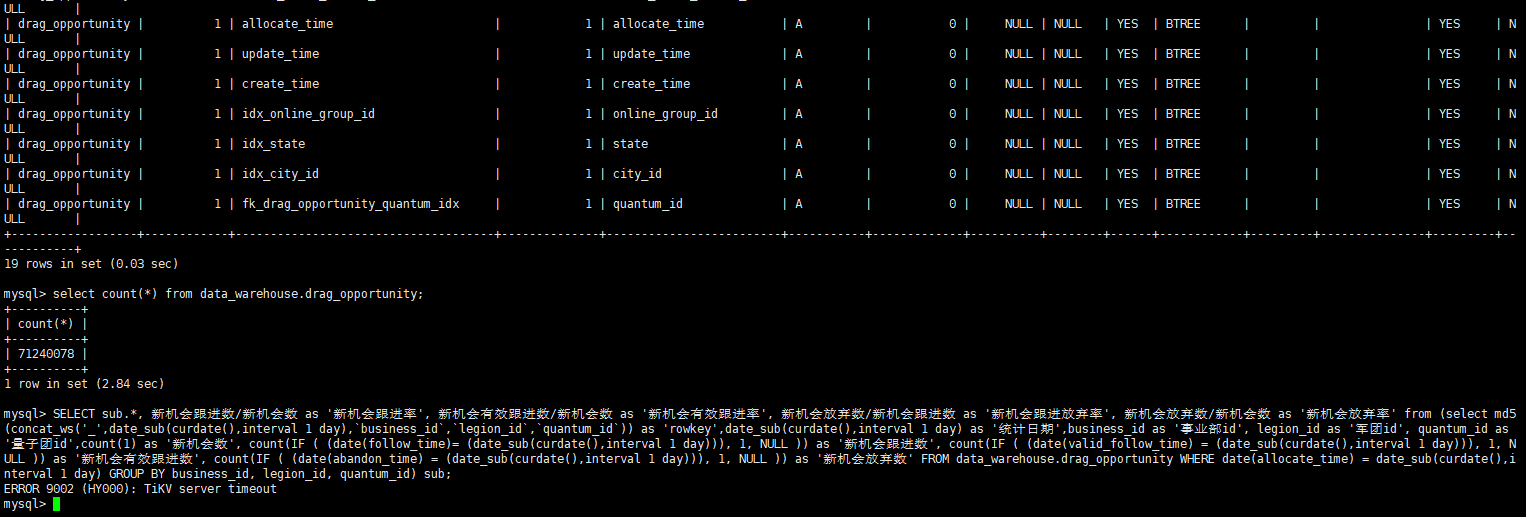
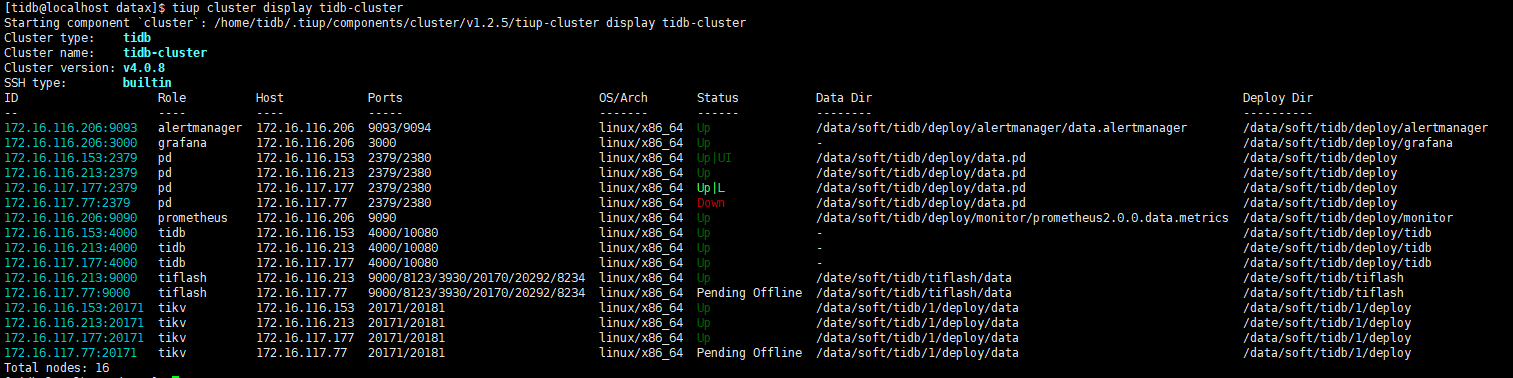
有一台服务器不知道为什么关机了,3节点PD,通过将扩容PD节点,并下线该服务器上PD,TIKV,TIFLASH节点,使集群拉起,提供服务。但是写入性能低,大查询查不出结果




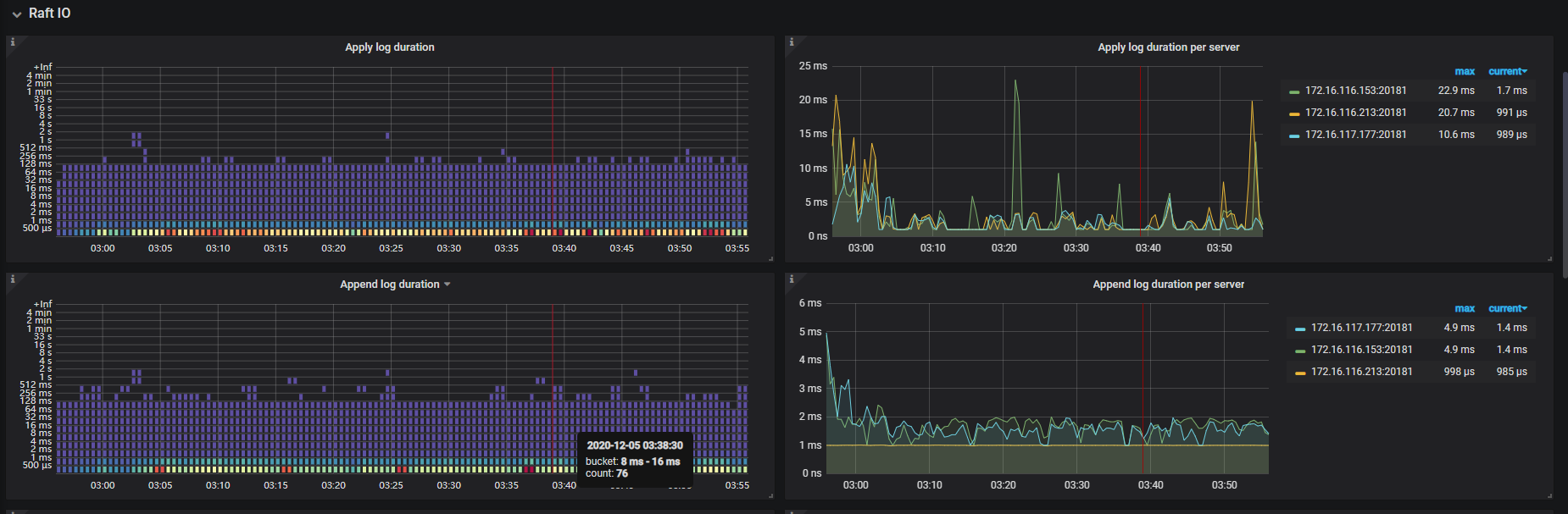
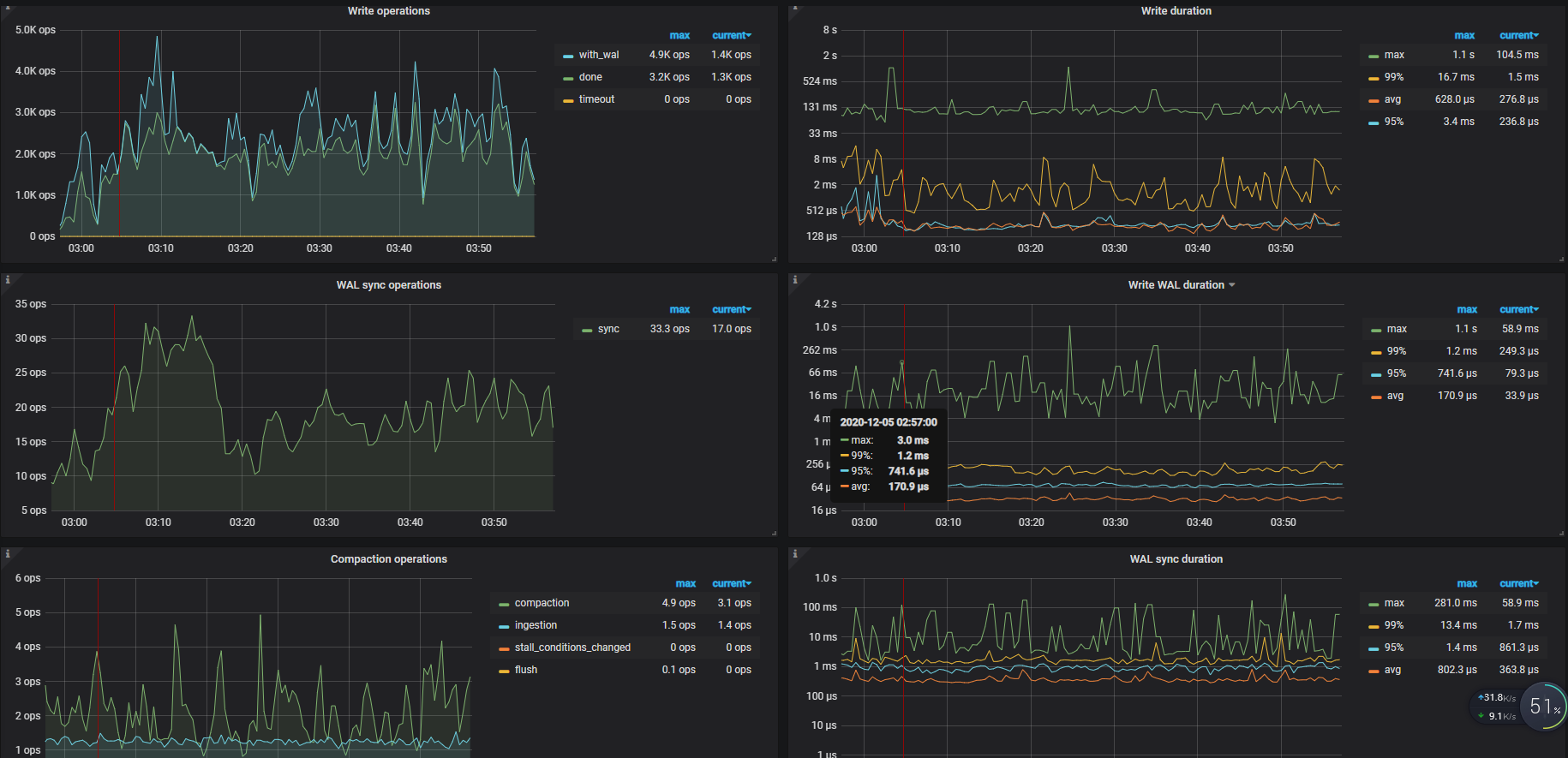

可以提供一下完整的 Overview 和 TiKV-Details 以及 PD、TiDB 几个面板的监控看下
导出监控步骤:
- 打开监控面板,选择监控时间
- 打开 Grafana 监控面板(先按
d再按E可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成) - https://metricstool.pingcap.com/ 使用工具导出 Grafana 数据为快照
您好,这是当天的grafana数据。
这个重新扩容节点之后,集群性能恢复耗时挺长的。有没有什么好的办法,来避免出现节点不可用的时候,集群恢复过慢的问题
grafana.zip (9.4 MB)
正常如果只有一个 TiKV 节点挂掉不会影响集群的正常访问。
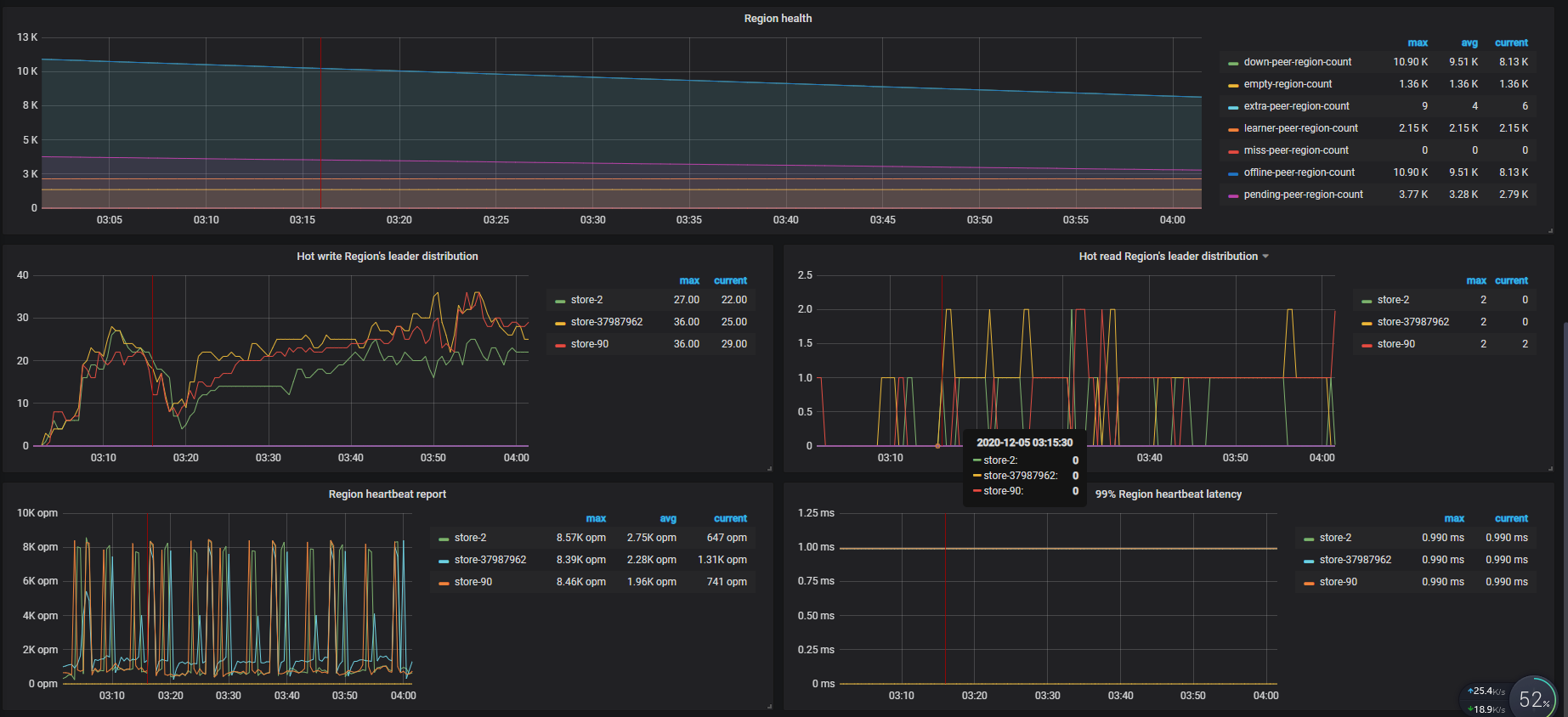
从监控上看到当时有两个节点都无法连接上了,可以确认一下 store id 为 37876005 和 37903405 的节点是哪两个节点。在默认 3 副本的情况下,如果有两个节点无法同时无法访问,会导致无法满足 raft 多数派协议,无法对外提供服务,TiDB 访问的时候会报 TiKV server timeout
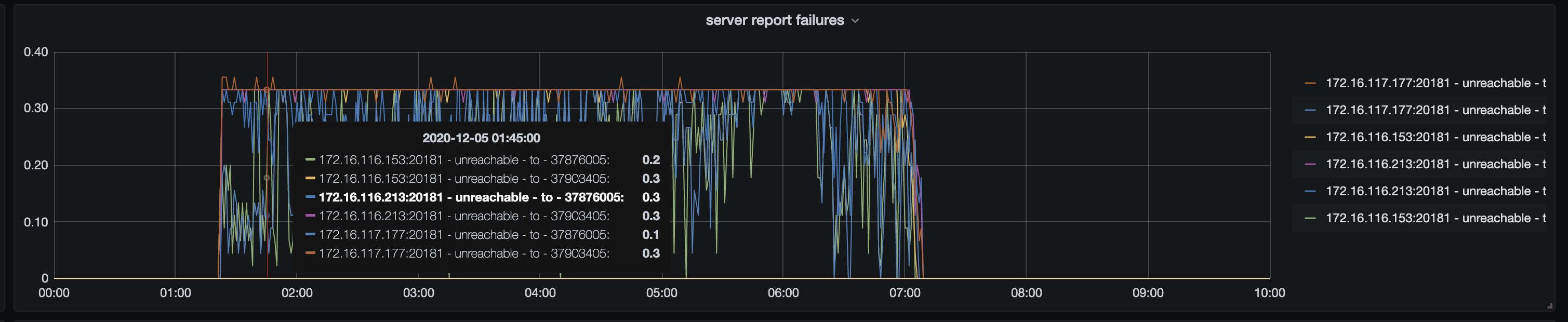
另外从监控的 leader 以及 region 数据量上,有上升的趋势,当时是有导入数据的操作么。

1.这两个数据节点一个是tikv,一个是tiflash,是混合部署在同一台服务器(还有PD节点)上,应该不会影响tikv的使用,但是tikv当时读写性能很差;
2.当时没有进行额外的数据导入操作,应该都是正常的DM同步,和实时计算流写入。

当时的 tidb.log 日志还有么,如果有的话,能不能上传一下
老师您好,这是当时的tidb日志,有点多
链接:https://pan.baidu.com/s/1pugwQmi6IaqNViF63bBEXQ
提取码:29ne
复制这段内容后打开百度网盘手机App,操作更方便哦
看了下日志,12-05 01:21 开始 Duration 开始上升时候,tidb.log 日志中开始报 no available connections 的错误,对应的节点是 172.16.117.77:20171 节点,
[2020/12/05 01:21:36.219 +08:00] [INFO] [client_batch.go:347] ["batchRecvLoop fails when receiving, needs to reconnect"] [target=172.16.117.77:20171] [error="rpc error: code = Unavailable desc = transport is closing"]
[2020/12/05 01:21:36.535 +08:00] [INFO] [client_batch.go:347] ["batchRecvLoop fails when receiving, needs to reconnect"] [target=172.16.117.77:20171] [error="rpc error: code = Unavailable desc = transport is closing"]
[2020/12/05 01:21:36.536 +08:00] [INFO] [client_batch.go:347] ["batchRecvLoop fails when receiving, needs to reconnect"] [target=172.16.117.77:20171] [error="rpc error: code = Unavailable desc = transport is closing"]
[2020/12/05 01:21:36.792 +08:00] [INFO] [client_batch.go:347] ["batchRecvLoop fails when receiving, needs to reconnect"] [target=172.16.117.77:20171] [error="rpc error: code = Unavailable desc = transport is closing"]
[2020/12/05 01:21:36.822 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.859 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.864 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.880 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.897 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.906 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.915 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.916 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.918 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.922 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
[2020/12/05 01:21:36.925 +08:00] [WARN] [client_batch.go:526] ["no available connections"] [target=172.16.117.77:20171]
超时也是这个节点

当时集群 duration 上升主要是因为这个节点导致的。这个 tikv 实例当时是关机的那台服务器上的么。当时的状态是服务器关机了,一直没有起来么?然后执行 store delete 的下线操作?tikv 进程是启动的么?
另外除了扩容 PD 节点之外,还有扩容 TiKV 吗?
对,这个tikv实例是在当时那台关机的服务器上,这台服务器第二天下午才重启。
当时发现那台服务器关机之后,就在新服务器扩容了pd和tikv,两个操作间隔应该不长。
因为服务所在服务器关机,tiup不能缩容节点,当时使用的pdctl通过store delete进行的下线
新扩容的节点是哪个 IP ?
另外服务器关机的具体时间点能确认吗?关机的原因是人为操作还是系统问题?
1.新扩容的是这个服务器,这台服务器之前只有tiflash,172.16.116.213
2.服务器关机时间应该就在12月5号凌晨1:20左右
老师,我刚看了tiup的历史纪录,发现那天扩容的是pd和tiflash
tikv之前就是四台
掉线那台机器上部署了tikv,pd,tiflash(单节点)
导致集群性能下降的原因会是没有tiflash节点可用造成的吗?
下面是现在的实例图
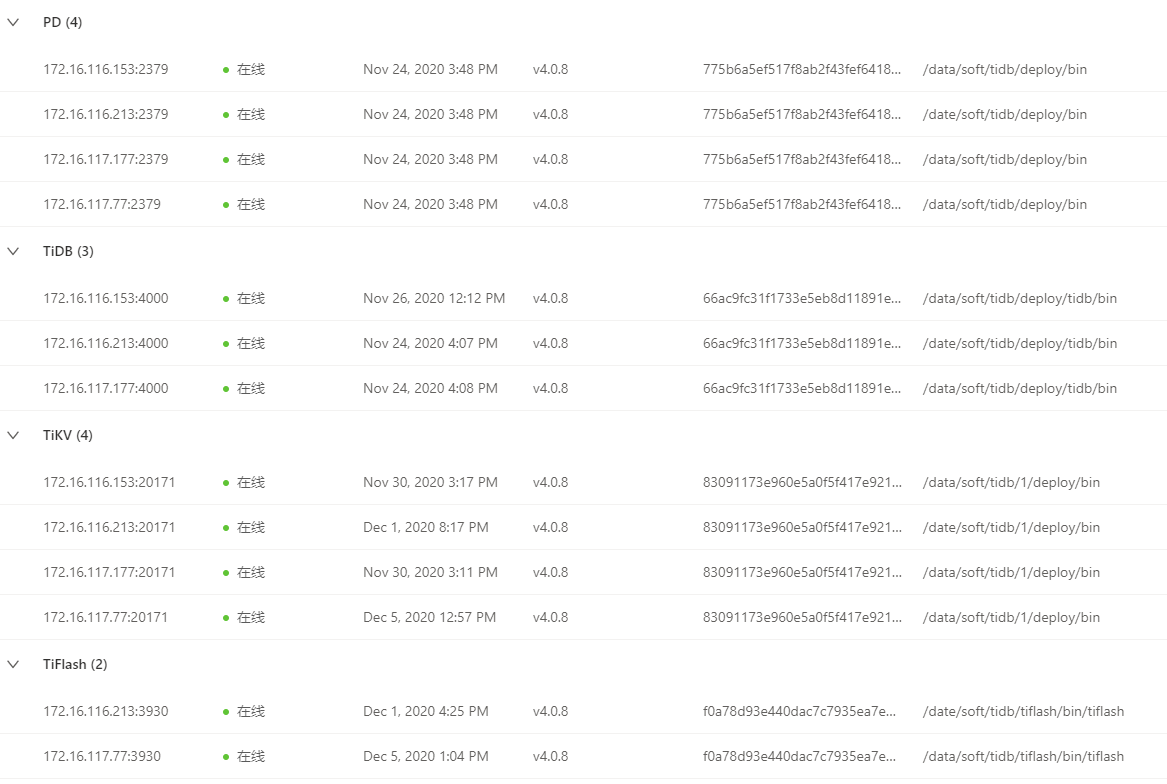
看 tidb.log 日志的话,没有看到访问 TiFlash 超时的情况。
tidb.log 中 对于 172.16.117.77:20171 这个挂掉的 tikv 节点,持续报 no available connections 的日志,持续到 2020-12-05 12:57 ,这个现象应该是不符合预期的,需要再分析一下原因。

执行 store delete 之后,状态显示就是 pending offline 的,这个状态表示等待将该 TikV 实例上的 region 迁移到别的 TiKV 实例上,等待该节点上的 reigon 都迁移完成之后,状态会编程 tombstone 的。
但是因为这个 TiKV 实例进程挂掉了,所以 region 一直无法迁移完成,状态会一直显示 pending offline
请问一下,后续这个集群是在什么时间点,做了什么操作之后恢复正常的?
这个从扩容完pd节点之后就可以写入了,只是写入速度很慢(每秒三/四百条)。
从5号早上7点多,也就是peer分配完成之后,写入达到2000左右每秒。
但是大查询,亿级别表count,group by等操作要到5号下午才可以执行。5号中午对一部分关键表进行了analyze table,analyze过程中会有超时异常,多次analyze之后,表就可以用了
对于上面 tikv backoff.maxSleep 超时的日志解释是:
tidb 这边不知道 tikv 是挂了,还是网络暂时不通了
它会一直尝试重连
只要 region cache 没有更新到新的,就会持续访问旧的 tikv 节点
直到慢慢的再也没有请求打那个 region 上,跟那个 tikv 的连接变成 idle 状态,一段时间之后,回收掉连接
单次 tikv 访问到旧节点上 region 超时需要 40000ms 的 backoff 时间,所以对于访问到旧节点上 region leader 的请求访问都会比较慢。
如果当时重启 tidb-server 的话,会更新 region cache ,那应该不会有这么大的影响。
![]()
好的,谢谢老师。
终于知道这个原因是什么了,通过监控观察也发现tidb写入TPS与down-peer呈负相关。
表健康度不足的问题,还是需要手动analyze table来修复吧
嗯,统计信息健康度需要通过 analyze table 重新收集统计信息。
但是统计信息应该与 TiKV 节点 down 掉没有关系。不过默认 analyze table 是全量收集统计信息,会扫描表中所有的数据, 如需更快的分析速度,可将 tidb_enable_fast_analyze 设置为 1 来打开快速分析功能。该参数的默认值为 0