【 TiDB 使用环境】 V5.3.0
【概述】
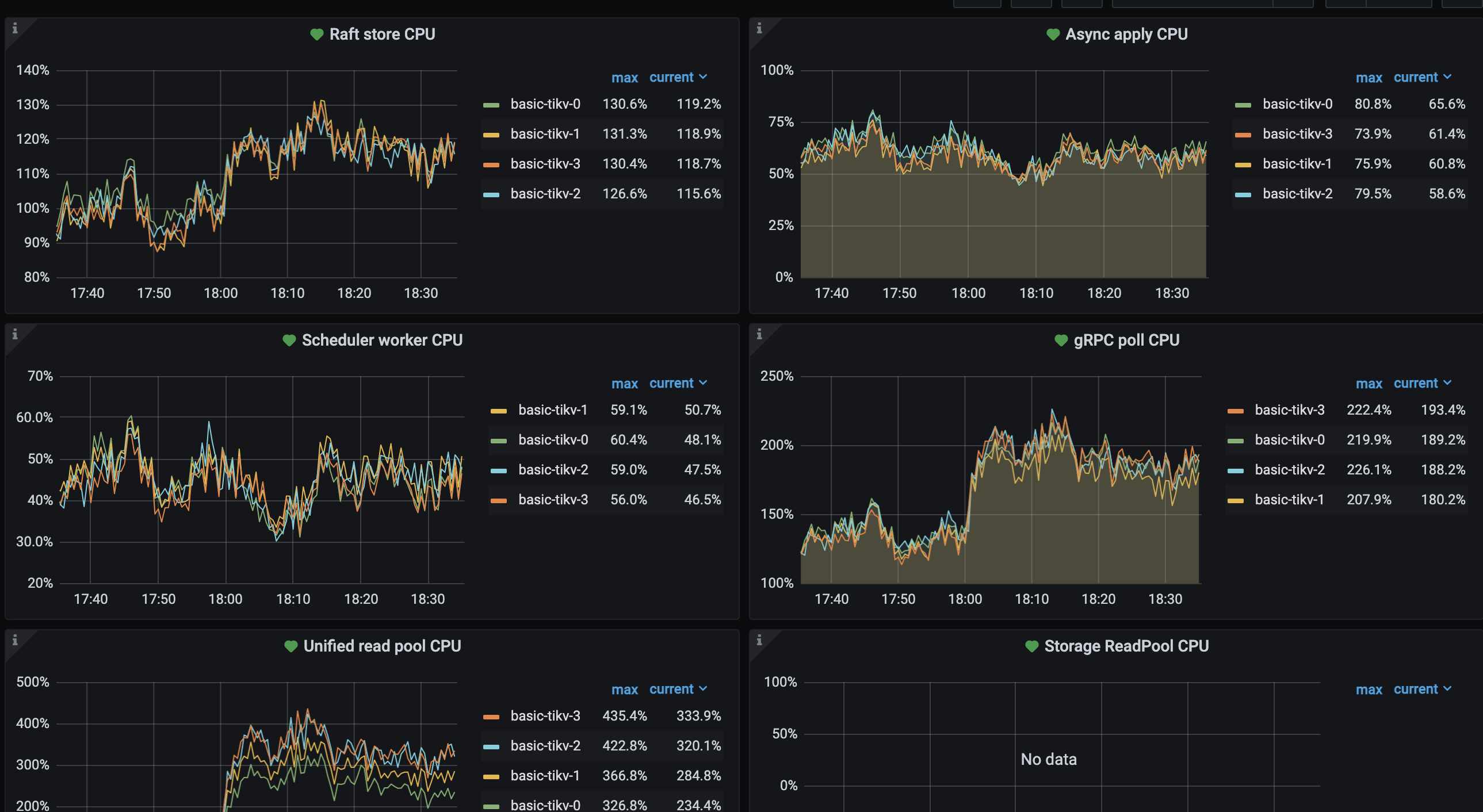
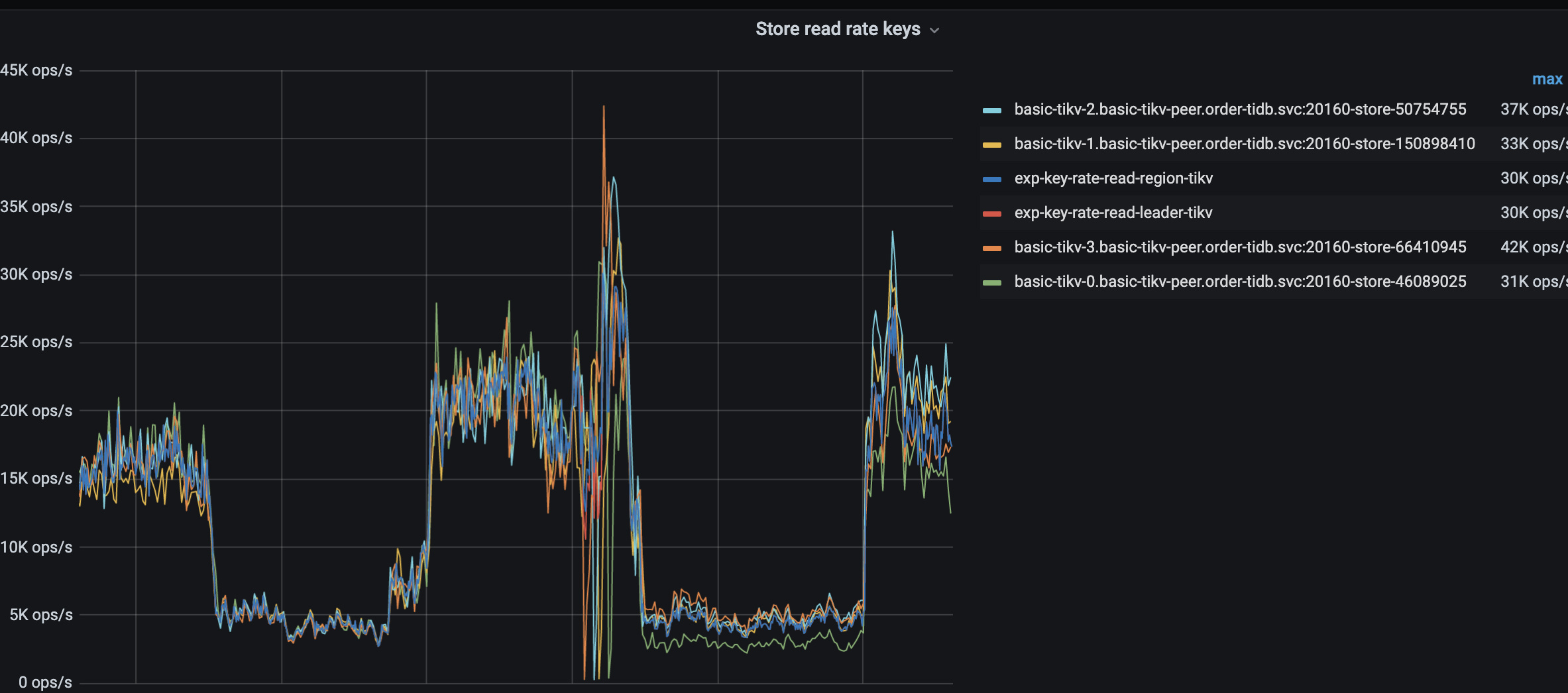
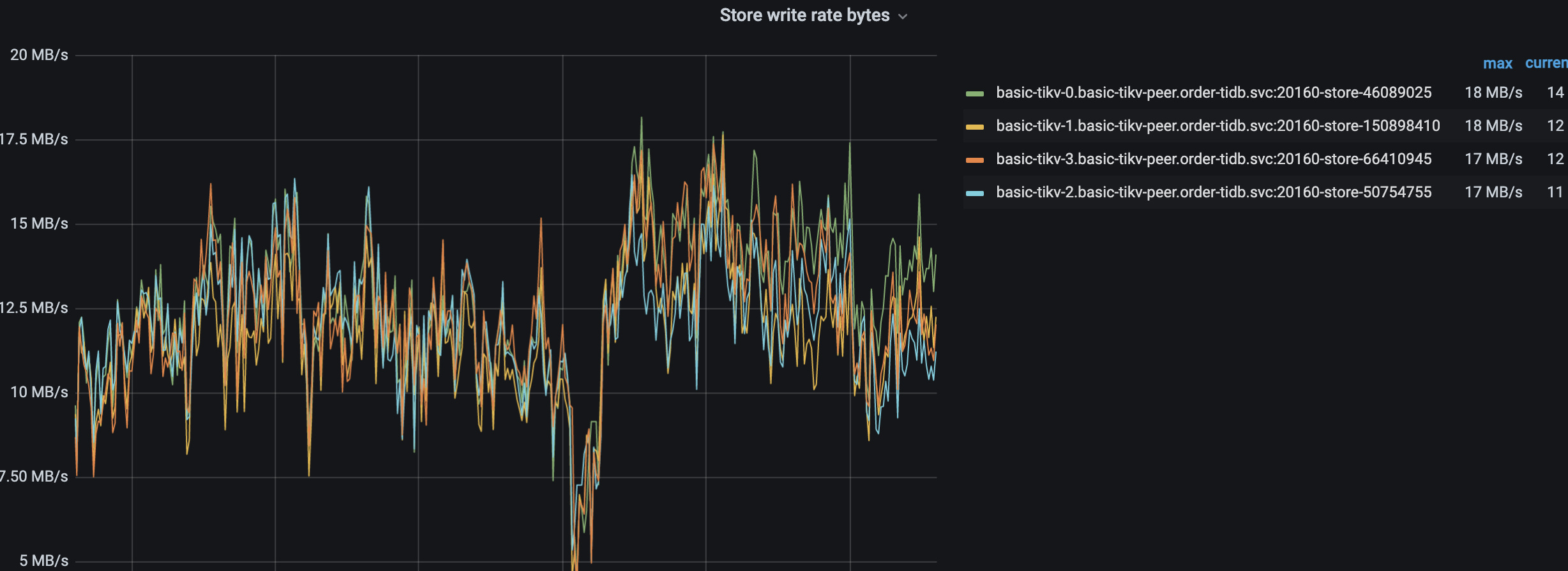
想问一下TIKV各个节点中,cpu、raft-store、scheduler、grpc等线程负载均比较均衡而且读写流量差别不大,但是磁盘io差距较大,是否可能存在热点?
-
ThreadCPU指标:
-
PD的监控指标:
-
磁盘io率:
-
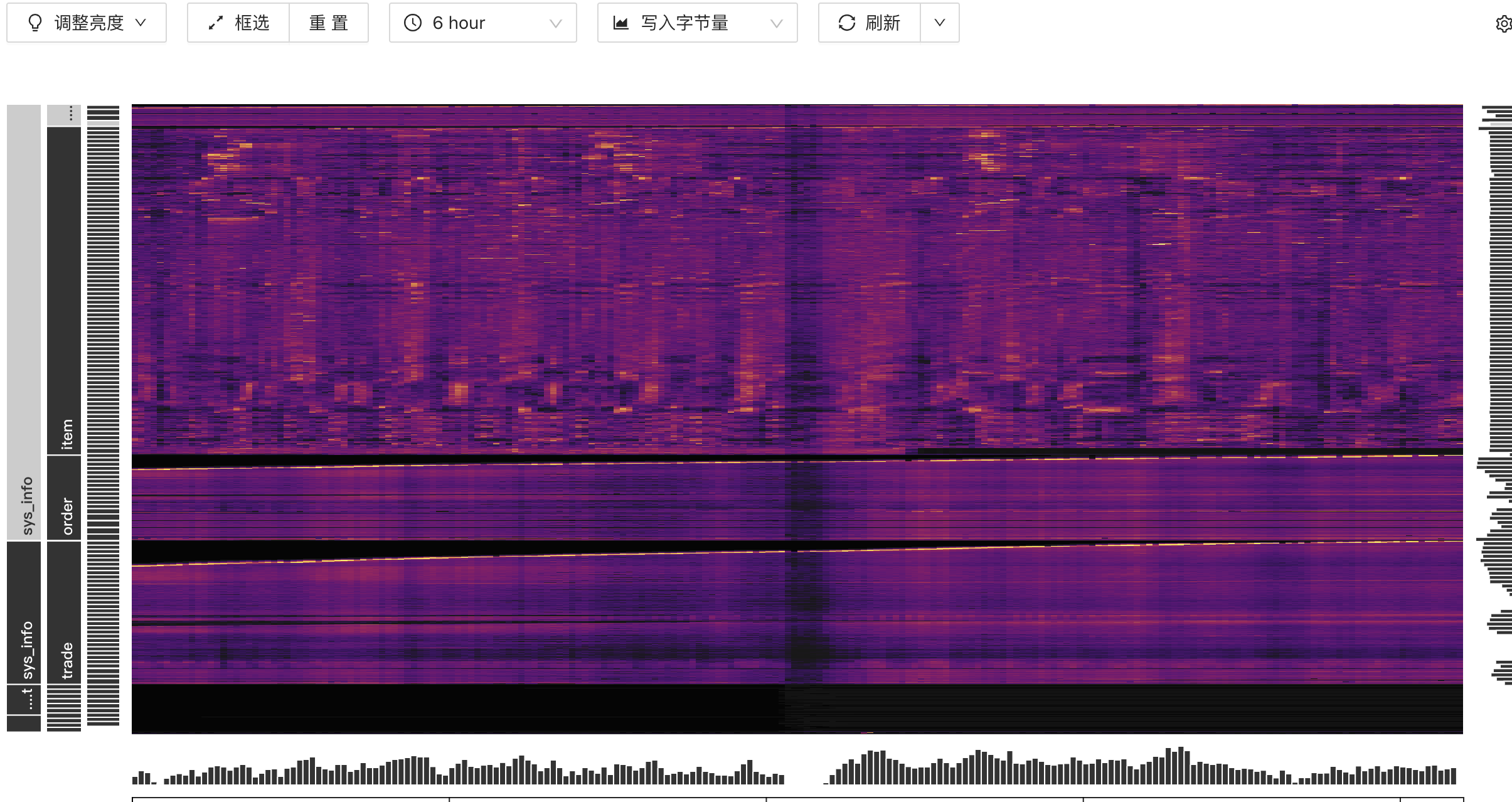
dashboard:
【 TiDB 使用环境】 V5.3.0
【概述】
想问一下TIKV各个节点中,cpu、raft-store、scheduler、grpc等线程负载均比较均衡而且读写流量差别不大,但是磁盘io差距较大,是否可能存在热点?
ThreadCPU指标:
PD的监控指标:
磁盘io率:
dashboard:
热点图都已经那么亮了 肯定热点了
您好,不太明白,这里能看出来是读热点还是写热点吗
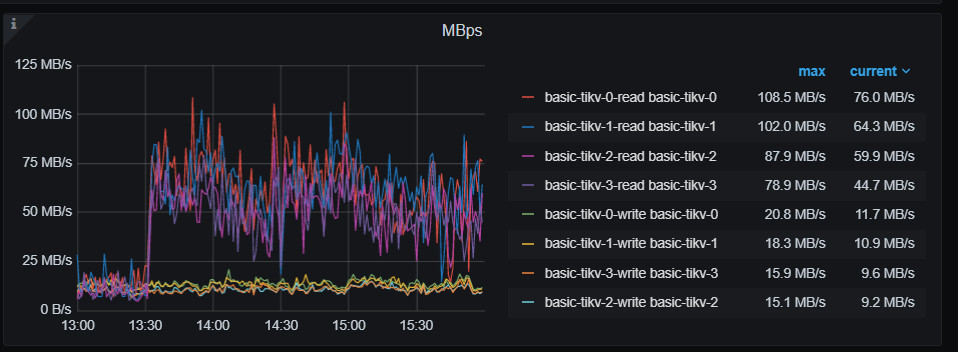
上面是读字节,应该是读热点
通过 慢查询页面和sql语句分析页面确认问题时间点的sql
看下慢SQL
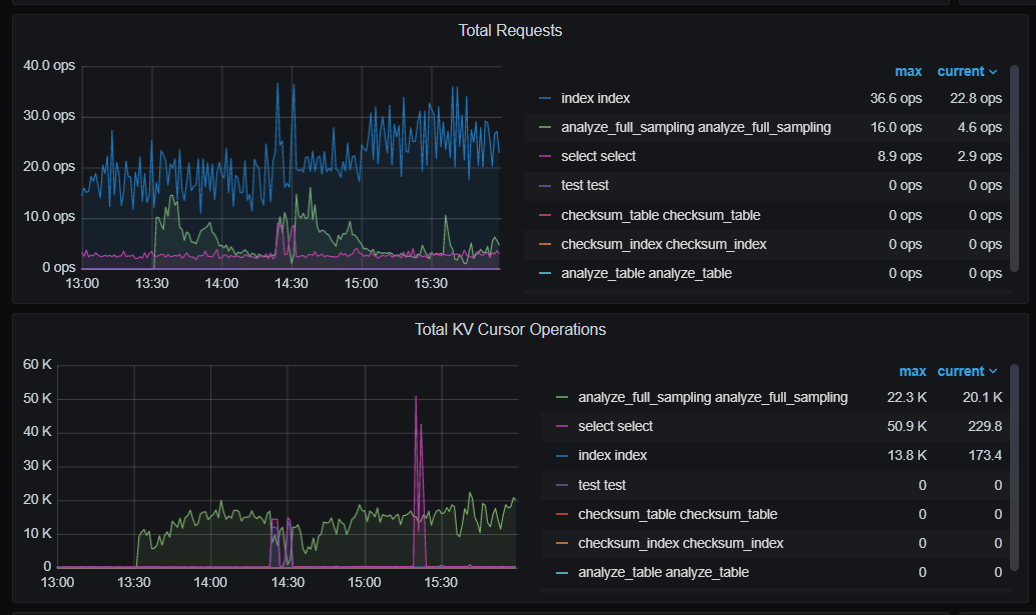
慢SQL基本都是 insert和主键的pointGet
看一下慢sql的执行计划
根据图形判断存在热点数据,建议查询慢sql的执行计划
是否是虚拟机?
关注中
部署在k8s中
比如说,有的tikv的coprocessor读比较多,会导致这个tikv的cpu占用多一些。另外,除了这几个线程池,tikv下面的rocksdb还有compact,也占cpu和磁盘io,尤其是compact占用磁盘io比较高。cpu均衡并不能代表磁盘io就均衡。
最好均衡的分散tikv上不同类型的读。
像你上面的执行计划,cop[tikv]就是tikv的coprocessor读,可以看看各个tikv的这种类型的读是否均衡,不均衡就调整下。
https://metricstool.pingcap.com/#backup-with-dev-tools
按此将 overview/pd/tikv detail/pd/node expoter的问题时间段和之前半小时左右的监控导出
node exporter当时的监控数据已经被清理了,这里有 cluster-overview,pd,tidb,tikv-detail的监控数据,麻烦看下是否可以.
Cluster-TiDB_2022-04-11T05_10_06.304Z.json (3.2 MB)
Cluster-TiKV-Details_2022-04-11T05_10_54.712Z.json (15.5 MB)
Cluster-PD_2022-04-11T05_09_25.513Z.json (4.4 MB)
Cluster-Overview_2022-04-11T05_08_37.969Z.json (1.5 MB)
现在是问题还在持续还是已经恢复了?overview中没显示磁盘IO信息,如果问题还在持续可以从disk performance或node exporter看看各tikv的磁盘利用率高的是否IOPS、带宽也高,如果磁盘不忙利用率高可能磁盘有些问题。
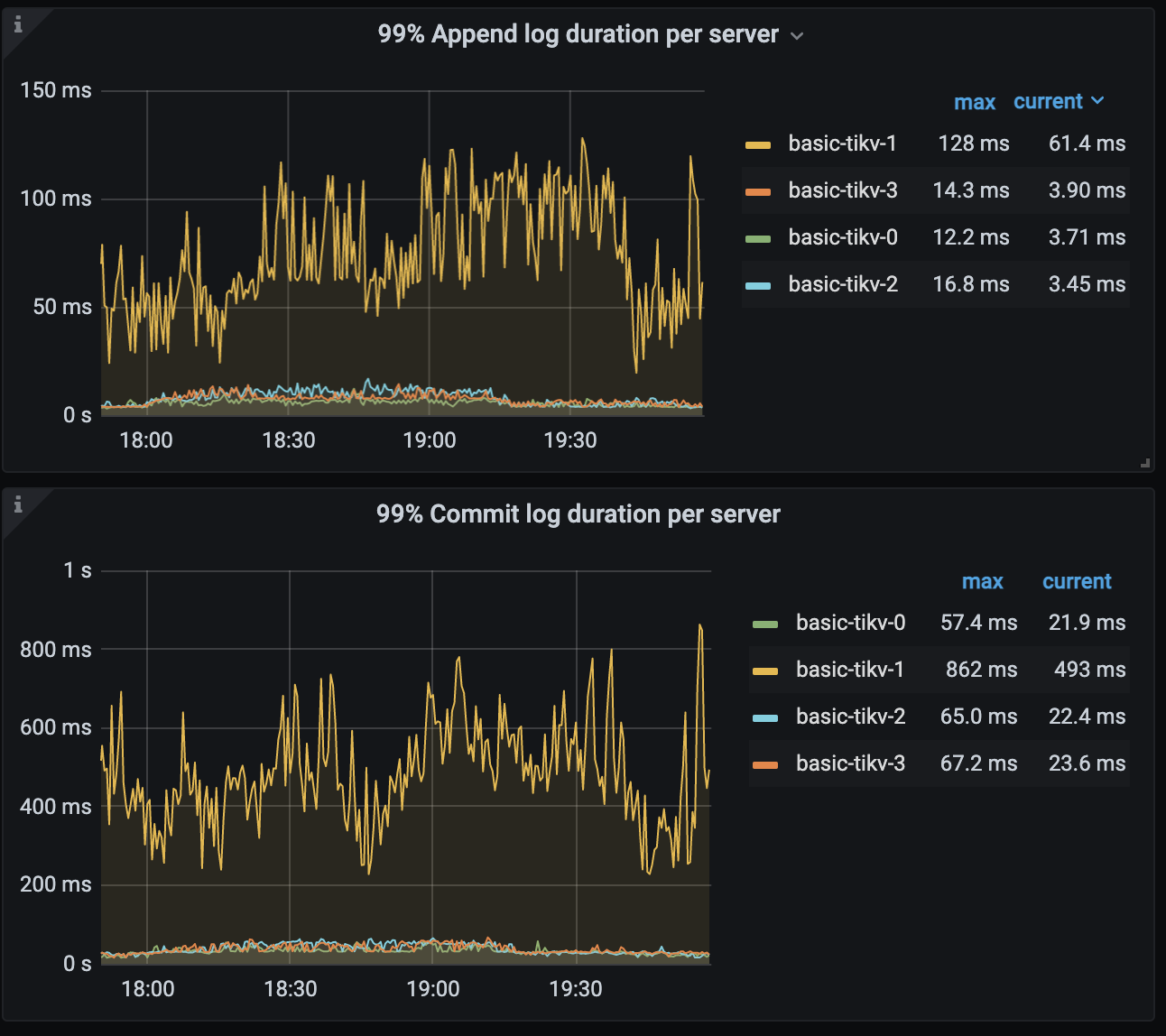
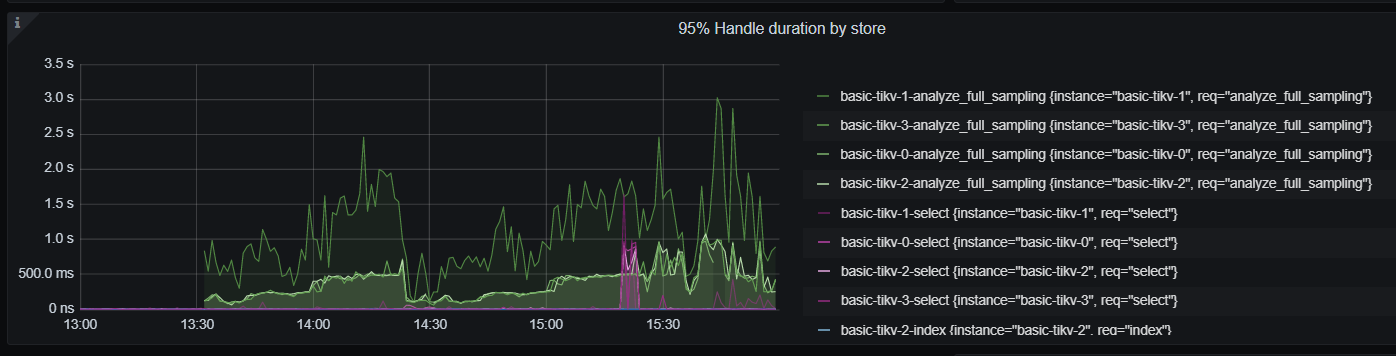
从监控上看13:30的时候有analyze table执行,导致tikv的处理延迟增高。 tikv1相比其他的tikv的延迟要高写,到tikv1的coprocesssor请求也比其他节点多写,存在不均衡现象。
在dashboard - SQL语句分析里 在选择列里按coprocess请求次数、文件系统读次数等排序 看哪些SQL请求多、物理读多
PD对region的均衡调度主要以下几类,计算里没有考虑磁盘IO情况,可能当网络流量均衡后CPU也均衡:
问题仍在持续,之前觉得自增主键有问题,就重建了表不再使用自增主键,还是同一个节点写磁盘特别慢。之后将该节点下线之后更换了新的机器,然后就有新的慢节点出现了。。有更精确的定位是什么region写入导致该节点慢的方法吗,使用 pd-ctl的hotregion和 information_schema.TIDB_HOT_REGIONS 这张表都看不出来这个慢节点有异常
建议先看SQL有没有可优化的、物理读多的。可以尝试一下pd-ctl store weight 调整下磁盘慢的tikv的leader权重比如0.8,让部分leader调度到其他节点看看是否有所缓解。把现在的磁盘情况贴一下