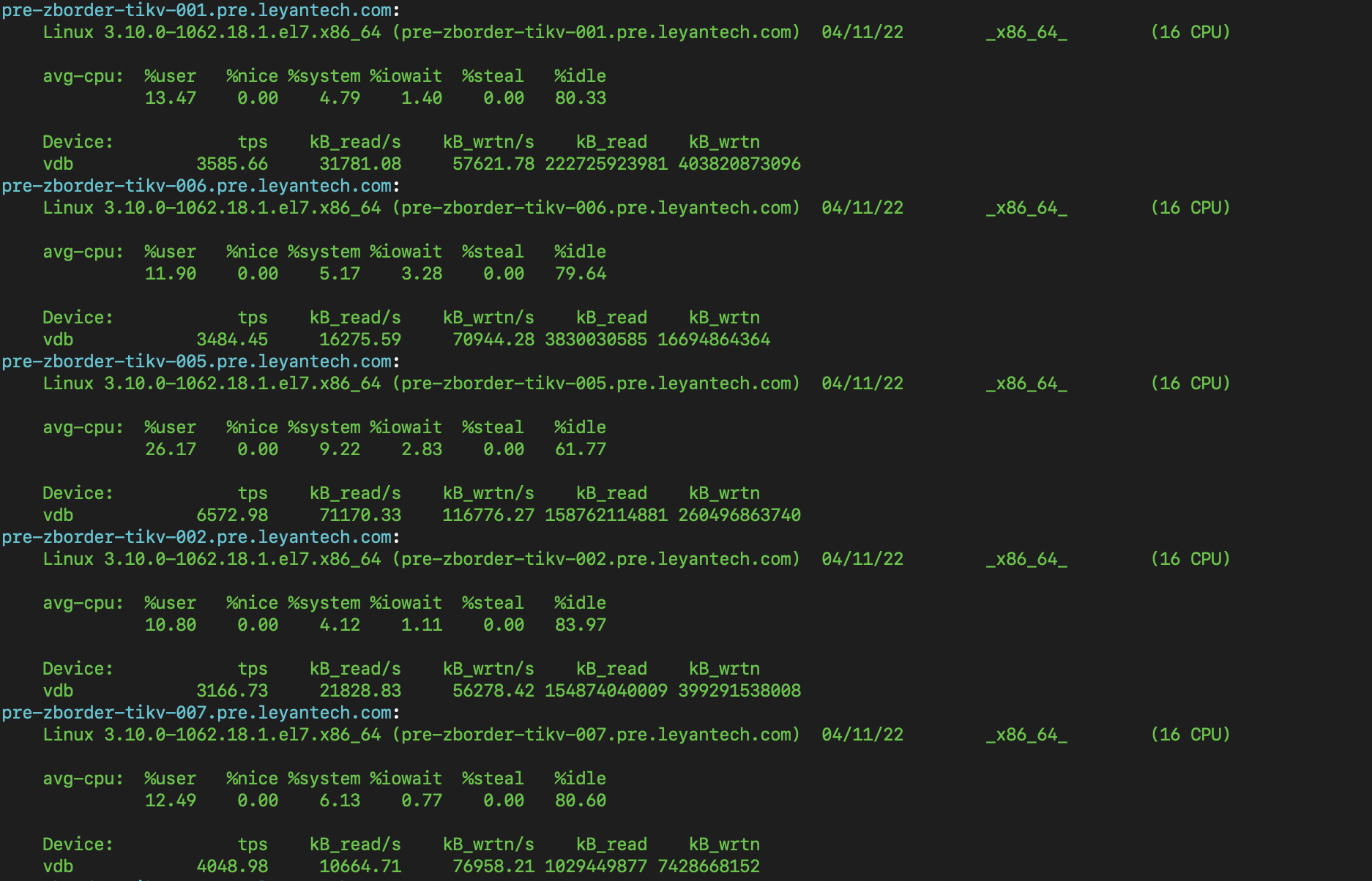
调过慢节点的leader权重,没什么效果。下面图第三个就是现在的慢节点
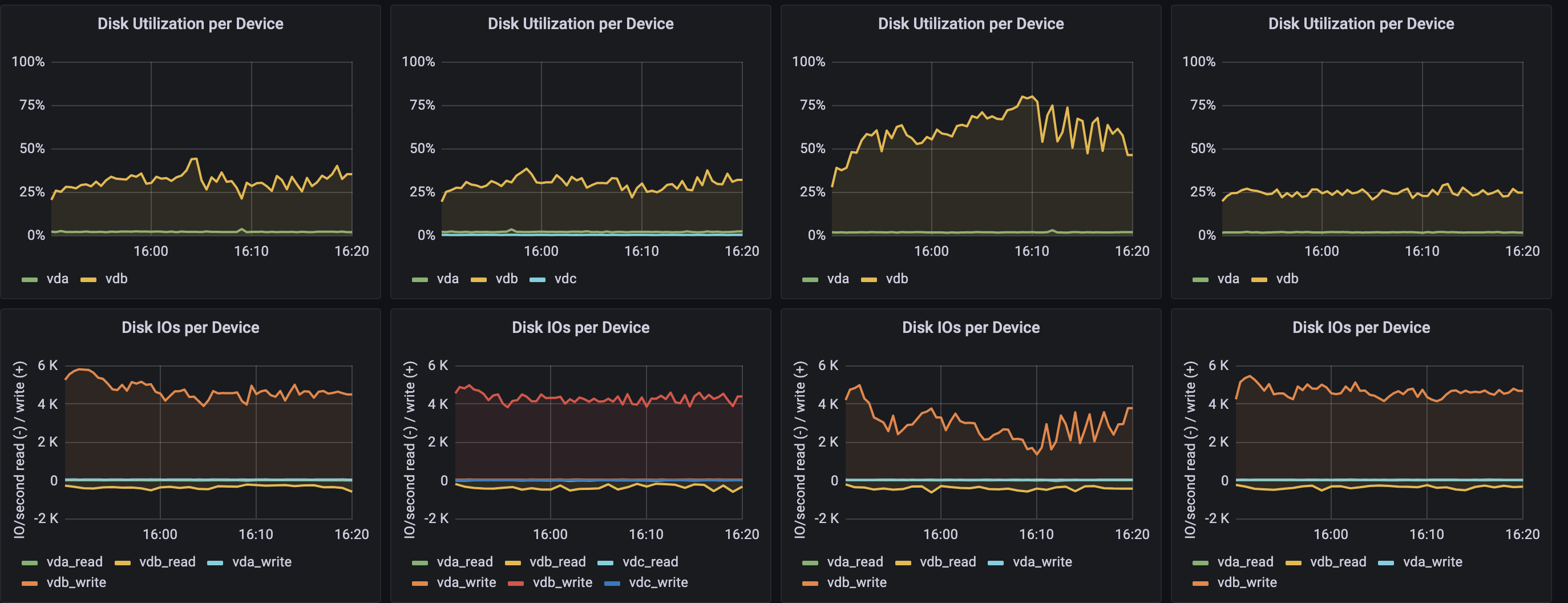
目前主要的查询就是insert,在16:00左右开了一个表的写入,io就变的异常了。这个表字段会特别大,不知道有没有影响。但是从另一个角度,每个raft member都是会写相同数据的,不明白为啥单这个节点异常
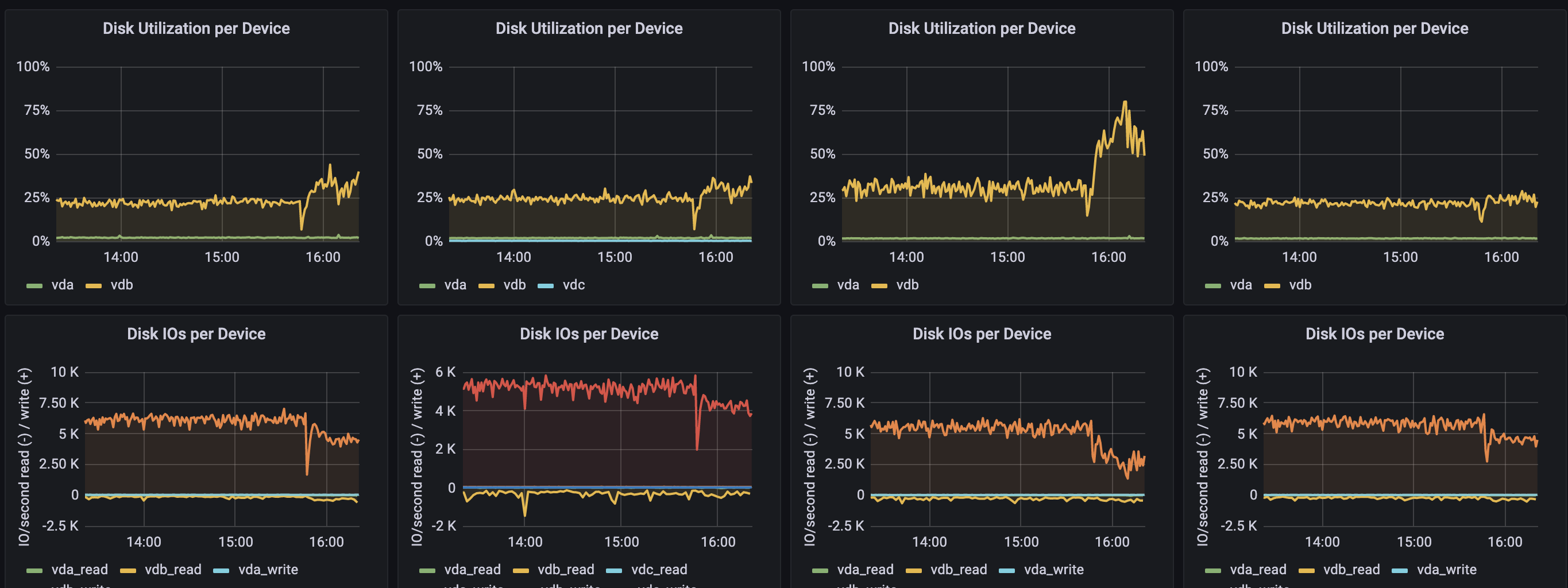
各个节点 iostat,慢节点是006
1 个赞
你的机器是物理机还是云主机
1 个赞
云主机
1 个赞
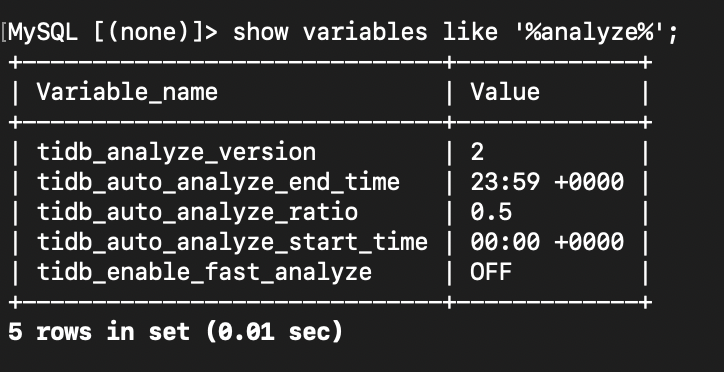
看下参数show variables like ‘%analzye%’, tidb日志搜索下auto analyze trigger看看有分析任务在跑不。
1 个赞

analyze 写错了,你搜auto analyze
1 个赞
看过云主机的系统监控没,IO是什么样的
1 个赞
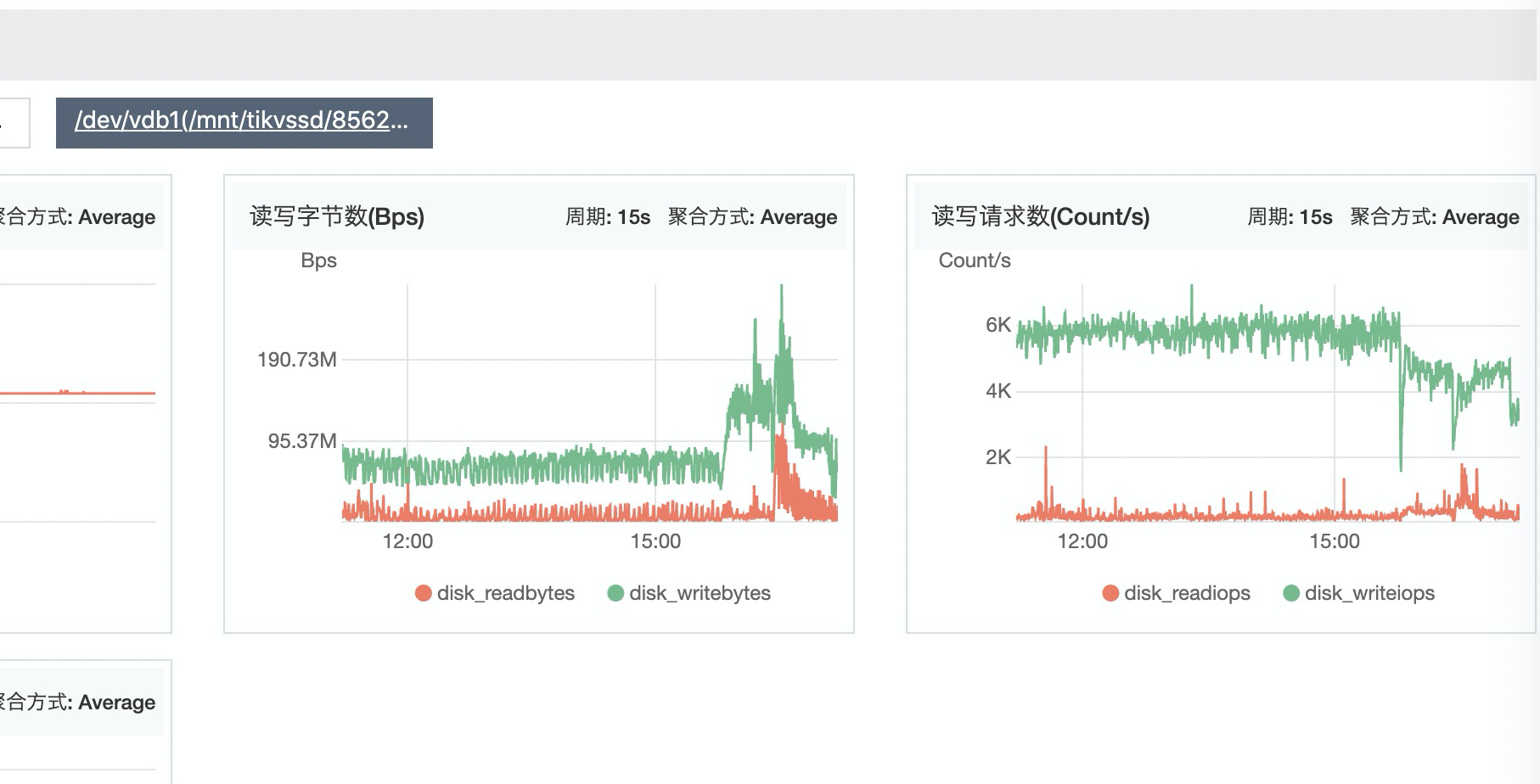
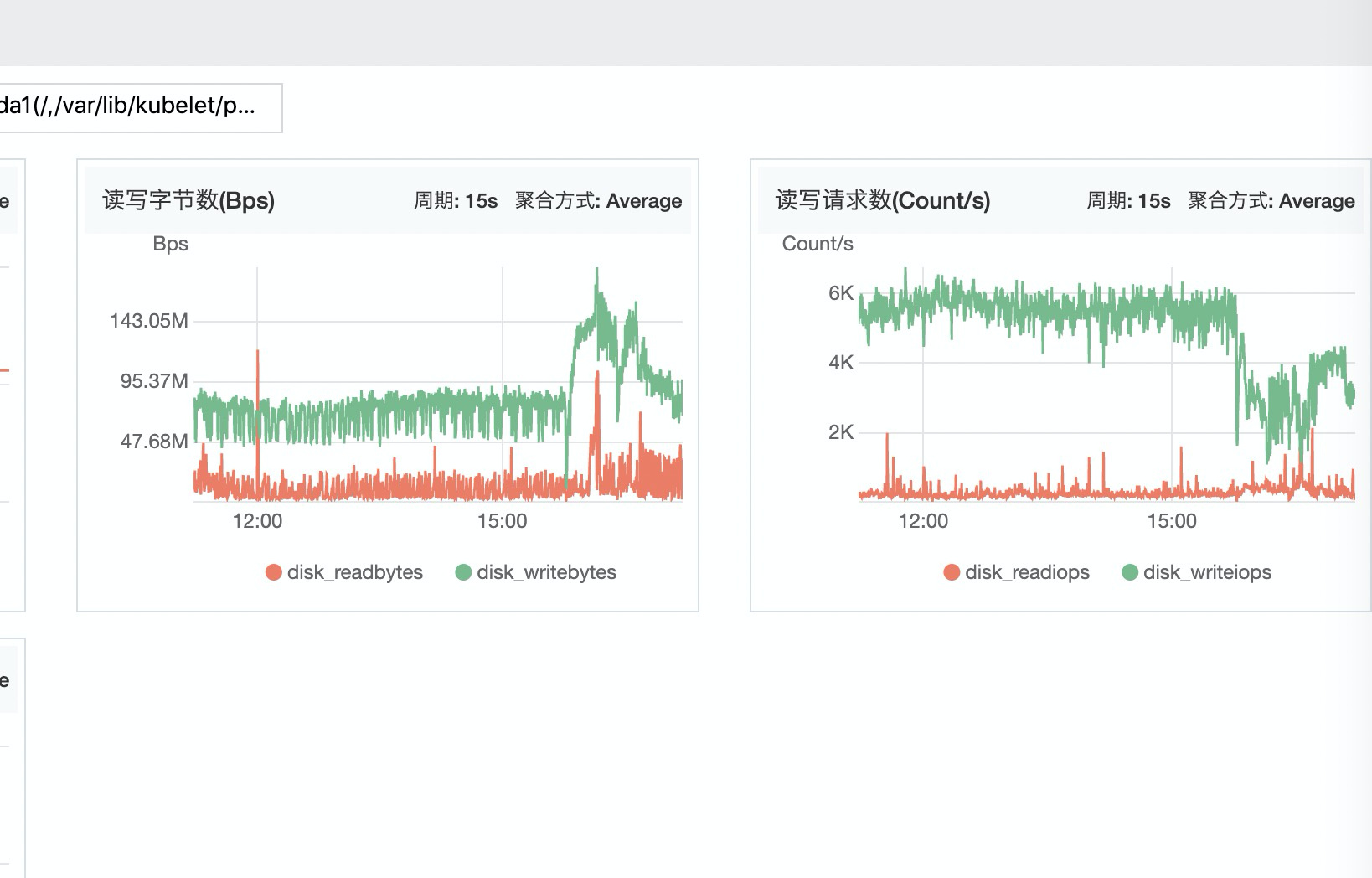
看你这个截图的的话正常情况这几个tikv的io都是均衡的只是在这个表insert时导致不均衡, insert的create table发下?是否有递增类型的字段
1 个赞
是的,从pd的各个store的流量和tikv的读写流量也能看出来差距不是很大。。
createTable.sql (6.8 KB)
1 个赞
登录pd, 执行 pd-ctl region topread
pd-ctl region topwrite
1 个赞
好的,目前 去掉了其中一个大字段之后有一定的效果,慢节点的io相比其它节点没有那么显著了。。。
1 个赞
看来是大字段的影响?
从现象对比来看有这个可能性,rootcause还没有找到
至少也应该是有3个kv实例io有影响,但只体现1个,还是很奇怪。
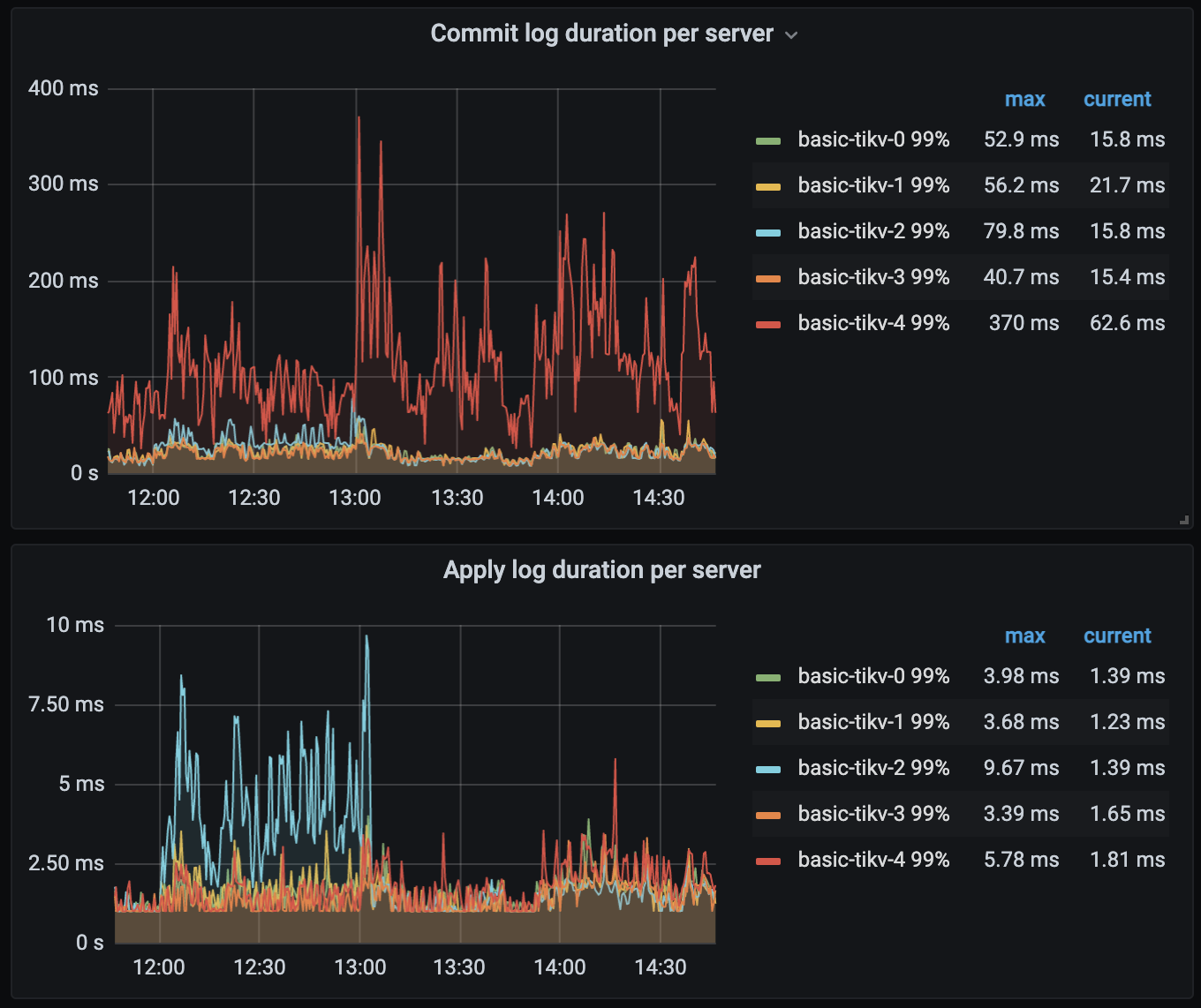
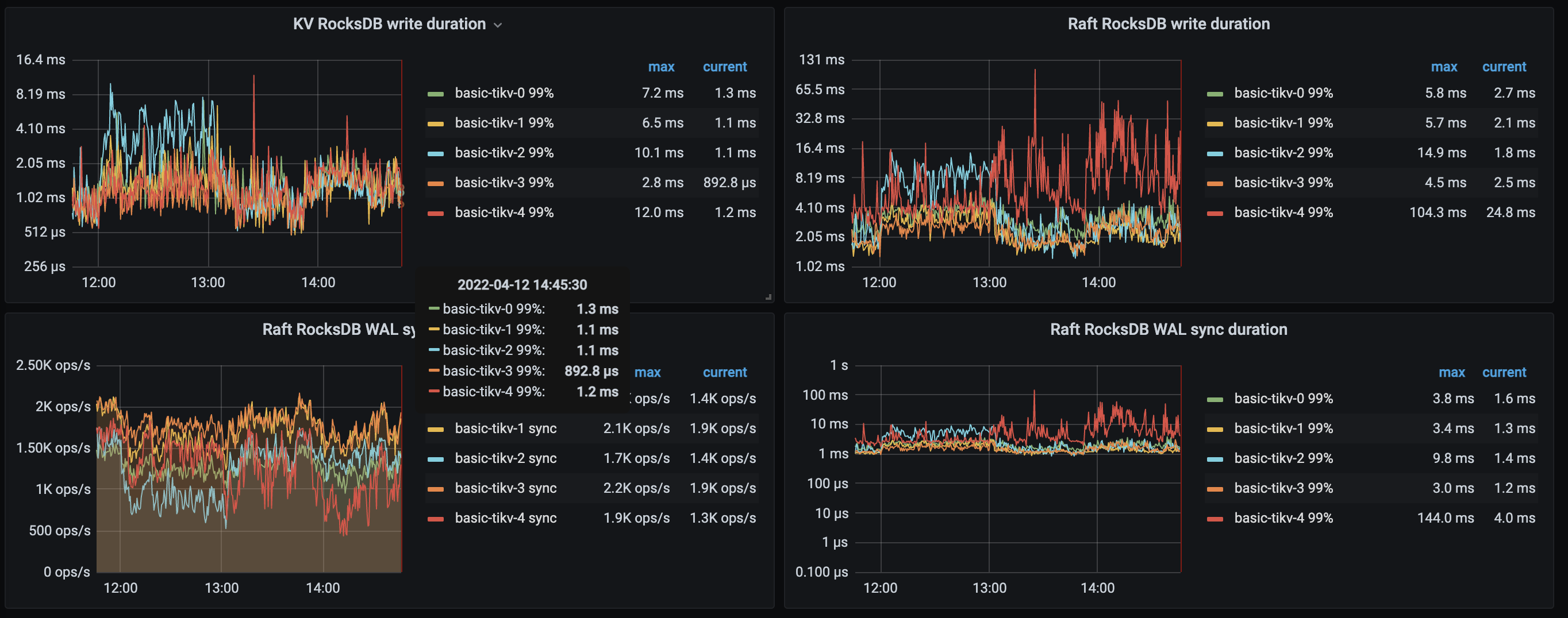
从上面的热力图看到,有一条明亮的斜线,可以确认是否写流量以及跟大字段所在的表或索引有关
https://docs.pingcap.com/zh/tidb/stable/dashboard-key-visualizer#明亮斜线需要关注业务模式
上面的监控,一开始是 basic-tikv-1 相关 duration 较高,后面转移到 basic-tikv-4 这个新扩容的 tikv,可能与热点分布有关,可以查询 tidb_hot_regions 确认是否写热点 https://docs.pingcap.com/zh/tidb/stable/information-schema-tidb-hot-regions#tidb_hot_regions
3 个赞
您好,热力图是最开始使用自增主键会有,之后修改为了AUTO_RANDOM。这边把慢的节点下掉了之后观察了7 8 个小时了,数据库整体RT好了几倍,也没有拖慢整体响应的tikv节点出现,所以感觉不像是热点而是这个慢节点 raft 有什么问题,而且从PD这边的监控来看各个store的流量是差不多的。目前不确定之后扩容会不会有新的慢节点出现(之前是有这个现象)。