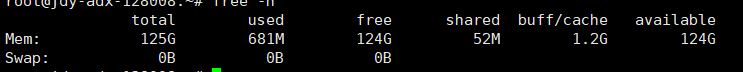v4.0.8
扩容 tidb pd 节点,分别放到两台服务器
服务器 A :tidb + pd
服务器 B : tidb + pd
扩容后,全是 DOWN 状态
进入 tidb 目录下,手动执行 run_tidb.sh ,报错如下,在服务器A B 都是这样的报错

在扩容配置文件中新增配置 tmp-storage-path ,仍然报此错误

v4.0.8
扩容 tidb pd 节点,分别放到两台服务器
服务器 A :tidb + pd
服务器 B : tidb + pd
扩容后,全是 DOWN 状态
进入 tidb 目录下,手动执行 run_tidb.sh ,报错如下,在服务器A B 都是这样的报错
在扩容配置文件中新增配置 tmp-storage-path ,仍然报此错误
这两个服务器上都仅有一个 tisb-server ?
目录有其他 tidb server 占用吗
对的,每个服务器仅有一个 tidb 一个 pd 一个 tikv 没有其他 tidb server 了
ls -l /data/tidb/tidb-deploy/temp/ 反馈下结果
https://github.com/pingcap/tidb/blob/master/util/disk/tempDir.go#L72
辛苦试下更换临时文件目录看是否会报冲突, 可以直接在 conf/tidb.toml 中修改, 使用 run_tidb.sh 进行启动看下
mkdir /data/tidb/tidb-deploy/temp_bak
PS: 后面在用 reload 统一管理参数.
这个报错很明显了吧,自行解决下
我明白了,这个是因为我扩容的时候,其实端口已经起起来了,再次执行 ./run_tidb.sh 自然会报端口冲突和目录被占用了。
现在的问题是 tiup cluster reload tidb-test -R tidb 我使用这个命令重启节点,没有报任何错误,tidb.log 也正常,但使用 tiup cluster display tidb-test 查看一直是 DOWN 的状态,我该如何排查这个问题?
指的是,./run_tidb.sh 之后,进程有,再次执行该脚本就出现端口的问题?开始目录冲突也是因为这个问题?
登陆下远程服务器 kill 下服务,再通过 tiup 操作下。
我描述一下完整步骤:
1 tiup cluster scale-out tidb-test scale-out_tidb.yaml --user root -p 扩容操作成功
2 tiup cluster display tidb-test 查看状态为 DWON
3 执行 ./run_tidb.sh 报错目录冲突
4 修改 conf/tidb.toml 修改目录路径,再次执行 ./run_tidb.sh 报错端口冲突
5 到这个时候 我明白了,其实第一步扩容操作后,4000 端口已经起来了,所以后面执行 ./run_tidb.sh 会报错目录文件被占用和端口冲突
你好
从 9 开始排查。
手动执行 systemctl start 看 log 是否有报错
执行 ./script/run_xx.sh 看 log 是否有信息,否则可以将 run_xxx.sh copy 一份,将其中的 --log-file 和 2>> 所在行去掉,手动执行这个 sh 脚本,将 log 输出到屏幕中,看具体的信息。
检查 message 中是否有详细的信息。
非常抱歉,楼上的办法也是比较有效的处理问题的方式,后面遇到问题可以尝试下,实践的比较多,基本可以定位这个启动的问题。
上面问题可以提供完整的日志看下吗。
非常感谢。线上环境,比较着急,打扰了。
我详细描述一下目前的情况:
原有单机房集群:
pd: 172.22.248.86 172.22.248.85 172.22.248.102
tidb: 172.22.248.86 172.22.248.85 172.22.248.102
tikv: 172.22.248.86 172.22.248.85 172.22.248.102
目的实现双机房
扩容机器 10.248.128.7 10.248.128.8
扩容 tidb 节点:10.248.128.7 10.248.128.8
先执行了扩容操作,节点状态 DOWN , 再执行 reload -R tidb,下面的日志就是这两步操作的日志
7-tidb.log (20.3 KB) 8-tidb.log (20.5 KB)
服务器配置多少,感觉没有输出 error 日志就退出了。之前单机房架构为 3/3/3 的模式,因为 tikv 对服务器的配置有一定要求。建议架构调整为 tikv 单独使用服务器,tidb 和 pd 如果服务器资源紧张可以共用。
dmesg -T | grep tidb-server 看下
架构疑问:
第二个机房仅仅部署 tidb-server 是吗?
那请关注下两个机房的网络情况,
架构方面可以参照:https://book.tidb.io/session4/chapter4/multi-data-center-solution.html
感谢。先解释一下:
之前单机房架构 3/3/3,第二个机房是打算同时部署 tidb-server pd-server tikv-server cdc 的,但是目前同时扩容几个组件问题太多了,所以我一个个组件来扩容,现在在第二个机房仅部署 tidb-server。
我有个疑问:tikv 是用来存储的,为啥对服务器的配置要求更高呢?我理解 tidb 计算较多,应该是对配置更为严格一点?
在第二个机房两台机器(7 8 )上执行 dmesg -T | grep tidb-server 无结果
![]()
![]()
第二个机房两台机器:
https://docs.pingcap.com/zh/tidb/stable/hardware-and-software-requirements
https://docs.pingcap.com/zh/tidb/stable/predicate-push-down
非常感谢你的反馈。
手动执行 systemctl start 看 log 是否有报错
执行 ./script/run_xx.sh 看 log 是否有信息,否则可以将 run_xxx.sh copy 一份,将其中的 --log-file 和 2>> 所在行去掉,手动执行这个 sh 脚本,将 log 输出到屏幕中,看具体的信息。
检查 message 中是否有详细的信息。
辛苦看下屏幕输出,仅仅执行一个 tidb 即可。
1 手动执行 systemctl start
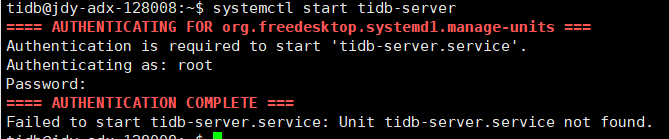
2 执行 ./script/run_xx.sh
3 Kill 掉进程
4 重新执行 ./script/run_xx.sh,无响应
5 将 run_xxx.sh copy 一份,将其中的 --log-file 和 2>> 所在行去掉,并在 tidb.toml 中重新设置新的 tmp-storage-path,然后手动执行这个 sh 脚本,将 log 输出到屏幕中,日志见附件日志打印到控制台信息.txt (13.1 KB)
6 再次 Kill 掉进程,重复 5 中操作,执行结果见附件日志打印到控制台信息2.txt (7.4 KB)
[2020/12/07 12:41:45.753 +08:00] [FATAL] [terror.go:257] [“unexpected error”] [error=“listen tcp 0.0.0.0:4000: bind: address already in use”]
检查下 4000 端口?
运维基础哈,tidb 用户权限问题,加上 sudo 即可
你的启动感觉都有这个问题,我认为是你的环境没清理干净, 执行前用 sudo ststemctl stop 停止下进程,.service 会有 restart=always 设置,需要注意。
尝试 kill -9、或者 sudo ststemctl stop