TiUP 使用常见问题处理
背景
以往 TiDB Cluster 安装,因为 Ansiable 的复杂性总有这样或者那样的问题,导致很多小伙伴不能畅快的使用 TiDB Cluster。随着 TiDB 4.0 版本的 GA,新一代的包管理工具应运而生。TiUP 不仅继承的 tidb-ansiable 中的所有主要功能,还集成了其他 N 多功能。诸如体验环境搭建、DM 部署、集群检查、TiDB 集群版本维护等等,最最核心的升级改变,是把原来在 TiDB-Ansible 中诸多的安装部署命令,统一集成为一条简单的 deploy 命令,喝口茶的功夫,TiDB Cluster 集群已经安装部署完毕了,同时你还可以在一台中控机上管理 多套 TiDB 集群。相比之前,极大地降低了使用者安装、部署、管理的难度。
本文对 TiUP 使用过程中的一些常见问题进行整理,希望帮助大家快速适应这个新工具。
tiup 基础环境准备
- 保证
TiUP中控机到TiDB和组件远程服务器,免密互信 - 强烈建议关闭防火墙和
selinux TiUP修改参数入口推荐使用tiup cluster edit-config--force命令比较危险,需要谨慎操作- 使用该选项强制移除正在服务和下线中的 TiKV / TiFlash 节点时,这些节点会被直接删除,不等待数据调度完成,因此这个场景下存在较大概率丢失数据的风险。不建议对未宕机的节点使用该选项。
- 尽量保持
TiUP和TiUP各组件为最新版本 - tiup 目前会有版本提示,关注
“Found cluster newer version”字样即可。 "Imported":true参数不需要手动配置- 要想使用离线环境,必须构建 TiUP 离线包。不可对在线 TiUP 包关闭网络当作离线环境使用,截止到发稿,两套环境不可通用
通用问题处理
1 tiup 报错:Process exited with status 1
关键信息:
Process exited with status 1
InstallPackage
报错信息:
tiup debug log 最后一行:
2020-07-08T14:19:11.176+0800 INFO Execute command finished {“code”: 1, “error”: “Process exited with status 1”, “errorVerbose”: “Process exited with status 1
github.com/pingcap/errors.AddStack
\tgithub.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/errors.go:174
github.com/pingcap/errors.Trace
\tgithub.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/juju_adaptor.go:15
github.com/pingcap/tiup/pkg/cluster/task.(*InstallPackage).Execute
\tgithub.com/pingcap/tiup@/pkg/cluster/task/install_package.go:45
github.com/pingcap/tiup/pkg/cluster/task.(*CopyComponent).Execute
\tgithub.com/pingcap/tiup@/pkg/cluster/task/copy_component.go:46
github.com/pingcap/tiup/pkg/cluster/task.(*Serial).Execute
\tgithub.com/pingcap/tiup@/pkg/cluster/task/task.go:189
github.com/pingcap/tiup/pkg/cluster/task.(*Parallel)Execute.func1
\tgithub.com/pingcap/tiup@/pkg/cluster/task/task.go:242
runtime.goexit
\truntime/asm_amd64.s:1357”}
解决办法:
检查 /tmp 目录磁盘空间是否不足。
排查思路:
关注到,堆栈上面是在 install package 的时候失败,install package 就是把升级包 ssh copy 到远程服务器。
延伸:
此类没有详细报错内容的问题,可以先检查下
-
/tmp 磁盘空间是否不足
-
检查 /var/log/message 是否有 tiup 相关报错信息
-
使用 tidb 用户手动 scp 将 installPackage 传输到 deploy dir 看是否成功。
- 可以排查上层目录的权限问题
- 可以排查部署空间问题
- 可以排查密码过期问题
- 一般会有类似报错:WARNING:Your password has expired
-
df -ih 检查 inode 是否满了。
2 执行 tiup destroy 失败,报错:xxx faild to stop:timeout waiting for port xxx to be stopped after 1m0s
排查过程
- 检查出错节点端口是否存在,
ss -ltn,确定关闭之前需要确认是否为当前集群的服务,避免影响其他集群。 - 检查出错节点服务是否存在,有则可通过
systemctl关闭,或者kill - 可以使用
--wait-timeout参数增加等待时间
延伸
- tiup destroy 时会检测端口是否关闭,如果该端口一直被占用,将会失败,即使该端口运行着与
tidb无关的服务。 - 此类
timeout问题,都可以采用这种办法,将tiup屏幕输出的命令到远程服务器上去执行,看是否报错。
3 tiup cluster display 结果与节点实际服务运行状态不相符
问题描述:
tiup cluster display 结果与节点实际服务运行状态不相符
排查过程:
- 检查中控机与
tidb其他节点服务器防火墙是否开启了
延伸:
- tiup 各组件状态通过
pd-ctl或者节点的 status 端口是否可以访问 - tiup 为包管理工具,此问题可以使用
pd-ctl(tiup ctl pd -u)查询节点状态是否正常
4 集群内 tikv 磁盘损坏,如何缩容该 tikv
问题描述:
tikv 磁盘损坏,想要缩容该 tikv
解决办法:
使用 tiup cluster scale-in xx -N 127.0.1.1:2379 --force
扩展:
此类网络无法到达,磁盘无法损坏无法访问等错误都可以使用 --force 命令强制下线该节点。
5 TiUP 执行命令报错:unable to authenticate, attempted methods [none publickey]
此报错可能出现在 TiUP 一些运维命令中,该错误是由于找不到连接到远程主机的 SSH 私钥导致的
解决办法:
使用 -i 正确指定私钥位置,或者通过 -p 的输入远程服务器的密码。
扩展:
- 如果没有指定
-i参数,可能是由于 TiUP 没有自动找到私钥路径,建议通过 -i 显式指定私钥路径。 - 如果指定了
-i参数,可能是由于指定的私钥不能登录,可以通过手动执行ssh -i identity_file user@remote命令来验证。 - 如果是通过密码登录远程主机,请确保指定了
-p参数,同时输入了正确的登录密码。 - 在大多数云环境中,root 密码不尽相同,需要手动配置 ssh,保证 tiup 中控机的 tidb 用户(如果希望通过非 root 用户运维的话)到各个节点的 root 可免密登录,tiup 在 deploy 阶段会根据 topology 中的
user创建并赋权启动 service 的账号。
6 TiUP 扩容节点报错:Error: init config failed: {IP}:{PORT}: read manifest from mirror(https://tiup-mirrors.pingcap.com/) failed: checksum mismatch, expect: xxxxx, got: xxxxx
此报错为 tiup 在 publish 镜像
解决方案:
一般可以稍后再进行尝试,紧急可以在 AskTUG 开帖,会有值班人员处理。
7 failed to scale in:server error:invalid nodeID xxxx
解决办法:
- tiup cluster restart -R pump (重启后 show pump status 应该多了 N 个使用 ip 的 不同 nodeid 的 pump)
- tiup cluster scale-in … --force 下掉全部 pump (下单个 pump 保证 drainer 拉去数据完整性的时候不能使用 force)
- 修改全部状态非 offline 的 pump 为 offline: ./binlogctl -cmd update-pump -node-id -state offline
延伸:
系列问题
tiup cluster import 问题:
-
invalid cross-device link
- tiup cluster list 查看 import 是否有残留的集群信息,先清理干净(rm -r /home/tidb/.tiup/storage/cluster/clusters/集群名称);然后执行 tiup cluster --no-backup -d /home/tidb/tidb-ansible 然后 tidb-ansible 目录和 .tiup dir 不在同一个磁盘分区的问题
-
Error: remove /home/tidb/tidb-ansible: directory not empty
- 可以忽略此报错,import 已经成功,使用 tiup 管理集群,不要再使用 ansible.
- 可以尝试重复导入的集群,直接删除 ~/.tiup/storage/cluster/clusters/ 下面对应集群名的目录来清除,重新执行 import -d 即可
-
Error: can not detect dir paths of tiflash 192.168.1.1:9000, grep: /etc/systemd/system/tiflash-9000.service: Permission denied
-
/etc/systemd/system权限需要755-
grep cat 等,ssh 文件操作出现权限问题先检查部署用户
- 譬如 tidb 是否已经免密互信并由 sudo 权限。
-
-
通过 ssh 到远程服务器,检查是否可以执行报错语句
- 排除 tiup 本身的问题。
-
检查文件和上层目录权限,tidb 用户是否可以访问
- 通过
/var/log/message确认是否目录权限问题.
- 通过
-
-
import 过程中报错提示输入密码
- 检查 ~/.tiup/storage/cluster/clusters//ssh/id_rsa 权限是否为 600,若不是请升级 tiup 组件到 v1.2.1 以上来解决此问题,关联 PR Fix copy file without mode by lucklove · Pull Request #844 · pingcap/tiup · GitHub
-
import 后的集群通过 tiup-reload 报错:failed to scp xxx to xxx Process exited with status 1
- 问题原因:原集群使用 ansible 部署,不同 host 配置不同 monitored 目录后,TiUP import 后,不支持 host 级别配置 monitored,所以会有这个问题
- 解决办法:
- 先把旧的 node_exporter 和 blackbox_exporter 停掉
- tiup cluster exec cluster-name -command=“systemctl stop node_exporter-”
- tiup cluster exec cluster-name -command=“systemctl stop blackbox_exporter-”
- 在 meta.yaml 中修改 monitored 的部署目录 B,(将部署机器上的目录 A copy 一份 B,copy 的目录和 meta.yaml 中的目录保持一致)
- reload 集群 tiup cluster reload {cluster-name}
-
node_exporter 和 black_exporter ./script/run_xx.sh 脚本中,可执行文件的路径不正确:
- 原因:tidb-ansible 和 tiup 的 run 脚本可是不同,tiup 的 run 脚本的可执行文件多了一层路径
- 解决方案:tiup-cluster v1.3.2 已经解决此问题;兼容性匹配,我们建议在 bin 下建立符合 run 脚本的目录结构即可,而不是去修改 run 脚本,因为一些 tiup 操作会刷新这个脚本。
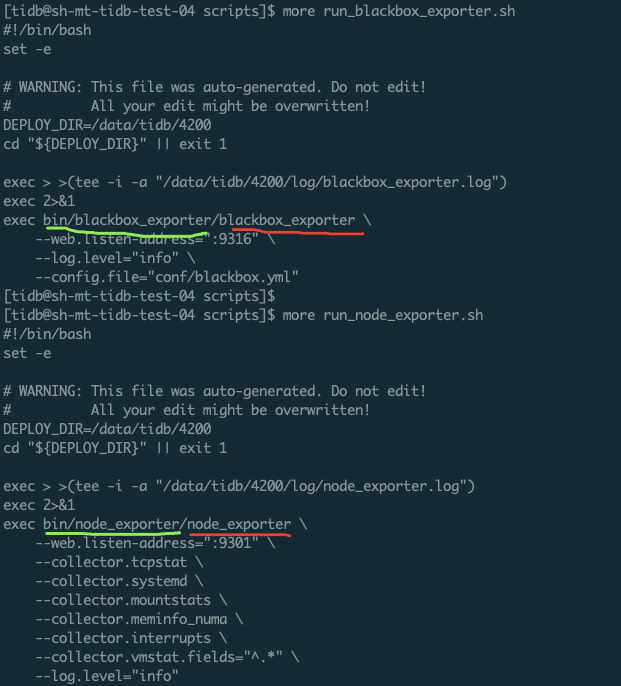
tiup cluster deploy 问题:
-
sudo:抱歉,您必须拥有一个终端来执行 sudo
- 完成 sudo 免密操作
-
Failed to initialize TiDB environment on remote host ‘10.10.xxx.51’
(类似问题「caused by: Failed to create ‘~/.ssh’ directory for user ‘tidb’」).ssh目录权限744,authorized_keys文件权限600- 用户添加
sudo权限 - 确定免密配置好。使用密钥的,将中控机密钥 copy 到远程服务器
-
ssh:handshake failed:EOF
- 此问题一般为单机部署节点数过度,导致 ssh 失败
修改 /etc/ssh/sshd_config MaxStartups 的值 - or tiup cluster -c --concurrency int max number of parallel tasks allowed (default 5),此参数可能对 ssh 在每个节点的连接数有控制效果。最初的效果是在运维操作中能快速对同一个 roles 中的大量服务器同时发送 ssh。
- 此问题一般为单机部署节点数过度,导致 ssh 失败
-
pd-ctl store发现在现有集群有其他版本 store,可能是在同一个服务器上存在多用户的 tiup 中控,并出现了端口重复的现象,一般为新部署 pd 的 port 和该服务器的其他部署用户的 pd port 重复导致的。- deploy 时 tiup 实际检查端口冲突的范围仅限于
~/.tiup/路径下的部署集群 - 所以强烈建议大家如果有混合部署的需求,一定要在 deploy 前面执行 check 操作,检查实际的端口占用情况
- deploy 时 tiup 实际检查端口冲突的范围仅限于
tiup cluster upgrade 问题:
-
升级中断
- 确定升级中断原因,看失败节点 log 是否有有效信息
- 使用 tiup cluster restart -N -N 重启失败节点即可,无需重新执行 upgrade 操作。
-
node_exporter-9100.service/blackbox_exporter-9115.service 不存在:
- 当前可以考虑从其他节点 copy 监控信息:/etc/systemd/system/ : blackbox_exporter xx.service 和 node_exporter-9100.service /home/tidb/deploy/ deploy 目录下 copy 所有目录过来. 对比修改下内容。
download package 问题:
基础信息:
~/.tiup/storage/cluster/packages 目录是 deploy 下载的文件保存路径,可删除,可手动下载.
-
tar: Unexpected EOF in archive- 删除 ~/.tiup/storage/cluster/packages 内容,重新下载
-
tiup cluster deploy 出现 download error
- 检查数据源是否能访问:curl https://tiup-mirrors.pingcap.com
- wget https://tiup-mirrors.pingcap.com/{node-type}-{version}-linux-{os}.tar.gz 将其放在 ~/.tiup/storage/cluster/packages 目录并注意权限问题
参数配置问题:
-
tiup import参数不兼容问题。 -
arm平台使用 tiup 部署 tidb 集群- 在 tiup cluster deploy 执行之前,topology 文件中添加:
arch: "arm64"
- 在 tiup cluster deploy 执行之前,topology 文件中添加:
-
log directory shouldn’t be the subdirectory of data directory
- log_dir 和 data_dir 不可配置在同目录
-
Error:failed to parse topoloy file ./conf/scale-out.yaml(utils.topoloy.parse_failed cause by:yaml:unmarshal errors:line 3:key “binglog.enable” already set in map
- 删除
scale-out.yaml与edit-config重复参数
- 删除
tiup 各种 timeout 问题:
基本思路:
检查对应组件 log,看是否有详细报错信息
可以使用 --xxx-timeout 参数增加等待时间,尤其是 scale-in 和 scale-out 操作。
-
start timeout:
- 手动执行 systemctl start 看 log 是否有报错
- 执行 ./script/run_xx.sh 看 log 是否有信息,否则可以将
run_xxx.shcopy 一份,将其中的--log-file和2>>所在行去掉,手动执行这个 sh 脚本,将 log 输出到屏幕中,看具体的信息。 - 检查 message 中是否有详细的信息。
-
stop timout:
- 检查远程服务器该服务是否存在:端口(非 tidb 服务如果占用了此端口 tiup 也将 stop 失败)和进程都要看下。
- 手动停止在执行 stop 命令(
systemctl stop {service})看是否成功,目前 .service 文件都配置 Restart=always 参数,需要注意下。
-
destroy timeout:
- 检查出错节点端口是否存在,有则关闭,确定是否为 tidb 相关服务
- 检查出错节点服务是否存在,有则可通过
systemctl关闭,或者kill
签名问题:
为了方式重放攻击,对 TiUP 签名设置了过期时间。
-
签名过期 -
Error:manifest has expired at:2020-06-27T03:35:25Zrm ~/.tiup/manifests/*