jimmy
(Jimmy)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】: 最新稳定版本, 4.0.8
- 【问题描述】:
在做储存选型,股票K线的使用场景:
建表语句:
CREATE TABLE kline_m1 (
id bigint(32) NOT NULL COMMENT ‘主键ID’,
tickerId bigint(11) NOT NULL COMMENT ‘tID’,
tradeTime datetime NOT NULL COMMENT ‘交易时间’,
…
status varchar(2) NOT NULL COMMENT ‘状态’,
PRIMARY KEY (id),
KEY tickerId_tradeTime (tickerId,tradeTime)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
查询语句:
SELECT id, tickerid, tradetime, …, status
FROM kline_m1
WHERE tickerid = ? AND tradetime < ?
LIMIT ?
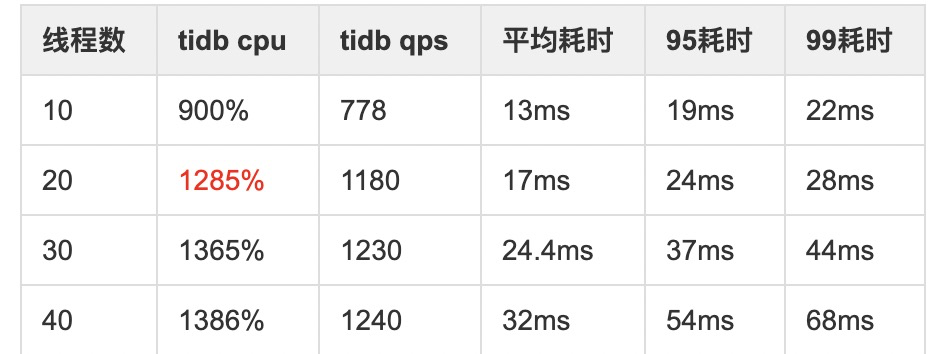
服务器配置: tidb: 16c64g,3台, tikv: 16c64g,3台, pd1台,如下图:
目前集群总的测试数据在60亿多点,其中的kline_m1表数据量20亿,从这张表查询,单次查询1000条数据,测试单台Ti-DB的qps在1200左右,
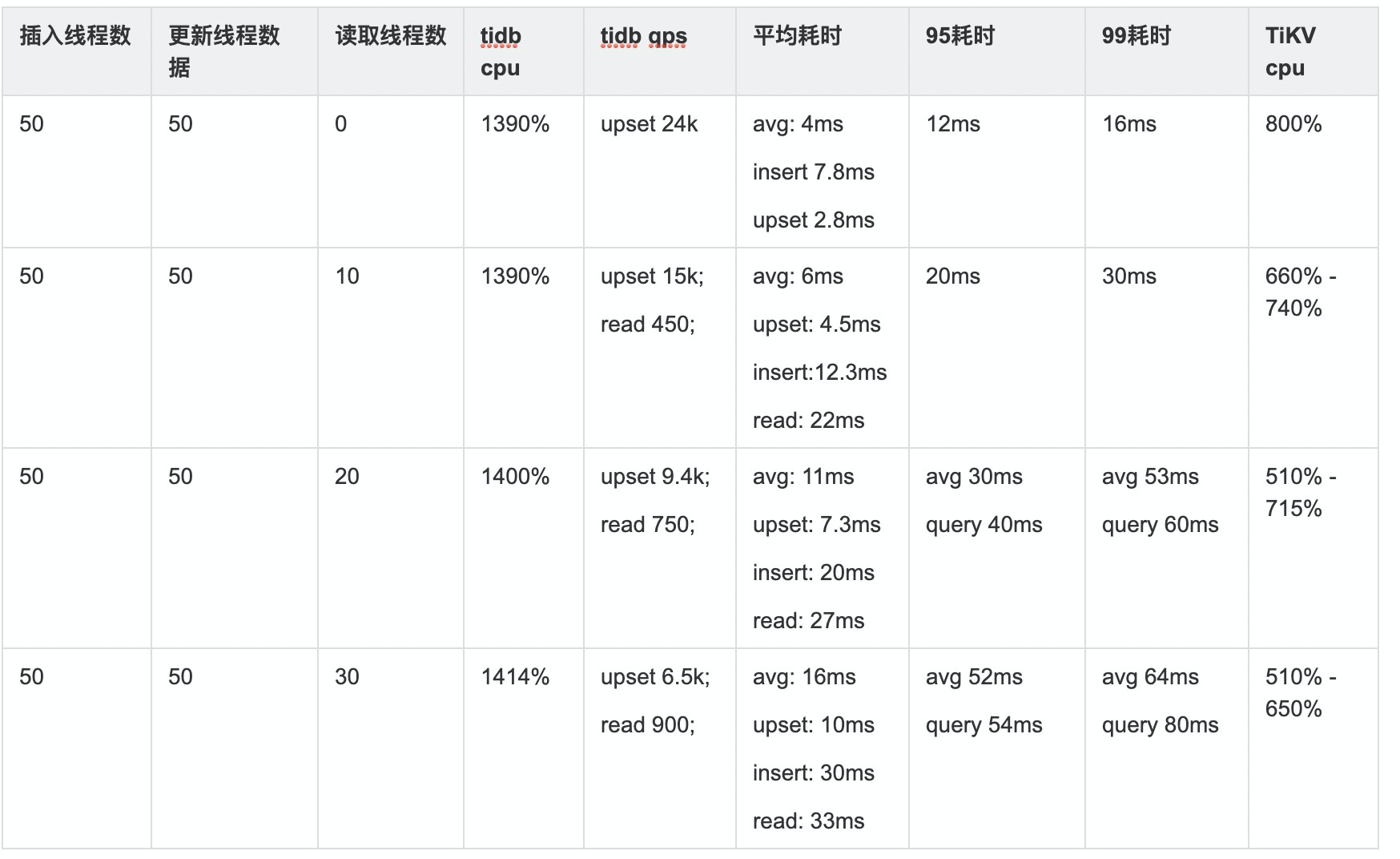
如果同时写入,
使用3台Ti-DB读写同时进行:【4台4c8g测试机,800线程写(插入),800线程读】
请问有谁有类似需求,一次需查询这么多条数的使用场景(如单次查询1000条数据),qps上是否还有提升的可能? 还是Ti-DB不适合这种股票K线的场景?还请大家指教。
jimmy
(Jimmy)
4
IndexLookUp_18,1.82,root,“”,“limit embedded(offset:0, count:1000)”
├─Limit_17(Build),1.82,cop[tikv],“”,“offset:0, count:1000”
│ └─IndexRangeScan_15,1.82,cop[tikv],“table:kline_m1, index:tickerId_tradeTime(tickerId, tradeTime)”,“range:[920000007 -inf,920000007 2013-02-16 05:09:54], keep order:false”
└─TableRowIDScan_16(Probe),1.82,cop[tikv],table:kline_m1,“keep order:false, stats:pseudo”
jimmy
(Jimmy)
6
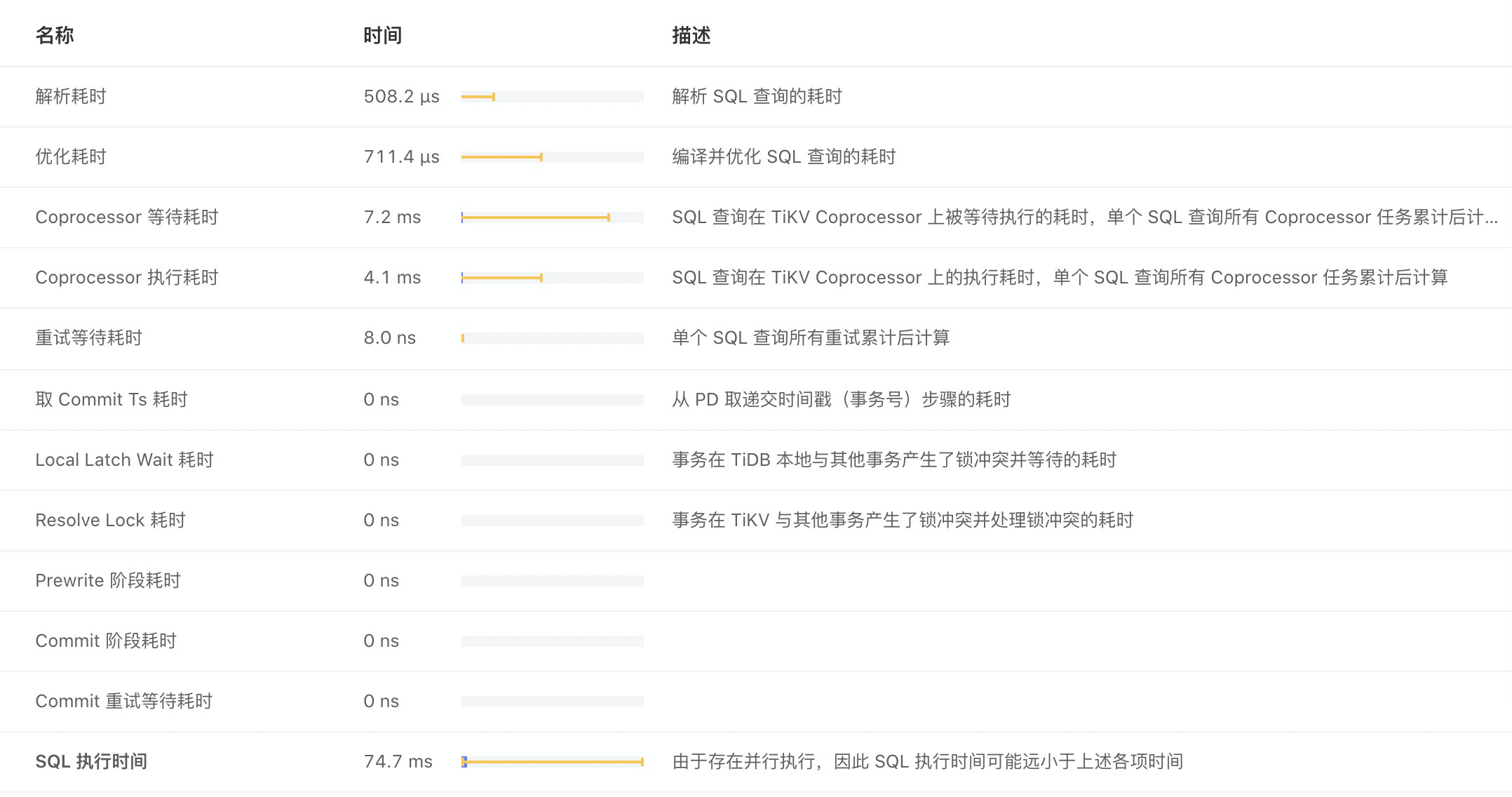
我理解的是limit下推到了tikv,先执行limit,走indexRange,也只需要扫前面1000条,范围对sql执行影响不大,对么?
jimmy
(Jimmy)
7
spc_monkey
(carry@pingcap.com)
8
1、上述描述的场景及 SQL ,tidb 是支持的,看执行计划也是没有问题的
2、另外麻烦提供一下集群架构拓扑图,看上面的资源使用情况,只有 tidb-server 及 tikv unified pool cpu 较高,资源还没有完全使用起来,怀疑并发数不够
3、看上面的需求,可以考虑把 table 及 索引打散一下
jimmy
(Jimmy)
9
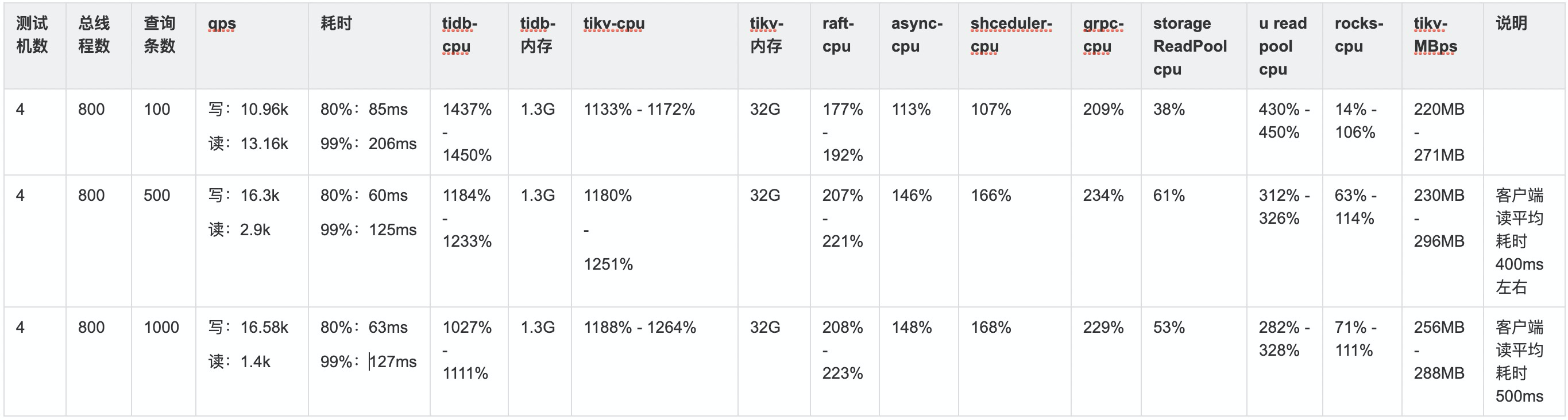
谢谢,tidb的cpu已经太高了,生产上面可能用到12核就会考虑扩容了。是要dashboard里面的存储拓扑图么? 我理解的3台tikv,数据都存储在3台上,每台一个数据的rockdb,不知道您说的“把 table 及 索引打散一下”是怎么打散?是说我根据股票id分不同的表后,根据存储规则,单表的region数就会少很多,就会更加分散些? 但总体来说取1000条是避免不了的。查询100条时性能是可接受的。
spc_monkey
(carry@pingcap.com)
10
1、不是分区表,是通过 split 命令把 可能出现的热点 region 进行拆分,然后充分利用多个节点上的资源,可以参考:https://docs.pingcap.com/zh/tidb/dev/sql-statement-split-region#split-region-的使用。另外建议看看官网上的《高并发写入场景最佳实践》
2、建议找一台配置稍微好点的服务器测试,其中 tidb-server 可以在一台服务器上部署2个,进行测试。另外,无论是 tidb 还是 tikv 都是可以通过扩容的方式来显著提高 QPS 的
jimmy
(Jimmy)
11
谢谢!关于热点,每条sql查询条件的股票id是随机选的,热点应该是不存在,这里可以看到:
然后服务器配置,现在3台tidb是16c64g的,tikv也是3台16c64g,pd只有一台,监控pd也是没有压力。测试机是4台4c8g的。
spc_monkey
(carry@pingcap.com)
12
ok,哪建议从 提高并发及扩容节点数量来提高 QPS,现在的瓶颈是资源上,不是数据库