zhuhedong
2020 年10 月 27 日 09:55
1
1.1亿的数据量, 有联合索引, 查询数据还是很缓慢, 走索引查询数据需要1s左右,查询1000条数据,
服务配置是 Tikv组件 6台 8H16G服务器, TIdb 是4台8H16G TIPD 为 两台4h8G服务器,
CREATE TABLE `dot_1` (
`mac` varchar(255) DEFAULT NULL,
`account_id` bigint(20) DEFAULT NULL,
`counter` bigint(255) DEFAULT NULL,
`offline` int(255) DEFAULT NULL,
`create_time_long` bigint(20) DEFAULT NULL,
`pen_type` int(255) DEFAULT NULL,
`page_id` bigint(20) DEFAULT NULL,
`message` varchar(255) DEFAULT NULL,
KEY `create_time_long` (`create_time_long`,`mac`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin/*!90000 SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=3 */;
SET FOREIGN_KEY_CHECKS = 1;
zhuhedong
2020 年10 月 28 日 03:55
5
SELECT mac,account_id, counter, offline, create_time_long, pen_type, page_id, message FROM dot_1
WHERE create_time_long >= 1603780219033 and create_time_long <= 1603784454927 AND mac = '10000000050F'
ORDER BY create_time_long
LIMIT 0,1000;
无标题.txt (1.5 KB)
zhuhedong
2020 年10 月 28 日 04:43
6
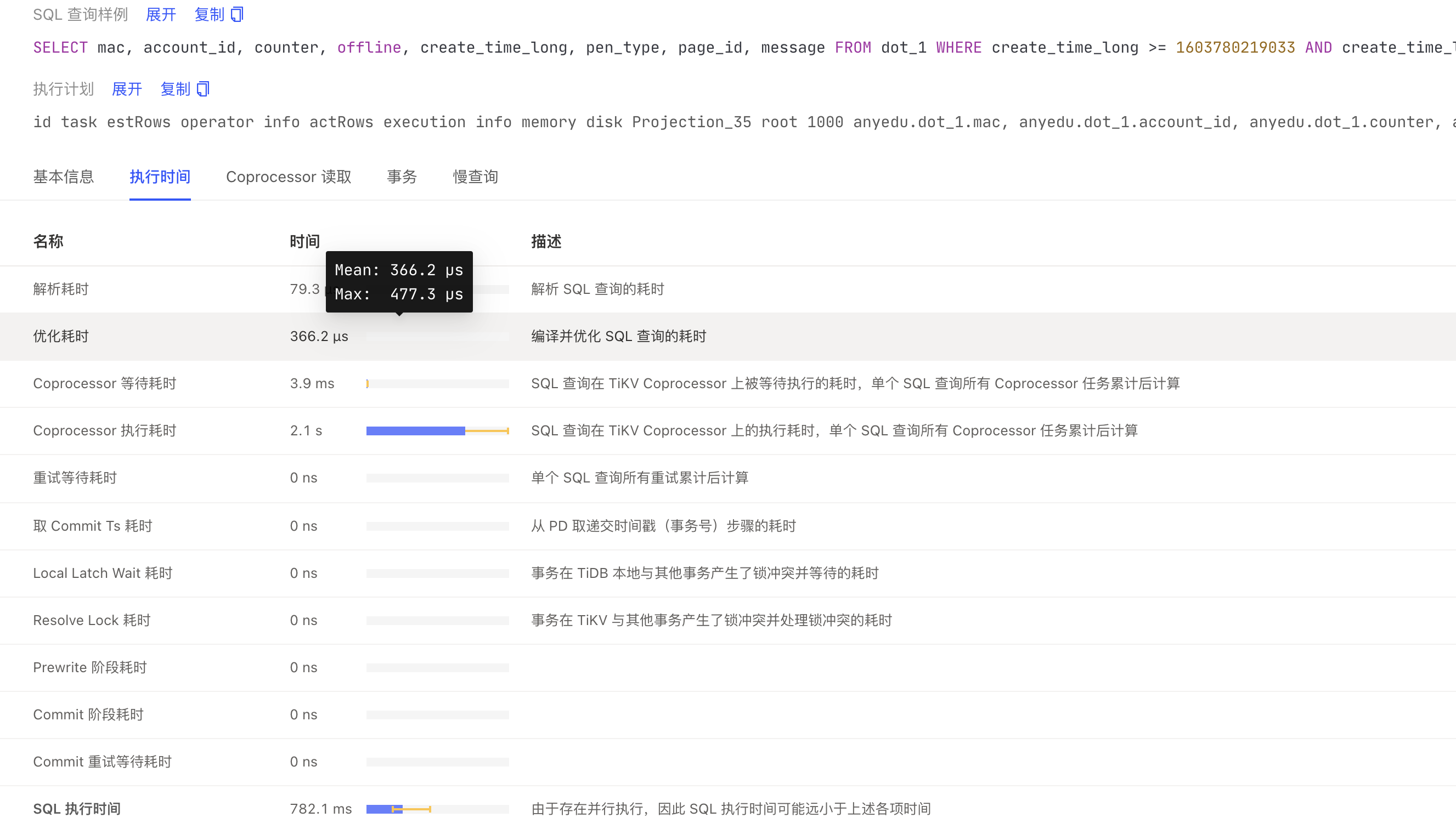
我调整了tidb_distsql_scan_concurrency,调到了100,好像没什么作用,
yilong
2020 年10 月 28 日 06:22
7
看时间 500 多 ms , 速度可以了。
zhuhedong
2020 年10 月 28 日 06:23
8
并不是每次都是500ms,现在1.8亿的数据在1~2s左右跳动
yilong
2020 年10 月 28 日 06:27
9
索引这里可以调整一下吗? mac 放前面,这样利用率会更高,不然只能使用creaetime了
zhuhedong
2020 年10 月 28 日 06:28
10
您是说新建索引的时候mac放前面,createTimeLong放后面吗
yilong
2020 年10 月 28 日 06:33
11
新建索引的时候,查询放前后不影响。 由于索引在选择的时候,你的第一列createtimelog是范围选择,所以后面的mac列无法使用。如果反过来创建索引,先查询mac等值,就可以继续使用createtimelog的范围列了。