spc_monkey:
topology
没有资源限制,集群是3.x升级到4.0的.
参数采取默认
资源消耗很低,但是很是有慢查
spc_monkey:
resource contorl
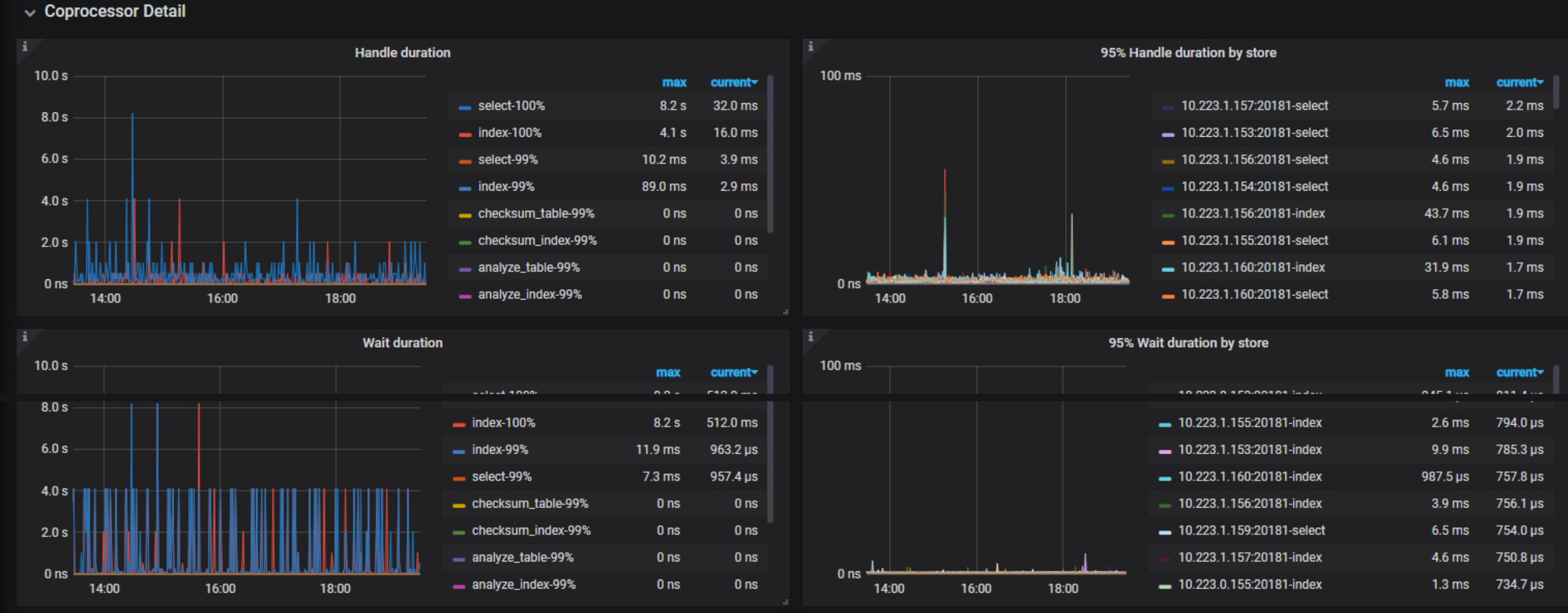
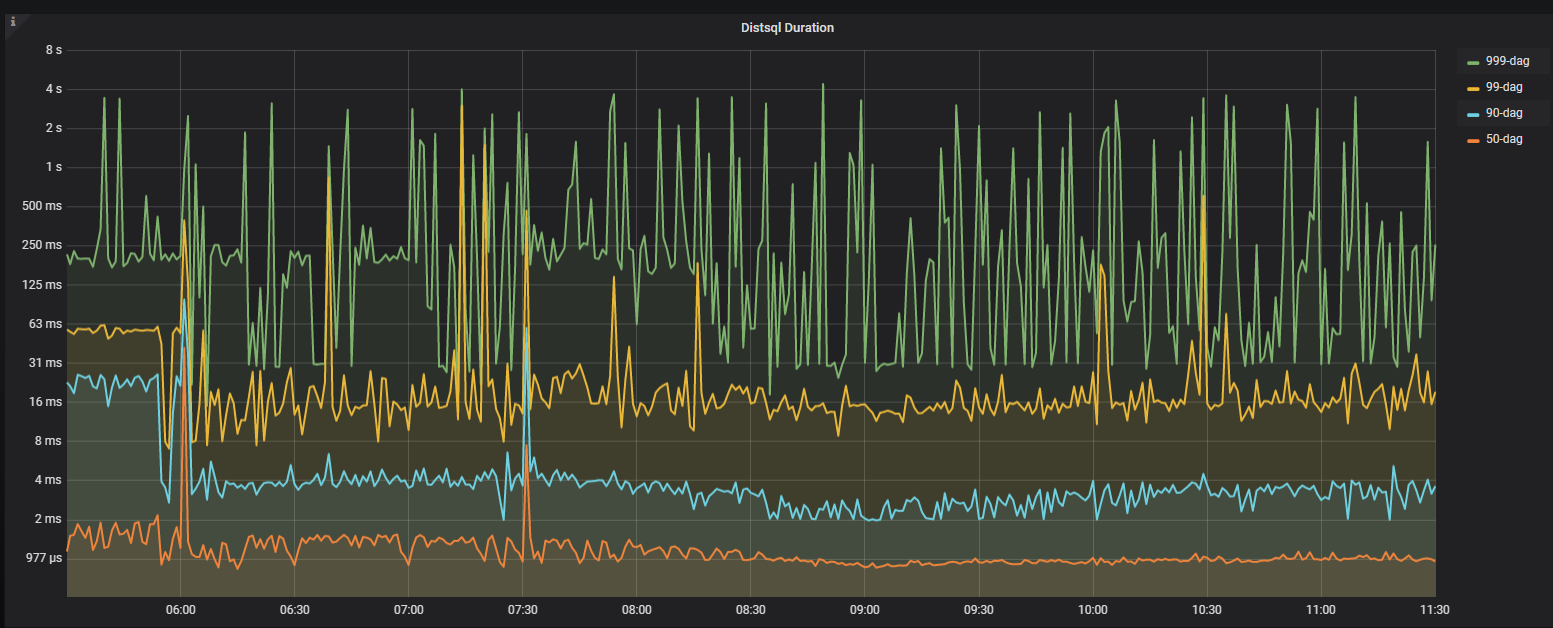
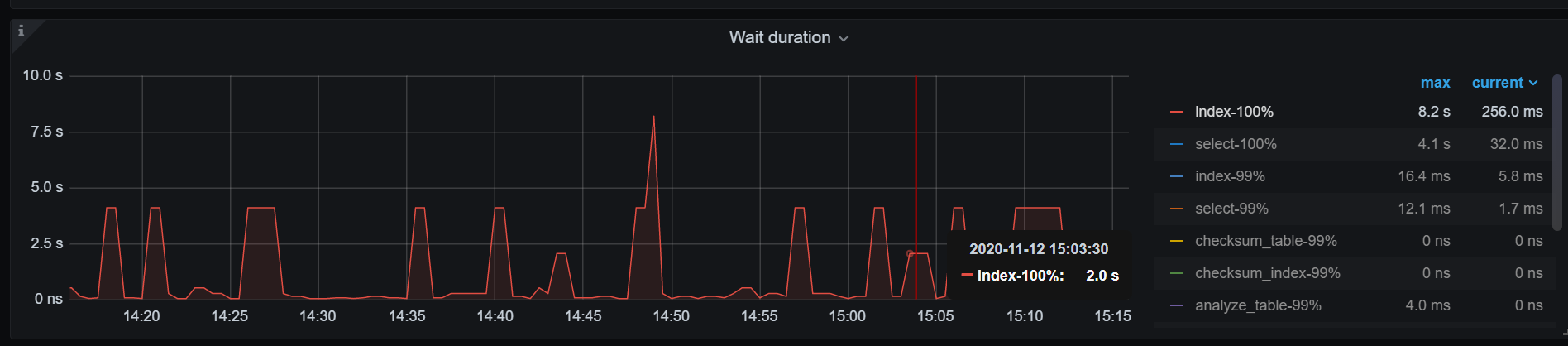
根据慢查的图观察, 和distsql duration 有很大相关性, 如下图这部分有相关优化参数建议吗
1 个赞
spc_monkey
2020 年11 月 9 日 03:40
28
1、建议还是看看对应时间,是否有较多的 慢 SQL,先优化这些 SQL吧
抓取了某个时刻的出现的全部慢sql,逐个分析,手动执行都很快, 程序里insert on duplicate语句比较多,
此外,可能还需要一些其它内容来辅助确认瓶颈是否为 I/O,并可以尝试调整一些参数。通过查看 TiKV gRPC 的 prewrite/commit/raw-put(仅限 raw kv 集群)duration,确认确实是 TiKV 写入慢了。常见的几种情况如下:
append log 慢。TiKV Grafana 的 Raft I/O 和 append log duration 比较高,通常情况下是由于写盘慢了,可以检查 RocksDB - raft 的 WAL Sync Duration max 值来确认,否则可能需要报 bug。
raftstore 线程繁忙。TiKV grafana 的 Raft Propose/propose wait duration 明显高于 append log duration。请查看以下两点:
[raftstore] 的 store-pool-size 配置是否过小(该值建议在[1,5] 之间,不建议太大)。
机器的 CPU 是不是不够了。
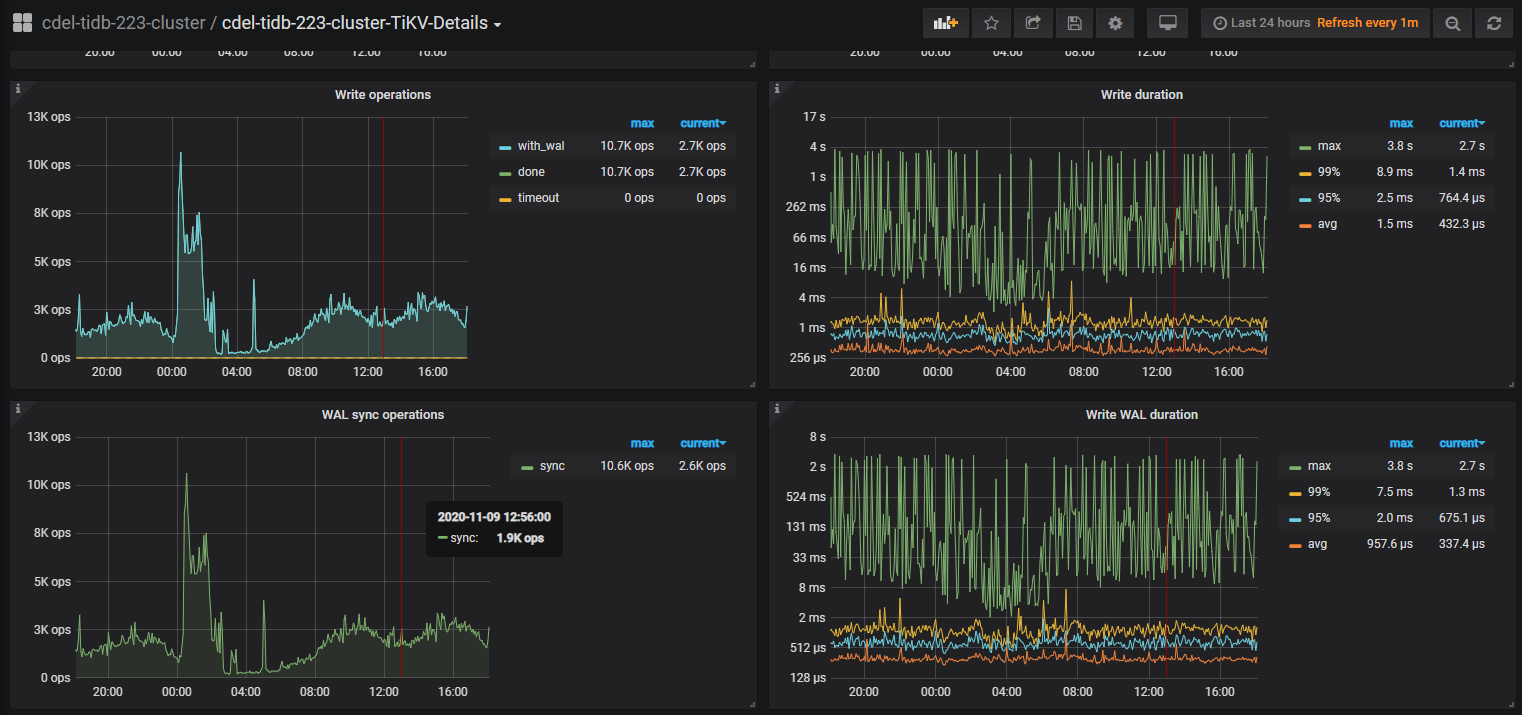
上面监控图write duration max执行慢的时候同样也是慢sql出现集中的时间
yilong
2020 年11 月 11 日 06:05
33
请 [FAQ] Grafana Metrics 页面的导出和导入 参考文档取over-view,tidb,detail-tikv 的监控,半小时包含慢的时间段即可
监控.rar (1.9 MB)
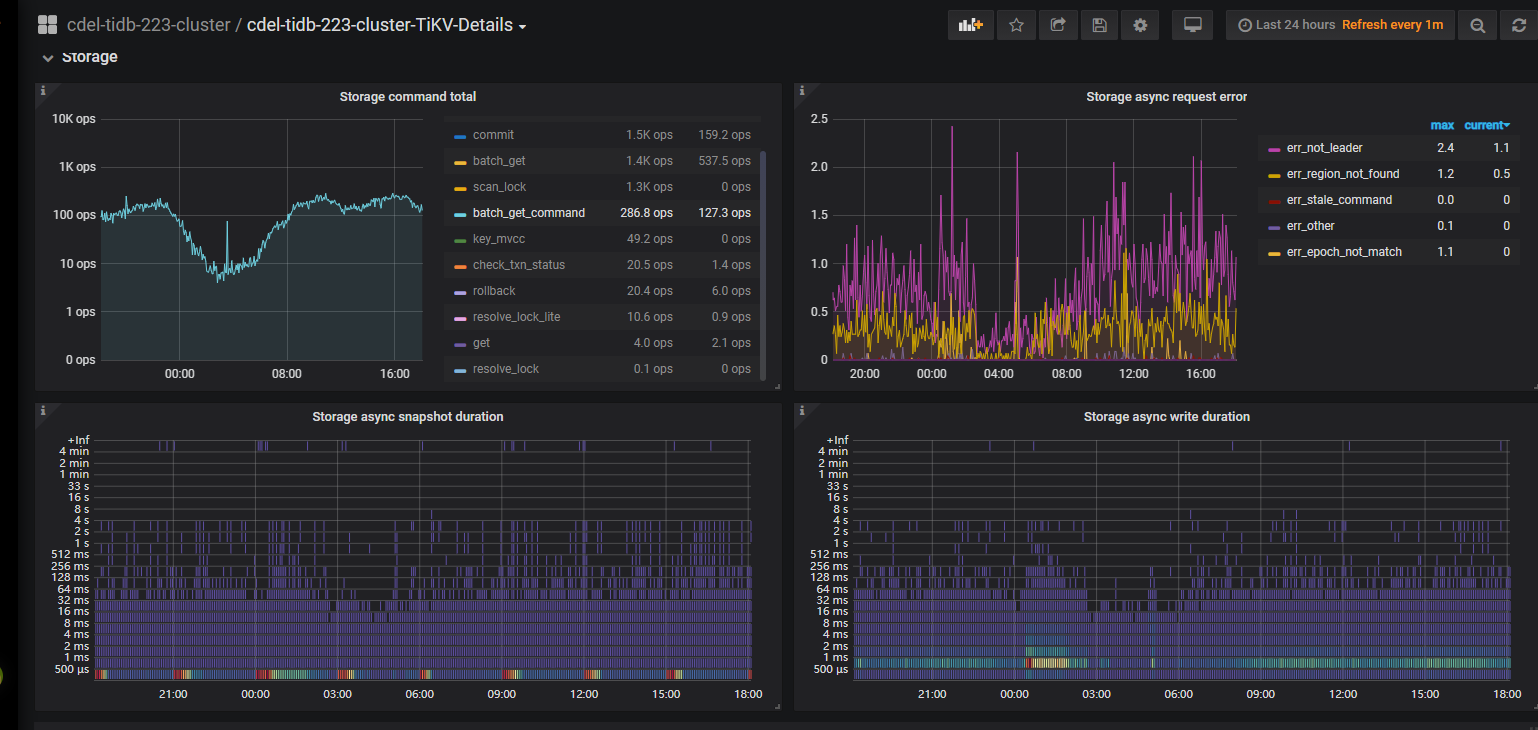
是这样的, 前面发的图是基于开始发的慢日志时间为10月26日,当时因为没有开启region merge ,后来尝试优化开启了, 目前空region已经由原来的10w降低到1万了, raftstore cpu也明显降低, 但是前文发的慢sql依然没有明显的去除,只是慢sql整体有一定的优化,
现在将最新的监控图上传, 也包含了前文开始部分的慢sql语句
其次: 开启跨表合并region的优缺点没有找到, 默认是false,目前无法确定开启是否有效, 还有大概1w的空region可能需要跨表合并开启才能继续合并
yilong
2020 年11 月 12 日 09:05
37
看之前的慢日志是 cop 慢,麻烦给一个刚才这个监控时间段内的对应慢sql日志,多谢。
Time: 2020-11-12T15:03:58.030880098+08:00
Txn_start_ts: 420784278504996906
Conn_ID: 2118223
Query_time: 1.35379208
Parse_time: 0.000109054
Compile_time: 0.001157552
Cop_time: 3.9936685990000003 Process_time: 0.006 Wait_time: 3.9779999999999998 Request_count: 14 Total_keys: 21 Process_keys: 14
DB: wk_bigdata_main
Index_names: [recommend_recall_user_history:PRIMARY,recommend_recall_user_history:PRIMARY,recommend_recall_user_history:PRIMARY,recommend_recall_user_history:PRIMARY,recommend_recall_user_history:PRIMARY,recommend_recall_user_history:PRIMARY,recommend_recall_user_history:PRIMARY]
Is_internal: false
Digest: 2f2e5d5437740781e46ee2b3db07ad720492b71e0137ceccc23ef199fca93288
Stats: recommend_recall_user_history:420784000658309153
Num_cop_tasks: 14
Cop_proc_avg: 0.000428571 Cop_proc_p90: 0.001 Cop_proc_max: 0.003 Cop_proc_addr: 10.223.1.159:20171
Cop_wait_avg: 0.284142857 Cop_wait_p90: 1.296 Cop_wait_max: 1.329 Cop_wait_addr: 10.223.1.159:20171
Mem_max: 28972
Prepared: false
Plan_from_cache: false
Has_more_results: false
Succ: true
Plan: tidb_decode_plan(‘vxzwPDAJM18yMgkwCTEJd2tfYmlnZGF0YV9tYWluLnJlY29tbWVuZF9yZWNhbGxfdXNlcl9oaXN0b3J5LmR0LCC2MgA8Y29uc3VsdHMKMQkxNV8yNdJ1AHg6ZGVzYywgb2Zmc2V0OjAsIGNvdW50OjEKMgk5XzI5BVQoCjMJM181NAkwCTC61QAMdWtleb7XAOoJARg0CTMwXzUzBak4bGltaXQgZW1iZWRkZWQoQuEANCkKNQkxNl81MgkxCTAJQh8AGAo2CTEzXzUhyBwwCXRhYmxlOnLAAZAsIHBhcnRpdGlvbjpwMjAyMDExMDUsIGluZGV4OlBSSU1BUlkoKQ9MZHQpLCByYW5nZTpbIjgyNTA0IiwNCExdLCBrZWVwIG9yZGVyOnRydWUsICGhAawMMF81MQWs5o4AHVxIZmFsc2UsIHN0YXRzOnBzZXVkbyXnADgpPraKAgnYtjQA/ucBADhhZQAwnucBADgpO1rnAQQ3Oe5ZAQA2/ucBOucBADjydQIANjJDAl7nAQQxMSk/trQB/ugBzugBBDExYaCi6QEEMTEpPlrqAQgxMDju6wEAN/7rATrrAQQxMPJ6AgA3luwBADQhQgAx/uwB/uwBjuwBADTBYwAxntUDBDEzIT4AMWLsAQgzNwlh99owBQA4/uwBPuwBADNBewAx6o8Air8FBDE3IUL+pwf+pweOpwcEMTYOXQim2AMANiE+YqkHCDE2Nu7YAwA5/uwBPuwBADZBe+I5CAA5ltgDADkpQv7EBf7EBYrEBQQ5OK6UCQQxOSk+XsQFBDk16uwBBDEw/uwBPuwBADnuewIBj4rYAwQyMilC/uwB/uwBhuwBCDIyN67sAQQyMik+WuwBCDIyNO7sAQAx/uwBOuwBBDIy8nsCADGC2AM=’)
Plan_digest: 339454275c344650f2707197ef08442ef2d885033b9c37285a4cb6eb72bfbff6
SELECT dt, consults FROM `recommend_recall_user_history` WHERE ukey = '82504' ORDER BY dt DESC LIMIT 1;
jiangdj1992:
2020-11-12T15:03:58
慢的原因还是 cop wait 耗时,麻烦拿下这个慢日志时间附近( 2020-11-12T15:03:58 前后10 分钟) 的 TiKV-Detail 的监控。 参考 [FAQ] Grafana Metrics 页面的导出和导入 参考文档取监控。
jiangdj1992:
Cop_time
也排查下当时是否有其他的大查询吧,可以用下面的 SQL 语句查询,按照 cop_time 的逆序排序:
select query,query_time,cop_time,digest from information_schema.cluster_slow_query where is_internal=false and time > '2020-11-12 14:45:00' and time < '2020-11-12 15:20:00' and cop_time > 1 order by cop_time desc;
集群没有明显的慢查, 但是命名应该很快的查询会慢, 这个比例目前大概在总量的千分之一
目前我这边根据监控看Propose wait duration 这个值明显偏高, apply log applend log都比较慢, 初步怀疑是否是raftstore 线程过低. 但是根据cpu反应最高值应该是 2*80% 即 160%才是阈值, 但是监控才到70%以下,目前想调整以下参数:
raftstore 的 cpu 才 70%, 不建议调大 raftstore.store-pool-size 参数了。 另外看下下面2个参数的值,目前是 256 吗?
[raftstore]
apply-max-batch-size
store-max-batch-size