现在的问题不是 coprocessor 慢了吗,先不要去查 raftstore 的问题。
select 查询的性能和 insert sql 的性能没有相关性
麻烦提供一下 thread cpu 的完整监控
是的这两个值都是256

因为目前都是cop_wait时间长, 是否有可能是其他原因(资源竞争,日志写的慢,等问题)导致查询处于 cop_wait状态耗费时间长
中间有一瞬间 unified readpool cpu 飙高,这个时间和 cop 查询慢的时间对得上吗
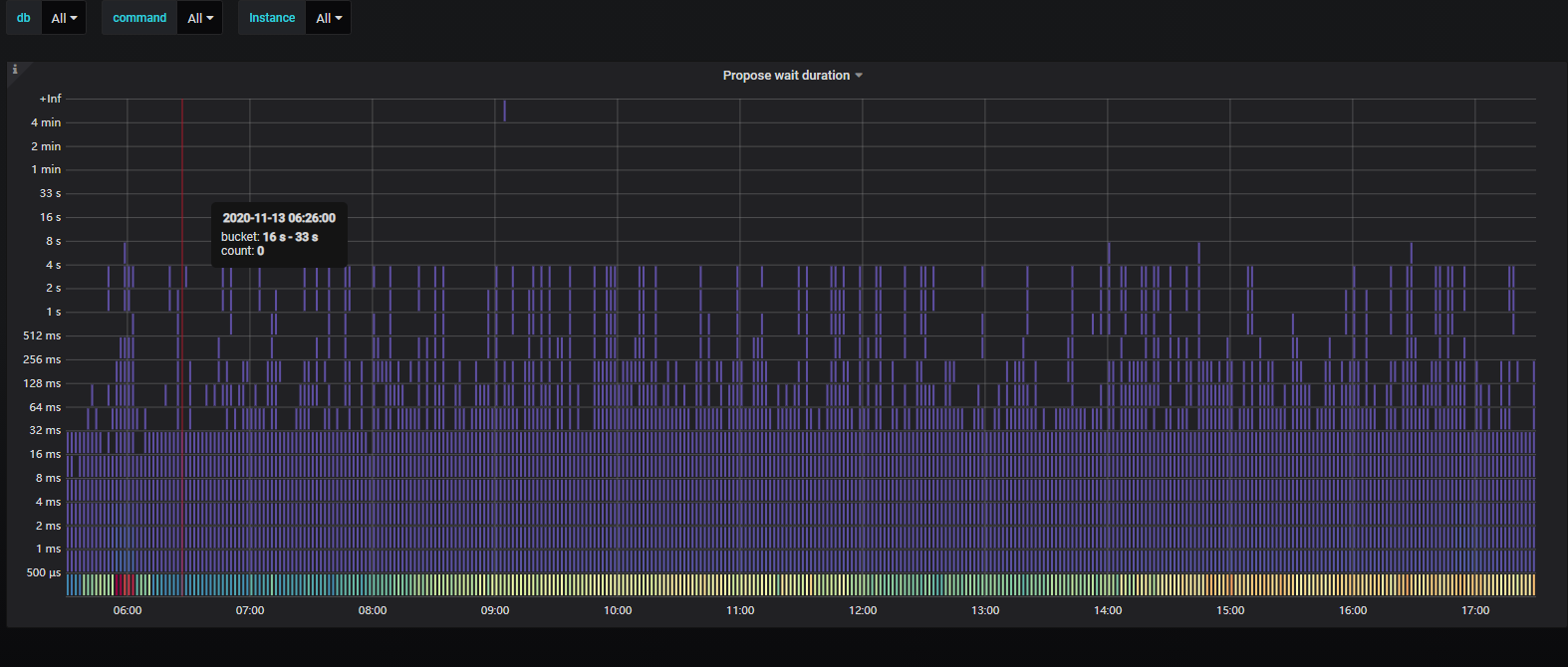
Propose wait duration 现在有多高。刚刚和同学确认了一下,cop wait 的时间会包括从raftstore 线程取 snapshot 的时间在内
中间那一段是凌晨跑数据导致的, 而现在的慢查一般处于1-4s之间, 并且是全天都有
1、能不能把上面 cop detail 里的指标(哪些明显超过秒级的指标),编辑一下(根据 instance 分组),查看一下是不是所有的实例,都这么高。现在的现象是 cop wait 较高,整体资源又不高的情况下,怀疑是不是其他的地方占用了资源
2、可以看看 read flow /write flow 及 compaction operation 等指标是否较高
3、另外,该 SQL 是全天24小时,每分组都会出现吗?能否关别集群调度 几分钟,看一下情况是否会又改善
另外,看看 node-exporter 下的监控指标,tidb-server 与几个 tikv 节点之间的网络是否良好。还有打开
use-unified-pool ,应该会缓解该情况的发生。
可以确认的是所有实例都是这么高, insert语句都会2-3s, 不只是这个sql. 关闭集群调度是指? 网络是良好的, use-unified-pool 因为是低版本升级上来的, 所以没有开启.我找个时间开启观察下
想确认个事情:低版本的时候,该 慢 SQL 也是和现在一样,经常出现吗?另外,gc 的时间,是什么时候调整的,可以找个时间,调整一下 gc 的频率
GC时间是在升级后几个月才调整的, 调整前都是默认10m0s, 因为我这边是从其他部门接手管理的, 接手过来就是刚升级完4.0版本. 慢sql应该是一直存在的, 但是本次反馈的慢sql是因为业务部门根据主键查询还要几秒钟, 占比大概1/1000的比例, 接受不了, 前期的慢sql,业务可容忍,没有过于关注
问一下,目前有没有尝试过调整 gc 的间隔及启动 unified-pool 看看效果?另外,上面其实发现集群写入速度应该也较慢,咱们有没有先尝试优化其他SQL 降低一下集群的负载情况