为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
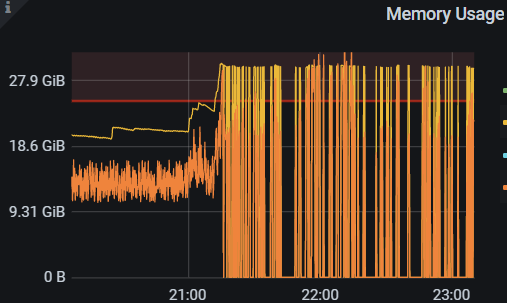
【背景】晚上21点会有任务 mydumper 进行数据库备份导出,导出报错。
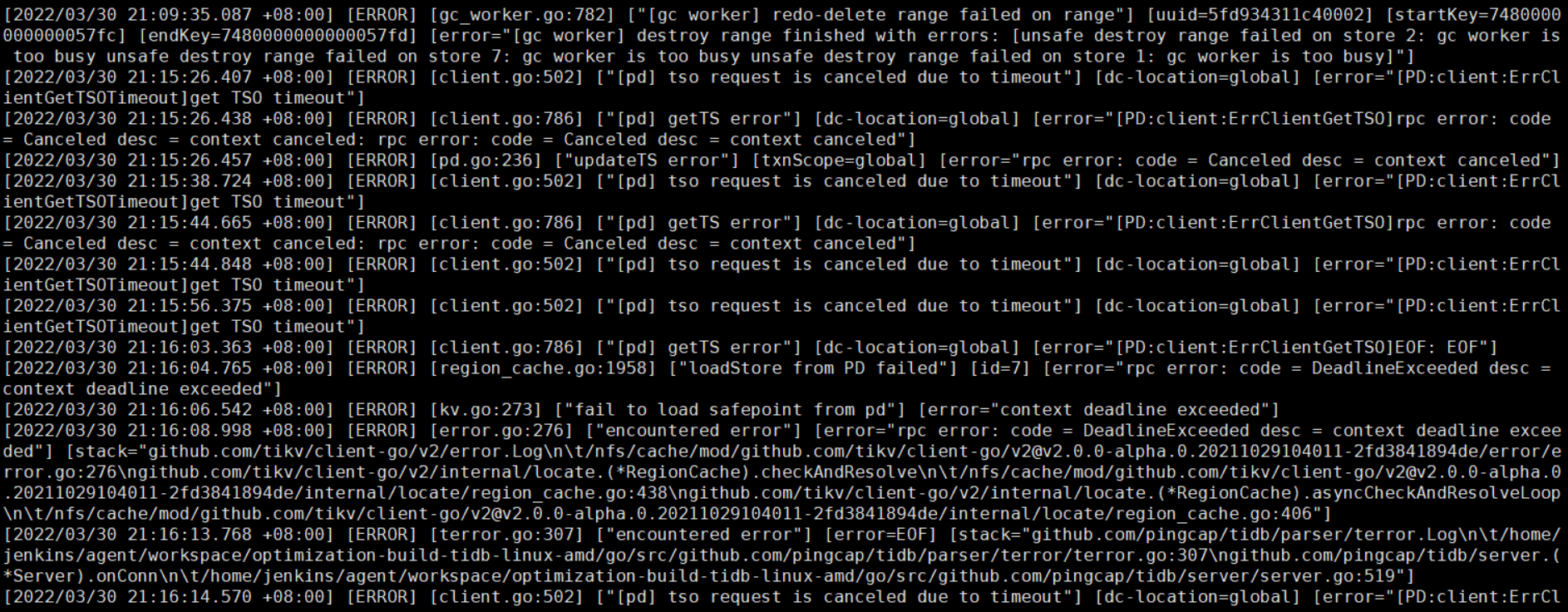
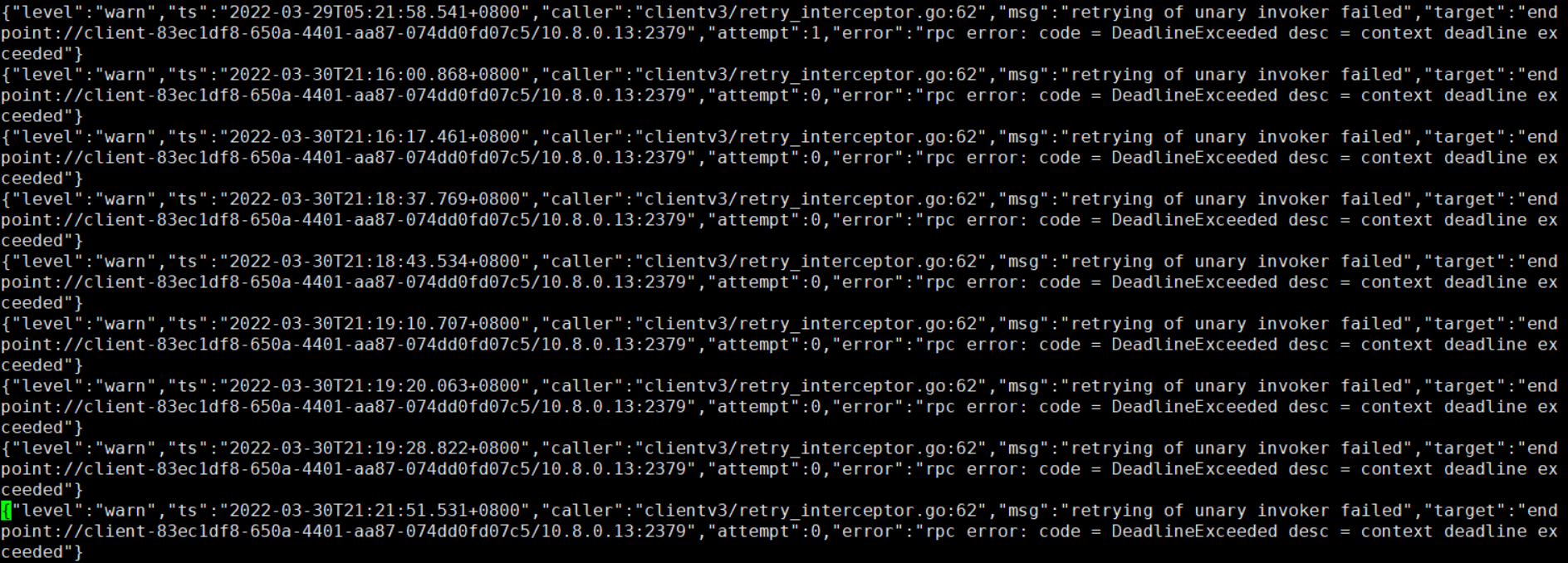
日志:
tidb_stderr.log:
tidb.log
tidb-0330.log (203.3 KB)
TiUP Cluster Display 信息
TiUP Cluster Edit Config 信息
TiDB- Overview 监控
1 个赞
[quote=“xfworld, post:2, topic:632813”]
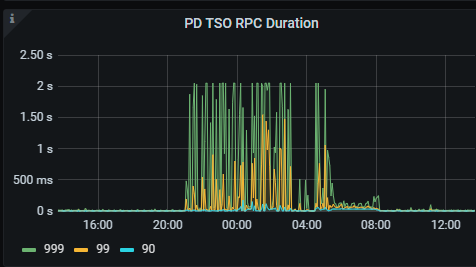
TiDB获取 TSO 的延时情况:
xfworld
2022 年3 月 31 日 06:08
5
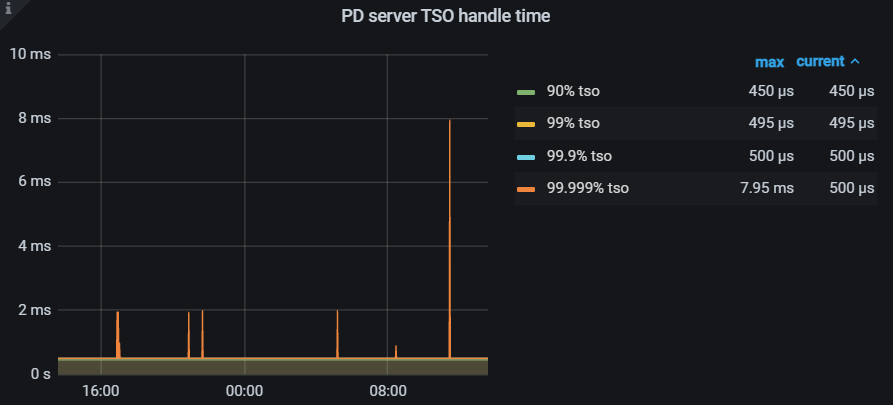
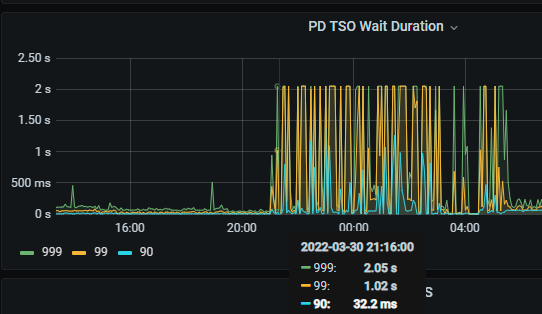
首先立马查看 PD TSO RPC Duration,其正常数值范围 80% 差不多在 1ms 以内,99% 在 4ms 内,如果数值比较高,则说明网络和 PD 的处理时间长(包括 Go Runtime 调度和实际 TSO 处理逻辑),此时继续看 PD server TSO handle time + Client revc time 是否慢,如果不慢则说明 PD TSO 处理(和发送)不慢,大概率是网络问题,需要往网络问题方向排查。
如果 PD server TSO handle time + Client revc time 慢:
如果是 v4.0.13 版本及以后,由于这个监控其实只包括了 PD leader 处理 TSO 时间,所以它慢说明 PD TSO 处理的慢,此时应该考察 PD Leader 的 CPU 占用情况是否较高?以及是否存在混布(混合部署)的情况,即同一台机器上有其他的进程或操作扰乱了 PD 的计算,影响了 TSO 的处理速度。
如果是 v4.0.13 版本之前(不包括),那么说明 PD leader 处理 TSO 时间慢或回传给客户端的发送时间慢或两者都比较慢,需要同时考虑上述 PD CPU 问题以及 PD 到 TiDB 之间的网络问题。
还有一个情况也会影响到 PD 的 TSO 分配——PD 出现了 leader 切换,不过一般出现 leader 切换,直接会导致 TSO 不可用,并不能是让 TSO 变慢的原因,只在此一提,仅供参考。
时过境迁,随着客户量的增加和代码的更新换代,TSO 的一些细节和监控都发生了些许变化,所以在此重新归纳整理,推出 TSO 慢排查手册 v2.0 版本。
[image]
是一直这样,还是偶发性的? 从你发的图上来看 PD 的处理速度偏慢了…
这种oom的情况比较多,最近一周出现了3次,也做了一些优化,比如设置tidb_analyze_version = 1 、调大mem-quota-query参数等。
xfworld
2022 年3 月 31 日 06:23
7
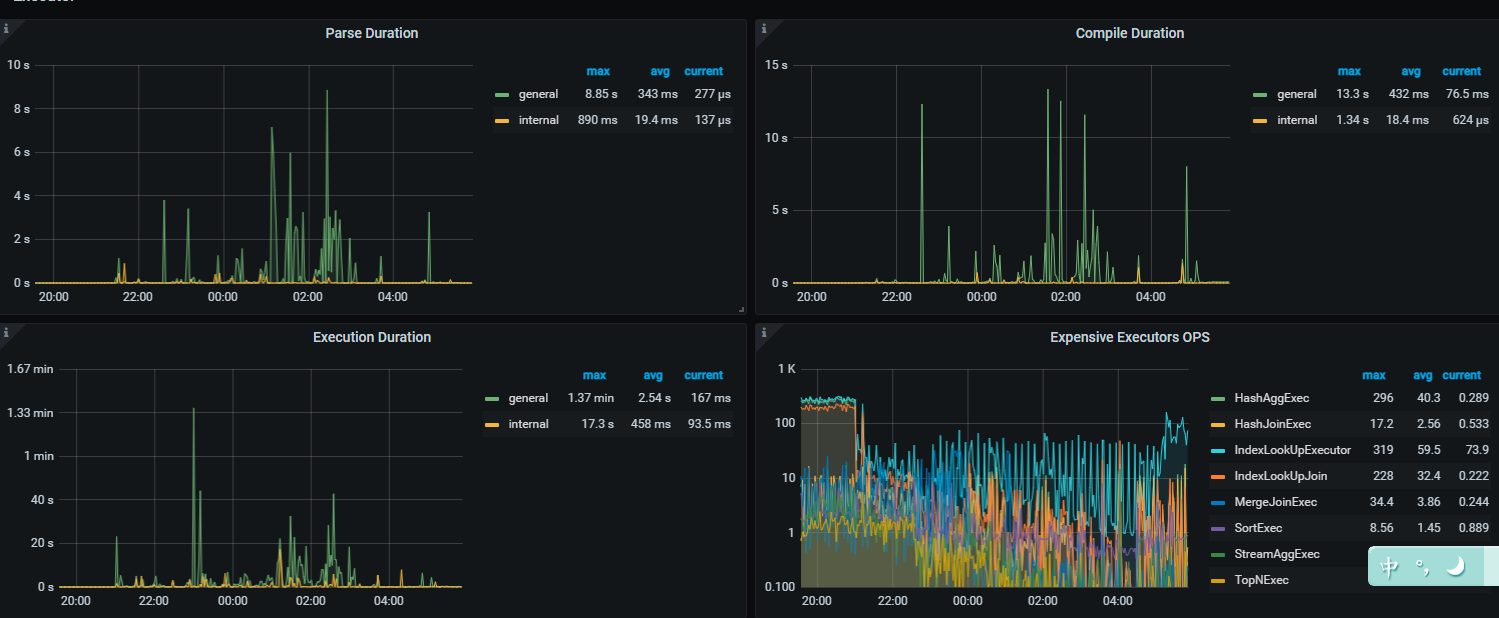
那你得先排除 慢SQL 的问题
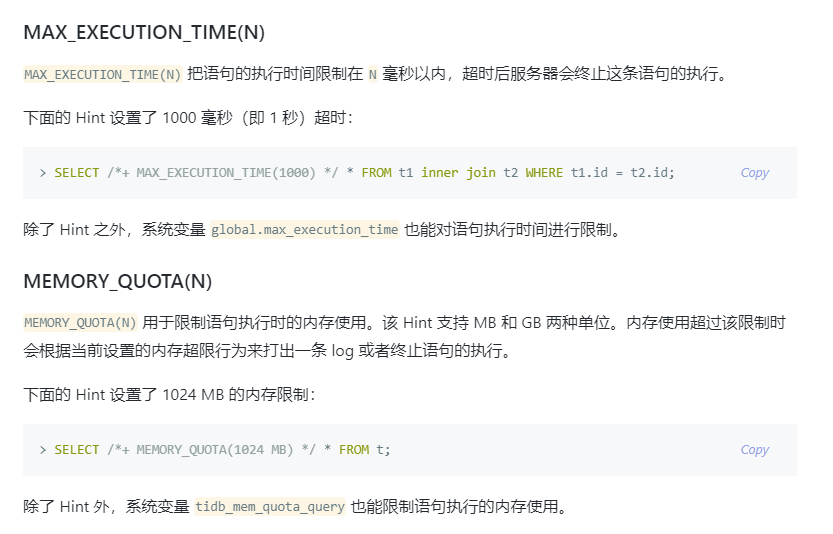
设置 SQL 最大执行时间,增加资源可控性
设置 SQL 的最大可用内存,并且开启 磁盘缓存
同时对资源消耗较大的 SQL 进行定位https://docs.pingcap.com/zh/tidb/stable/identify-expensive-queries
在逐个进行优化…
好的老师,还有请问tidb.log 很多gc的报错与这个有关么
xfworld
2022 年3 月 31 日 06:29
9
好的,升级的事情已经反馈。开启数据落盘缓解OOM有一个问题,tmp-storage-quota参数默认配置的-1,是不会开启落盘的么?
xfworld
2022 年3 月 31 日 06:40
11
TiDB 支持对执行算子的数据落盘功能。当 SQL 的内存使用超过 Memory Quota 时,tidb-server 可以通过落盘执行算子的中间数据,缓解内存压力。支持落盘的算子有:Sort、MergeJoin、HashJoin、HashAgg。
https://docs.pingcap.com/zh/tidb/stable/tidb-configuration-file#oom-use-tmp-storage
老师请问,设置 SQL 最大执行时间是对应哪个配置项呢
xfworld
2022 年4 月 1 日 09:30
15
system
2022 年10 月 31 日 19:25
17
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。