xxxxxxxx
(Hacker Z Vu Xy Nh8)
1
背景:tidb2.1.8升级到4.0.13。
现象:耗时变长,性能下降,慢查询记录了很多insert的慢查询,被记录的基本在300ms左右,少量select慢查询,慢查询阈值是200ms。
硬件配置:tikv都是192GB 40c,pcie-ssd的机器,且tidb pd都是分离的
集群总大小1.4TB,升级前升级后tikv节点个数一样(11个tikv),内存大小分配也一样(单个tikv 45GB),gc时间也一样,都是两小时
4.0.13版本的集群调整
(1)将默认的悲观事务锁调整为乐观事务,调整原因是之前排查问题怀疑是因为事务模型不一致导致加锁清锁耗时,因为业务采用的都是autocommit,所以即便在tidb层开启了悲观事务,也没法使用到,所以就与2.1保持一致,采用乐观事务。
(2)做了如下参数调整,其他的未做调整
server_configs:
tidb:
binlog.enable: true
binlog.ignore-error: true
log.file.max-days: 30
mem-quota-query: 10737418240
performance.committer-concurrency: 64
tikv:
log.file.max-days: 30
raftdb.defaultcf.write-buffer-size: 128MB
rocksdb.defaultcf.block-cache-size: 22GB
rocksdb.defaultcf.block-size: 64KB
rocksdb.defaultcf.write-buffer-size: 128MB
rocksdb.writecf.block-cache-size: 22GB
rocksdb.writecf.write-buffer-size: 128MB
storage.block-cache.capacity: 44GB
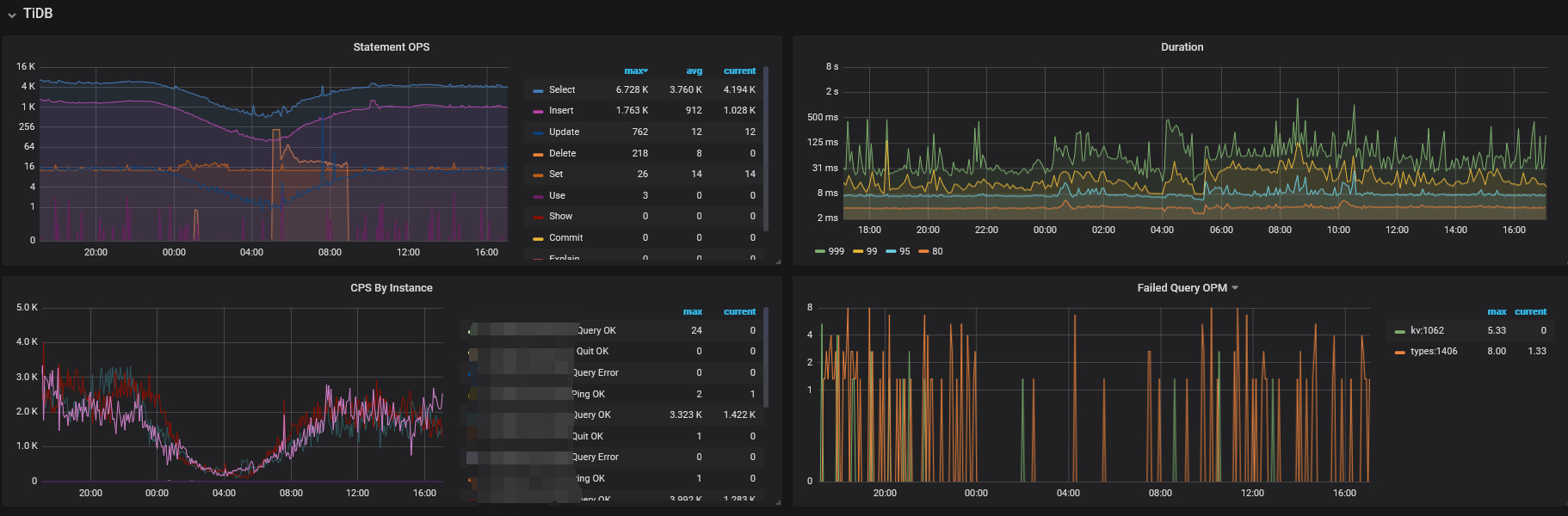
集群访问量情况
慢查询情况
(1)insert主要是Prewrite 和commit 阶段耗时,其中Prewrite 更多一些,而且所有的insert都是insert into xxx values,不存在多个values的情况,也没有duplicate update,也没有multi SQL
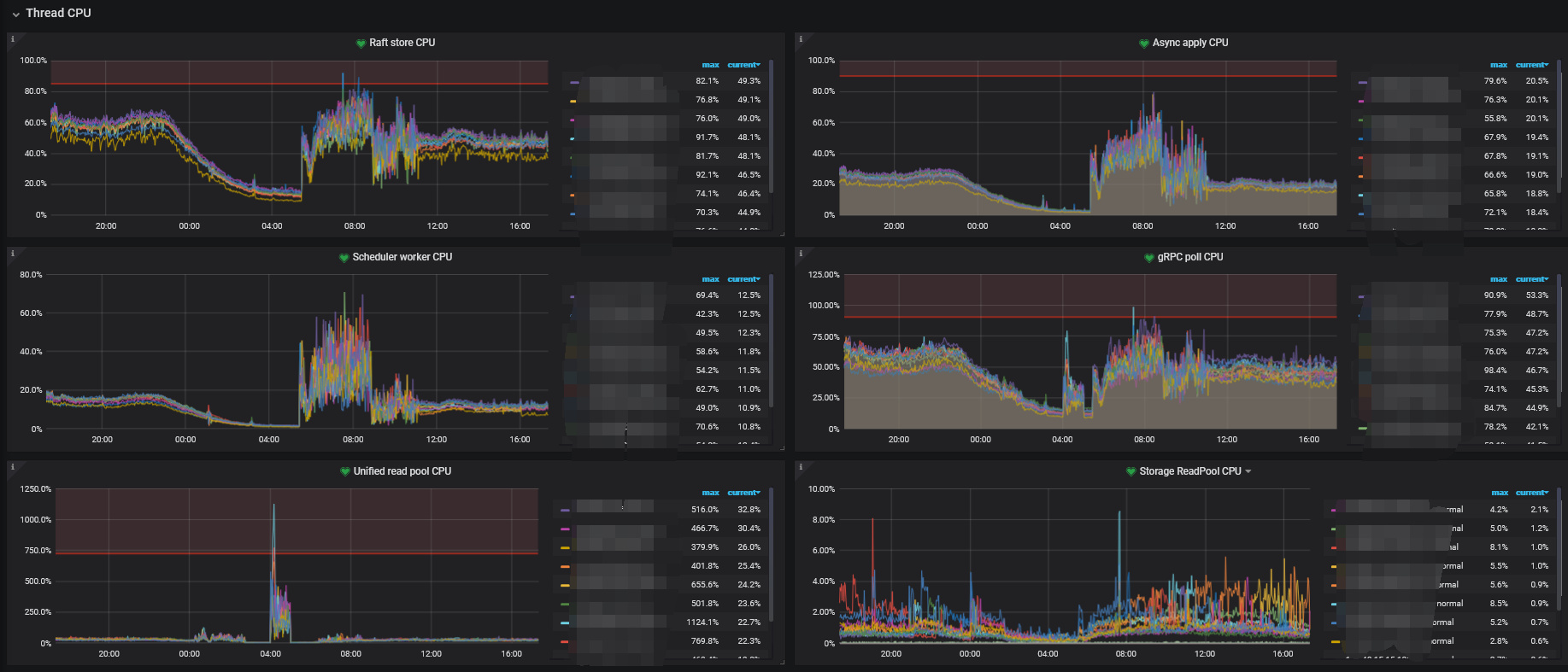
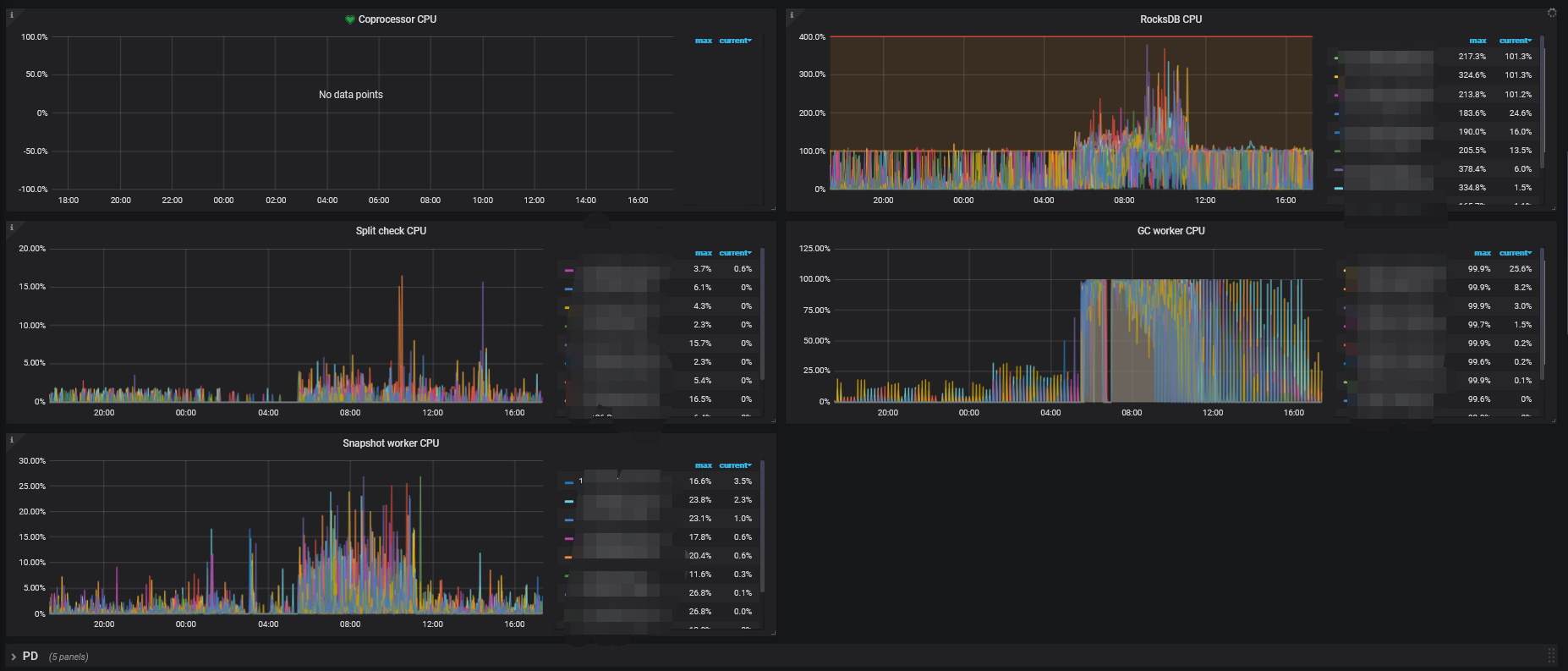
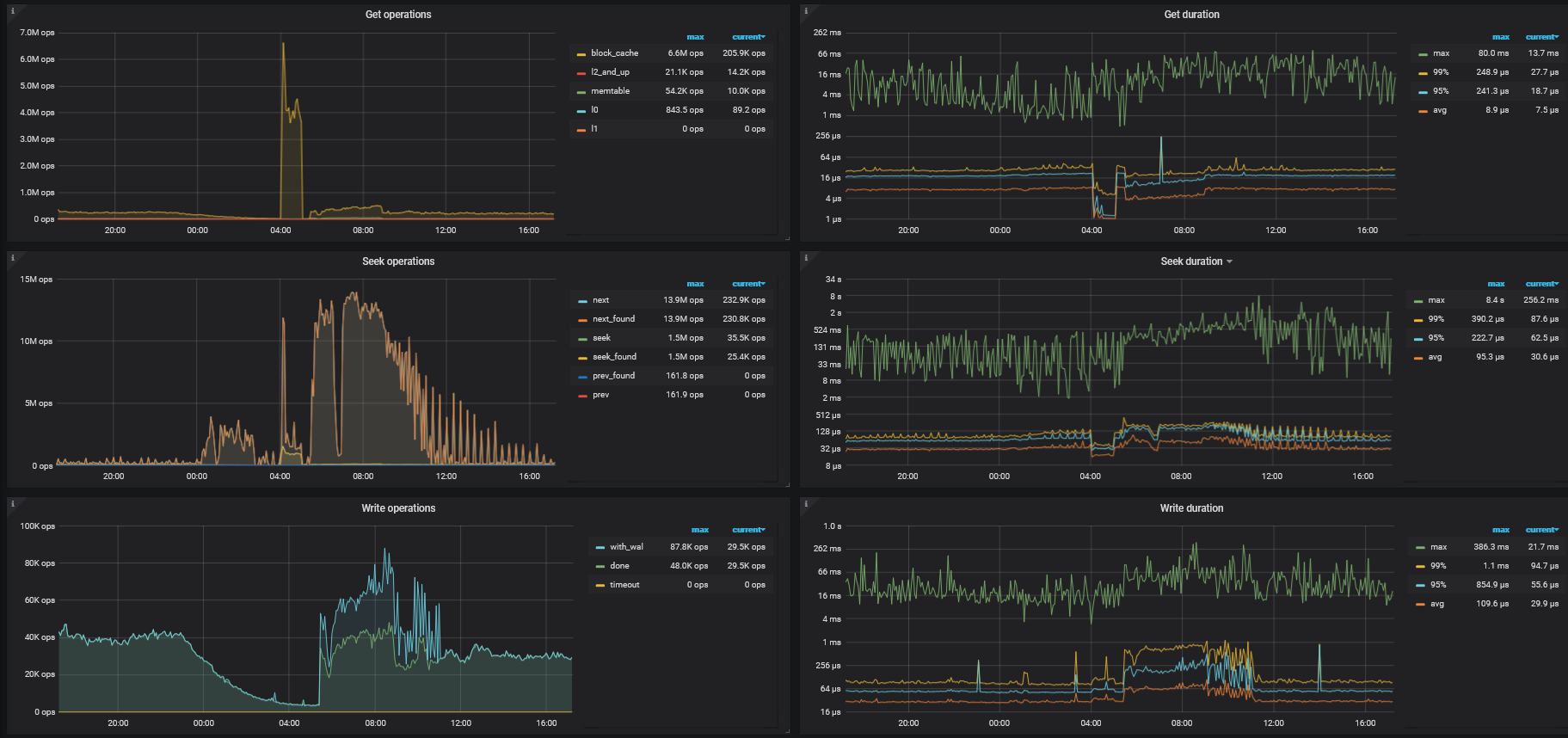
系统资源占用情况
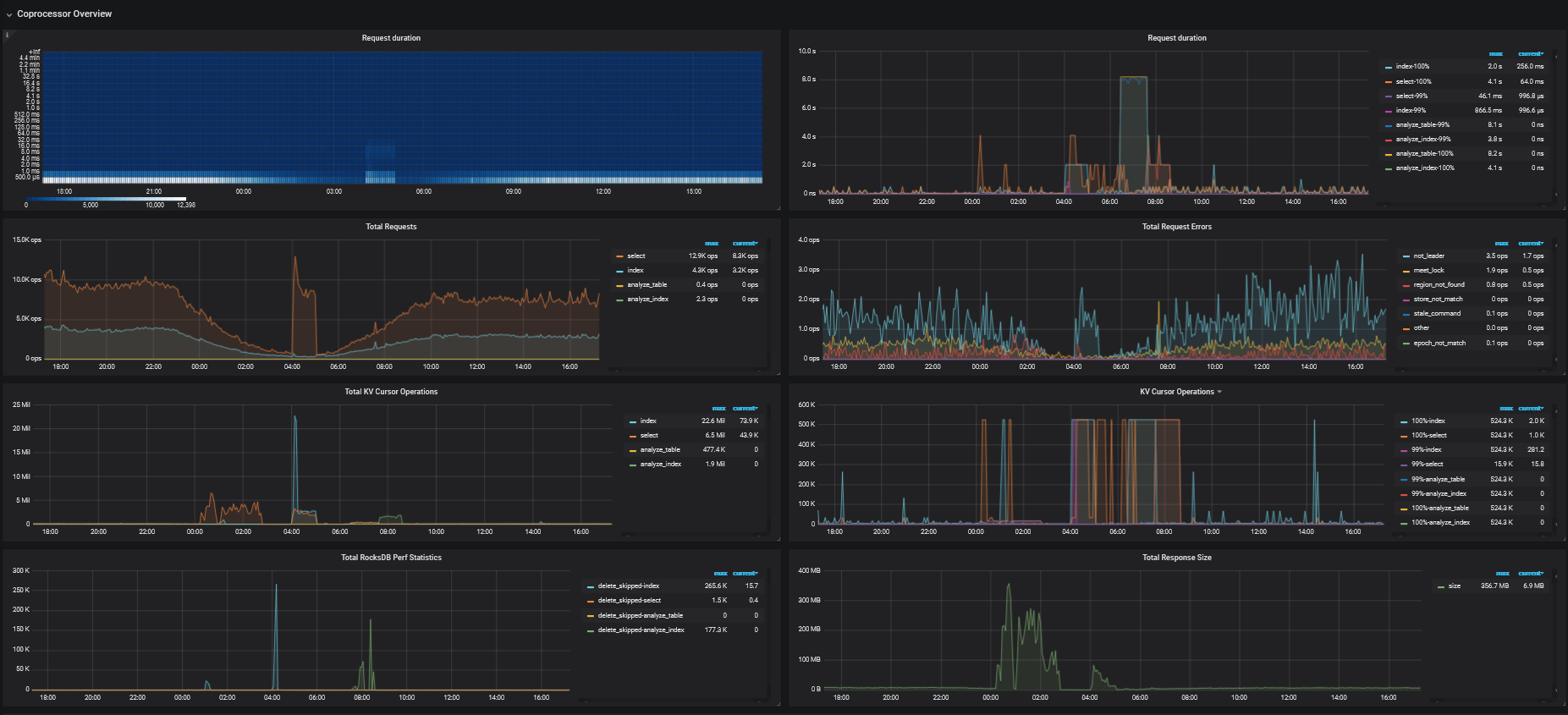
根据这个文章的排查思路,定位到是获取快照时间比较慢,系统资源没达到瓶颈
TiKV Details → Thread CPU
TiKV Details → Snapshot → 99% Handle snapshot duration
TiKV Details → RocksDB - kv
TiKV Details → Coprocessor Overview
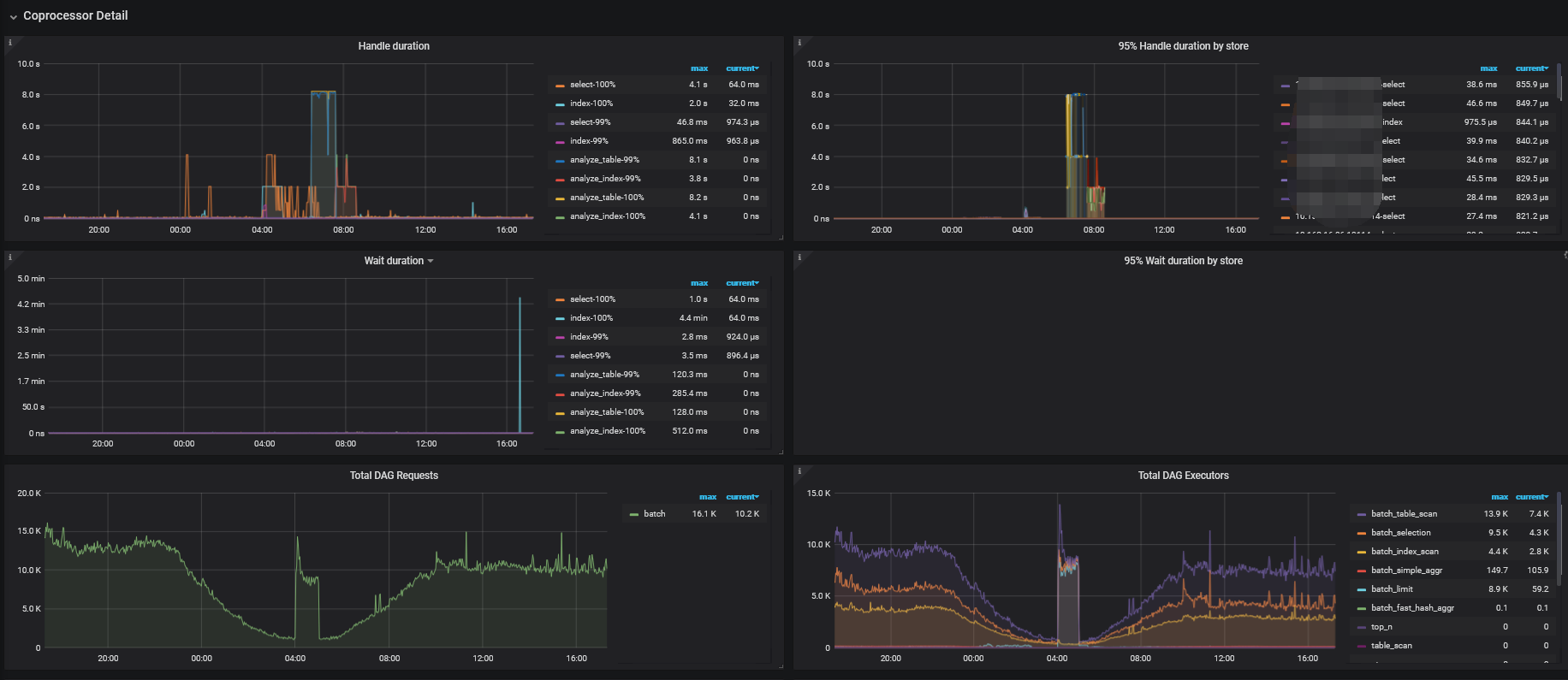
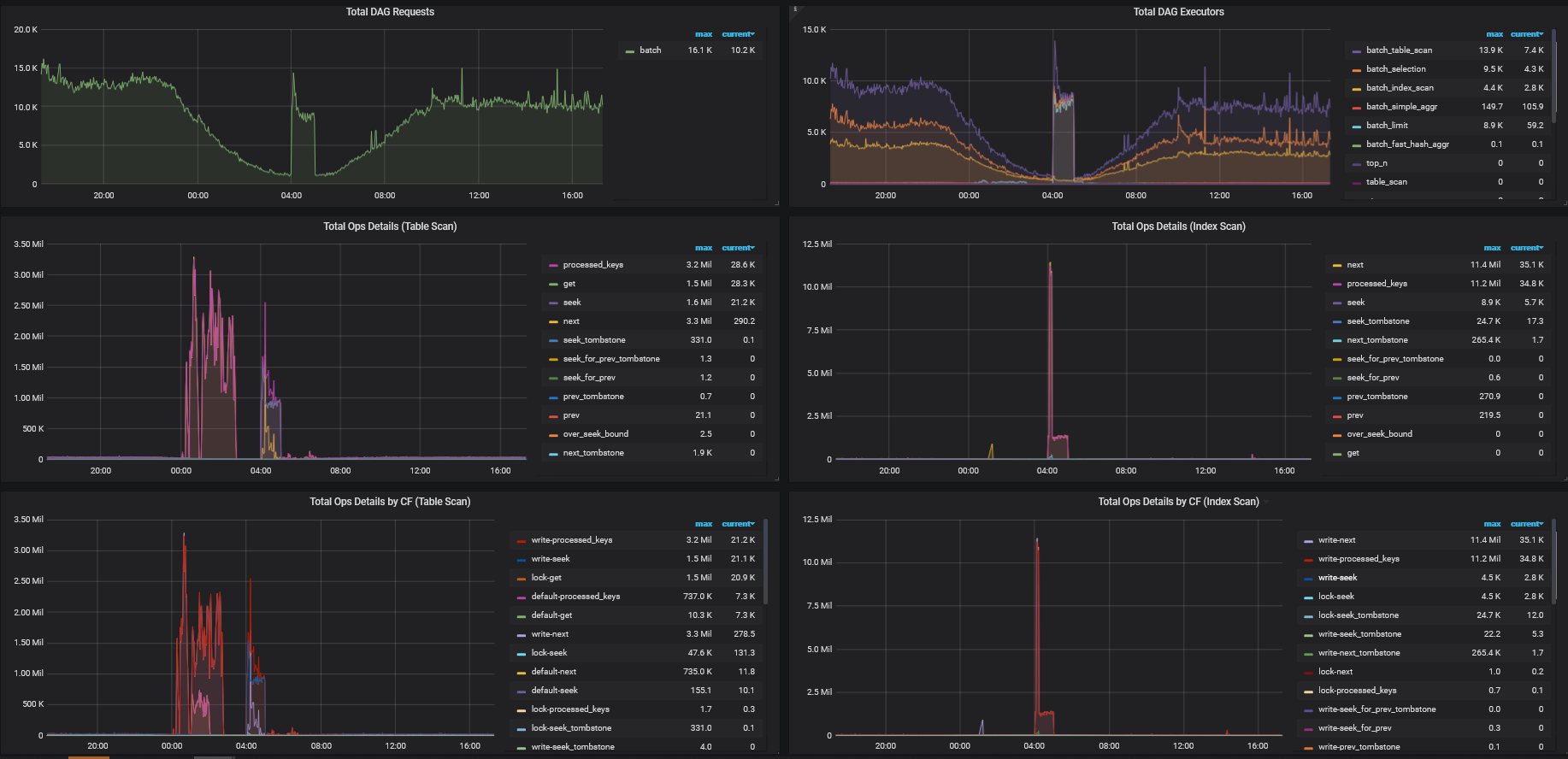
TiKV Details → Coprocessor Detail
网络延迟
关于锁冲突问题,在tidb日志中能找到所冲突记录,但是其实不多,今天才记录了三行
下面是tidb日志
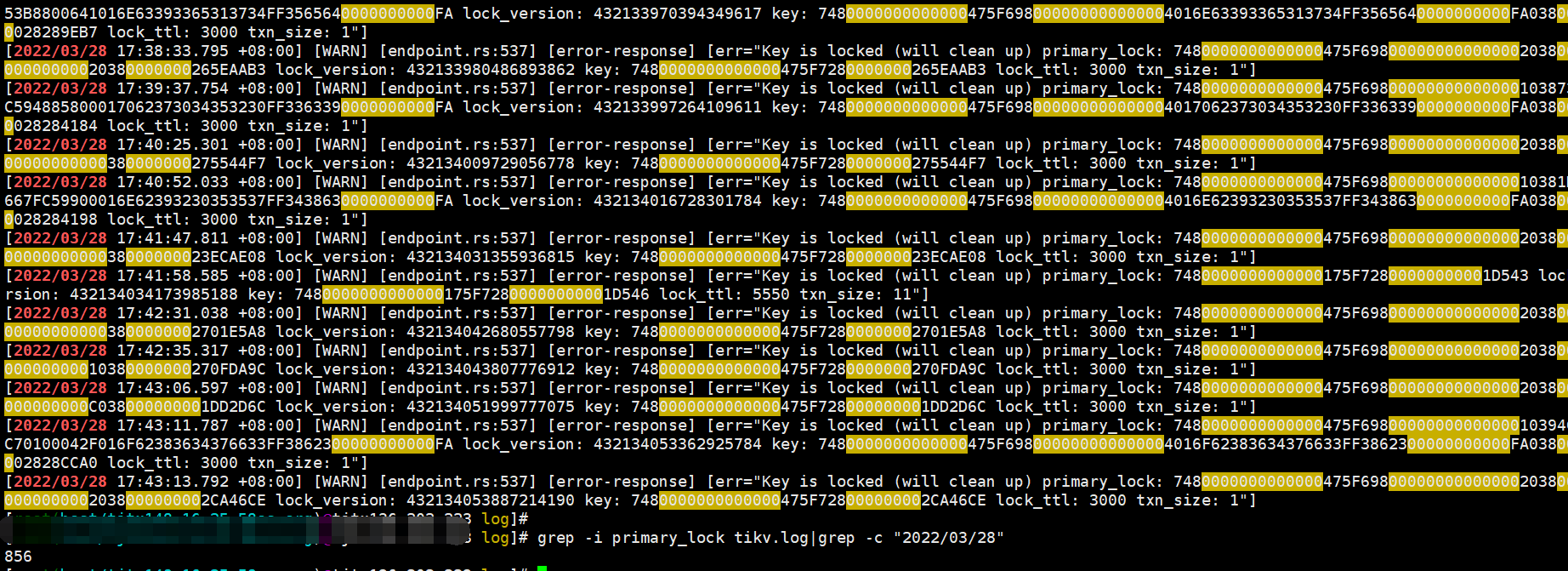
下面是tikv日志,primary_lock日志,在一个tikv节点今天被记录了850多条
@xxxxxxxx 少年,帮忙抓一下 监控 和 log ,我们再看一下最新的的监控情况。反馈的 prewrite 延迟比较高,但是看监控升级前后的性能差异不大。需要再看看 schedule 部分的监控和整体的情况哈。【SOP 系列 22】TiDB 集群诊断信息收集 Diag Collector 使用手册 v0.4.0
snapshot的tso获取,是发生在prewrite阶段吗?
Min_Chen
(Make the world more reliable)
11
你好:
麻烦拿一下 2-28 10:00 到 13:00 的所有 tikv 的日志吧,看到 kv prewrite 的 qps 降低,并且 duration 升高,或者最近类似的过程的日志,即 刚开始正常,中间变慢,后来恢复的过程。
另外,看到 15.217 这台机器各项指标偏高,可能成为写入过程拖后腿的,麻烦确认一下是否有写入热点,或是这个机器的磁盘性能问题。
还有一个需要和您了解一下,是只有这一种 insert 慢还是所有写入都慢?即同一 sql digest。
xxxxxxxx
(Hacker Z Vu Xy Nh8)
12
日志已经不可查了,我们默认保留30天。
15.217这个机器虽然指标偏高,就是单纯部署的服务多,但是也没达到瓶颈,后来下线了集群也一样,写慢主要是集中在两个表,从dashboard看也是有热点,然后主键都是auto_increment属性,后来改成auto_random也是一样的,热点问题依然存在。
Min_Chen
(Make the world more reliable)
13
最近有没有此过程发生?刚开始正常,中间变慢,后来恢复的过程,如果有麻烦提取一下 tikv 日志。
关于热点表,尝试过 SHARD_ROW_ID_BITS 处理了吗?
xxxxxxxx
(Hacker Z Vu Xy Nh8)
14
从慢查询看是持续在记录insert操作,基本都是300ms+。尝试过将auto_increment改成auto_random了,发现热点问题没有得到改善,也手动split过一些regoin了,基本没什么效果
Min_Chen
(Make the world more reliable)
15
建议使用 SHARD_ROW_ID_BITS 对表缓解写入热点。
另外,如果不方便提供日志的话,需要从 tikv 日志查看是否有 服务 或 raft group 的异常(慢/错)。
system
(system)
关闭
16
该主题在最后一个回复创建后60天后自动关闭。不再允许新的回复。