xxxxxxxx
(Hacker Z Vu Xy Nh8)
1
背景:tidb2.1.8升级到4.0.13。
现象:耗时变长,性能下降,慢查询记录了很多insert的慢查询,少量select慢查询,慢查询阈值是200ms。
硬件配置:tikv都是192GB 40c,pcie-ssd的机器,且tidb pd都是分离的
4.0.13版本的集群仅做了如下参数调整,其他的未做调整
server_configs:
tidb:
binlog.enable: true
binlog.ignore-error: false
log.file.max-days: 30
tikv:
log.file.max-days: 30
raftdb.defaultcf.write-buffer-size: 128MB
rocksdb.defaultcf.block-cache-size: 15GB
rocksdb.defaultcf.block-size: 64KB
rocksdb.defaultcf.write-buffer-size: 128MB
rocksdb.writecf.block-cache-size: 15GB
rocksdb.writecf.write-buffer-size: 128MB
storage.block-cache.capacity: 30GB
集群访问量情况
慢查询情况
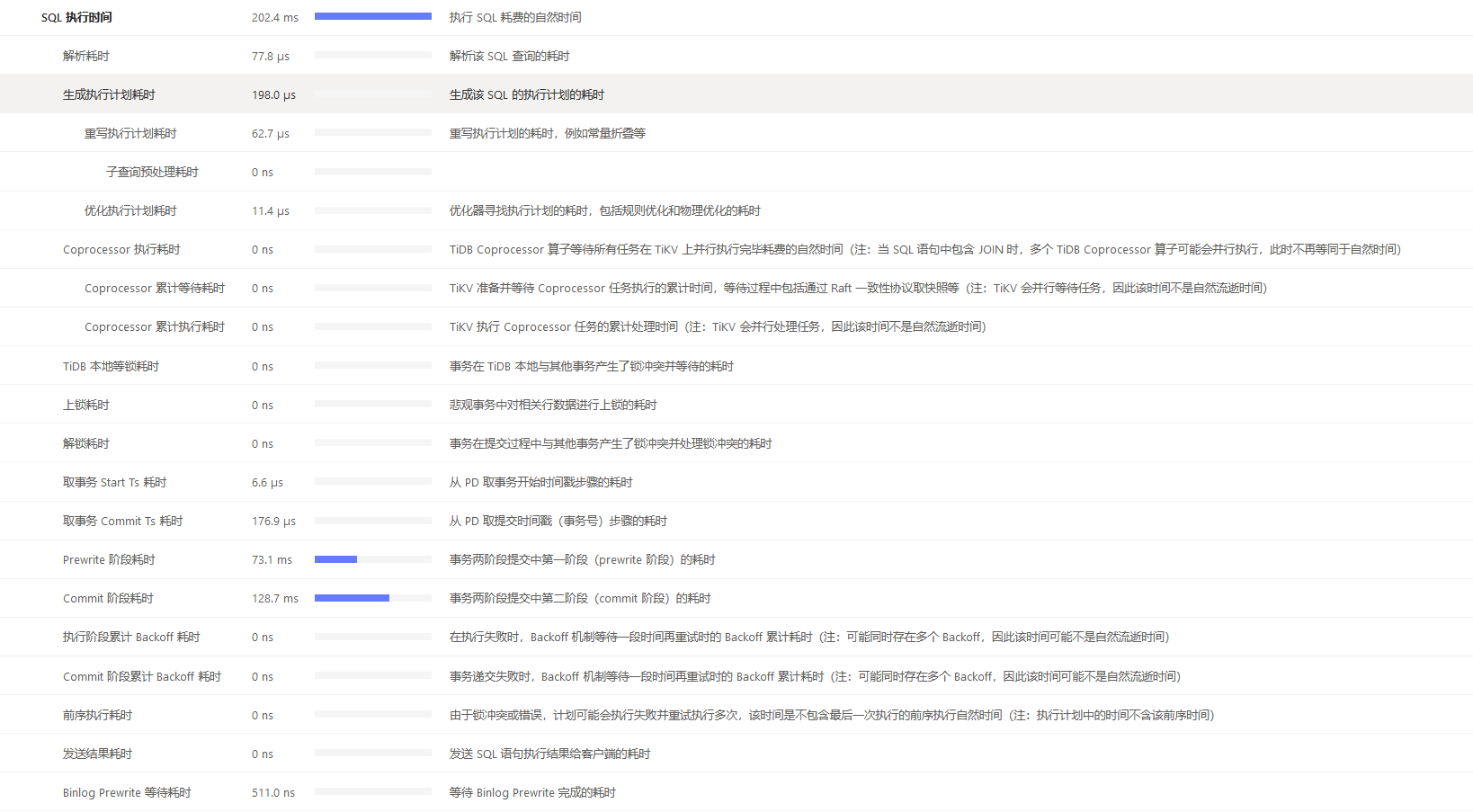
(1)insert主要是Prewrite 和commit 阶段耗时,其中Prewrite 更多一些
(2)select主要是Coprocessor 执行耗时
升级前的耗时情况
升级后的耗时情况
系统资源占用情况
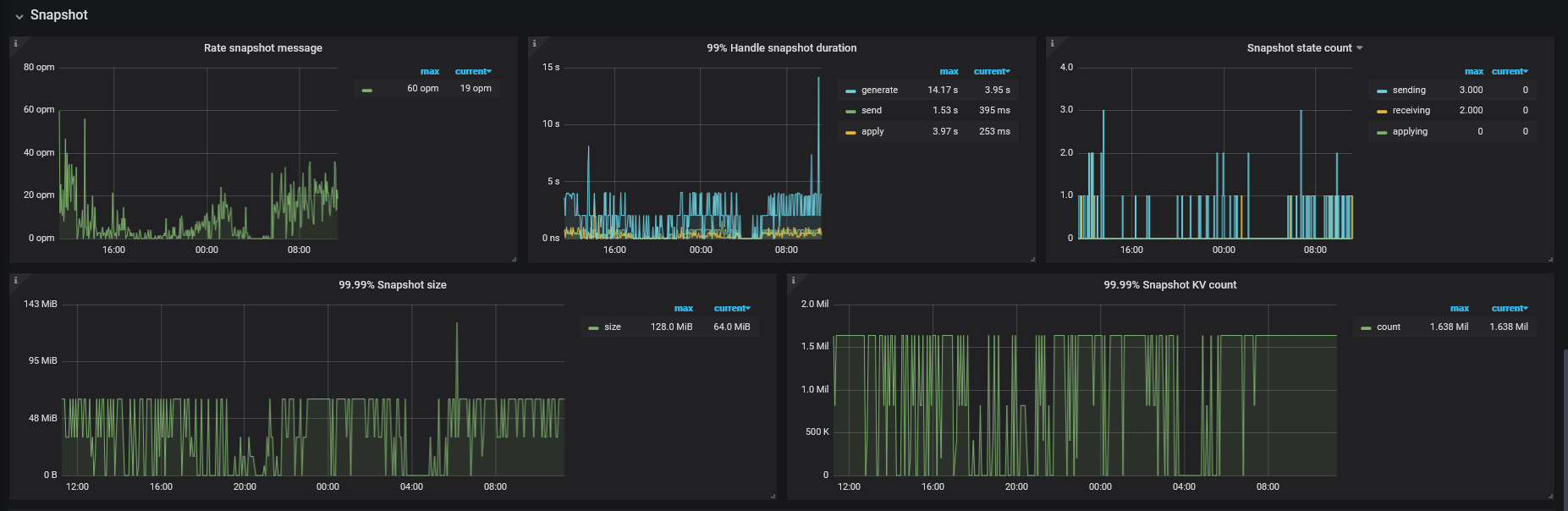
根据这个文章的排查思路,定位到是获取快照时间比较慢,系统资源没达到瓶颈
TiKV Details → Snapshot → 99% Handle snapshot duration
网络延迟
2 个赞
Meditator
(Wendywong020)
2
1)2.x升级到4.x,这个跨度挺大的,怎么个升级方法?
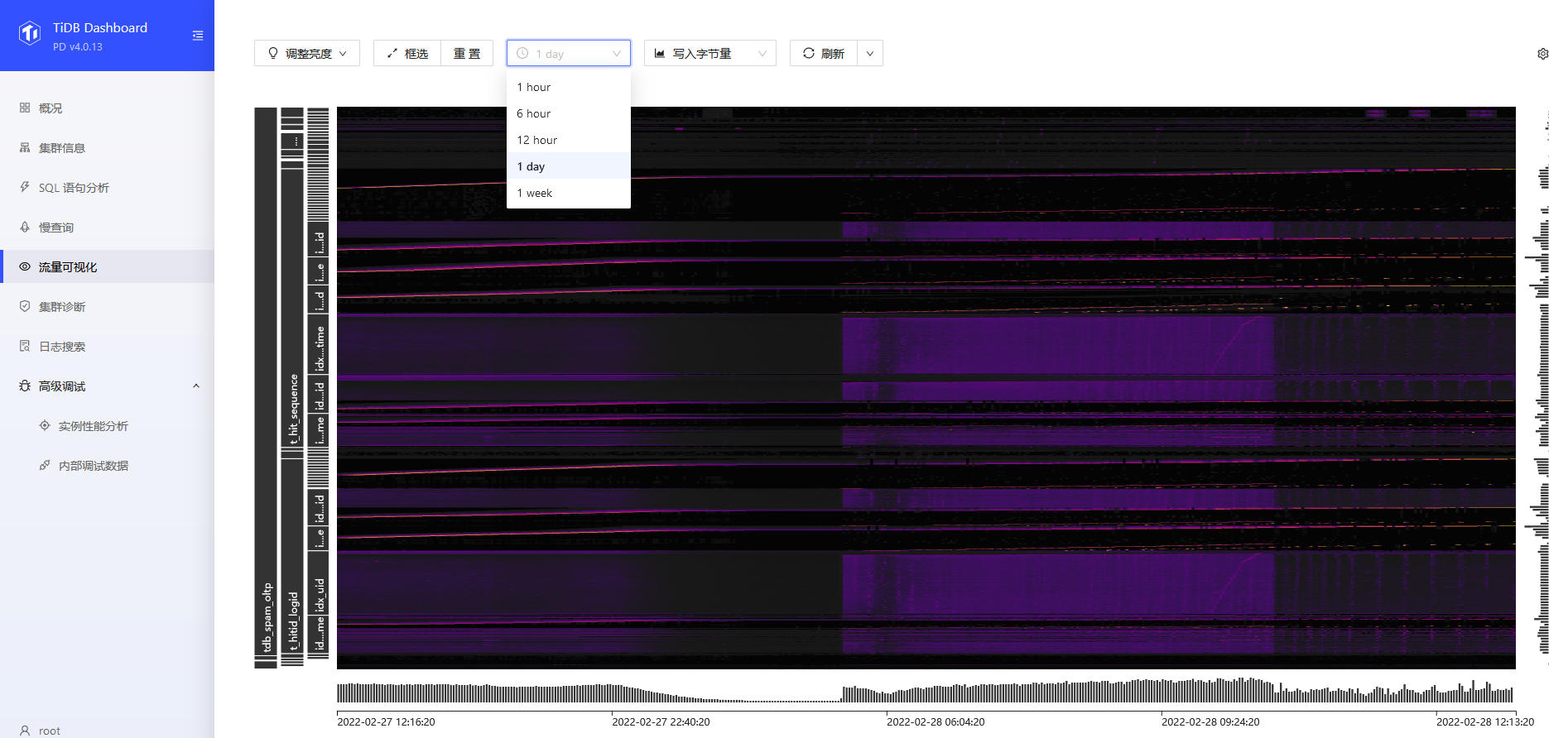
2)登录dashborad 看看有没有热点?
3)看主机的负载,有个load[1m] 快到20,这个负载挺高的
4)导出tikv-details的监控指标,参考这里:https://metricstool.pingcap.com/
3 个赞
xxxxxxxx
(Hacker Z Vu Xy Nh8)
3
1、导出全量备份,导入新集群,然后利用drainer同步增量。
2、dashboard
3、load20那个是特殊tidb节点,专门用来给集群备份的,有压缩任务,有传输任务,所以负载比较大,这个节点可以忽略
4、最近三小时的tikv监控
tidb-oltp-114-v4.0.13-TiKV-Details_2022-02-28T04_56_27.629Z.json (38.3 MB)
2 个赞
Meditator
(Wendywong020)
4
多谢上传!
1)麻烦在上传下overview这个这个监控指标;
2) 看指标就是锁冲突或者事务的用法问题,3.0.8开始新创建的 TiDB 集群默认使用悲观事务模式;
2 个赞
Meditator
(Wendywong020)
5
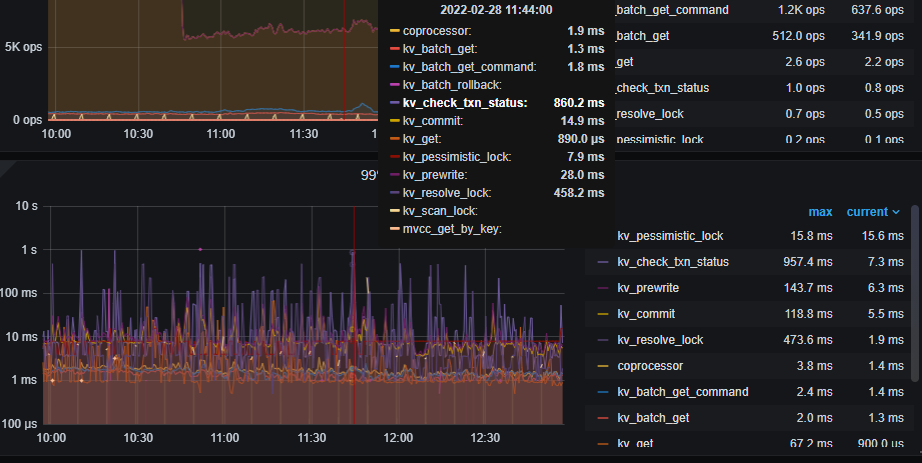
1)另外要看下15.217这个主机的负载情况,commit log动作耗时很高。
2)另外磁盘的io scheduler测试是怎么设置的?看这种毛刺,跟cfq策略一样, ssd类型 建议noop。
2 个赞
xxxxxxxx
(Hacker Z Vu Xy Nh8)
7
1、overview
tidb-oltp-114-v4.0.13-Overview_2022-02-28T08_53_34.440Z.json (6.8 MB)
15.217这个机器确实比其他机器的io压力稍微高一点
注:这个不知道为啥导出来没io相关的面板
2、4.0使用的是悲观事务,之前2.1是乐观锁,读写冲突比较多,所以考虑升级到4.0
3、机器的io调度都是noop
2 个赞
Meditator
(Wendywong020)
8
使用悲观事务需要两个条件
1)显式使用事务,例如 begin xx;
2)显式开启悲观事务;
autocommit事务会自动使用乐观模式
不知应用中是否有做相应的调整?
2 个赞
xxxxxxxx
(Hacker Z Vu Xy Nh8)
9
这个没考虑到,业务也是用的autocommit。有这种条件限制,这个悲观事务感觉有点不友好,想使用悲观事务还得大量调整业务代码,这个需求似乎不太合理
3 个赞
Meditator
(Wendywong020)
10
所以现在的情况是集群的事务模式是默认的悲观模式,但是业务用的是乐观事务模式,这样最终是乐观模式,不确切具体的影响。
不妨把集群的事务模式调整成乐观模式(跟2.x保持一致) 看看。
2 个赞
xxxxxxxx
(Hacker Z Vu Xy Nh8)
11
请问,这个操作有什么风险吗,另外这个操作是在线吗,是否需要重启tidb组件
3 个赞
Meditator
(Wendywong020)
12
1)可以动态修改,
查看:select @@global.tidb_txn_mode;
修改:set @@global.tidb_txn_mode = ‘optimistic;’
2)理论上没有问题,因为2.x都是乐观模式
安全期间最好能验证下
2 个赞
xxxxxxxx
(Hacker Z Vu Xy Nh8)
13
另外请教一下,新集群是悲观事务(实际也是乐观事务),旧集群是乐观事务,那为什么新集群的耗时会比较大呢,这个现象有没有什么理论可以给解释一下
注:新旧集群的tikv节点数都是一样的,不同的是旧集群分配的是45GB内存,新集群是30GB。
2 个赞
Meditator
(Wendywong020)
14
1)现在迁移前后两个事务模式不一致,这是怀疑的一个方向,发现prewrite 耗时比较多,很多耗时都耗在lock和事务检测、锁清理方面。这是之前事务失败或者回滚或者正常提交的遗留清理
2)还有个怀疑点 热点问题,部分tikv的commit log耗时比较多。也就是木桶理论的短板。
xxxxxxxx
(Hacker Z Vu Xy Nh8)
15
关于这个热点问题,我也有疑问,4.0以后不是会自行拆分了吗,怎么热点问题还会持续存在呢
1 个赞
Meditator
(Wendywong020)
16
是会自动split region,但是这个跟设计有关系,再者,split动作是事后弥补的动作,真正想从源头消除掉,可能是需要在设计上下功夫。
xxxxxxxx
(Hacker Z Vu Xy Nh8)
19
好的,这个需要跟业务沟通一下,另外您决得这个问题跟分配的内存大小有关系 吗,之前旧集群是45GB,然后耗时相对低点,现在新集群内存30GB,耗时比较高,我寻思着吧内存调成与旧集群保持一致
1 个赞
Meditator
(Wendywong020)
20
看下主机的负载情况,个人觉得关系不是很大,当然条件允许设置大点更好。