看着qps不高,但磁盘的io量还是挺大,看下在执行的那些SQL和执行计划
刚刚看了一下,发现有大量的delete操作
看下这些SQL是否是正常的业务,能否优化? 能否停下来然后在看集群状态。tikv处理不过来大量写入后就会server busy
嗯,我刚刚删掉了哪些进程。
大佬,这种情况,是否可以通过添加tikv节点,来缓解当前的情况?
杀了进程后什么状态?底层存储资源没争抢的情况下可以扩tikv, 现在一个tikv十几万的region量还是比较多的,是不是有很多空region。 3.0的版本有点老了,有条件还是升级到较新的版本吧
我不知道3.0版本,怎么查看空region,监控面板上,看不到empty-xxx
你这个规模够大的啊。
https://docs.pingcap.com/zh/tidb/v3.0/tikv-configuration-file#raft-base-tick-interval
这个参数调大一些呢?我的想法是现状默认1s,你调大成10s,集群之间的消息数量小了,相当于120k的region变成了12k的region,会不会好一些。
个人想法,调整参数需要重启,是否可以调整可以慎重考虑下。
有PD面板吗?或者pd-ctl region check empty-region|grep start_key|wc -l
这个命令执行了30分钟,还没出来结果
再请教一下,如果命令查出了空region,
是否可以手动通过命令去清理那些空region?
3.0默认开启空region合并。
coprocessor.split-region-on-table 控制是否开启跨表合并
“max-merge-region-size”: 50, “max-merge-region-keys”: 200000 控制merge region的阈值,pd-ctl调整
昨天下午,我对所有的进程做了梳理。
发现processlist中有很多delete的操作被hold住,就算delete执行完还是会定时发起。
后续先把这种业务操作,delete的进程全部kill掉。让业务方不发起delete的操作,到目前为止,server is busy就没有出现过
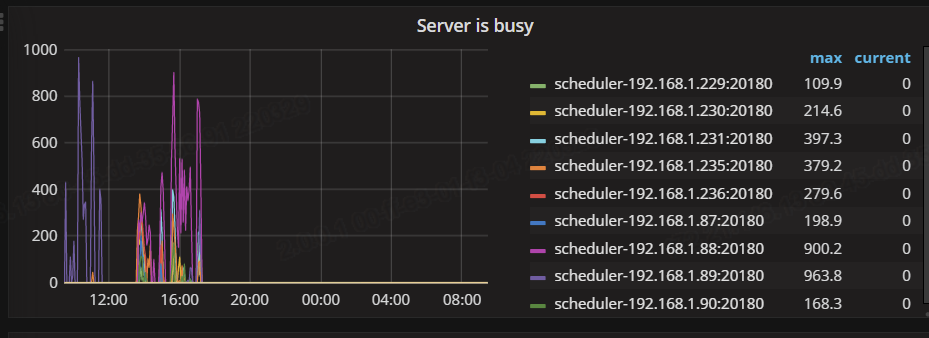
tikv实例需要扩充
嗯,我申请了两个节点,今天会加上去,但目前server is busy没了,但region不均的情况还是存在,而且现在GC的时间也长达8个小时才完成,这个很不正常
pd-ctl store看region-weight、score什么的有不同吗
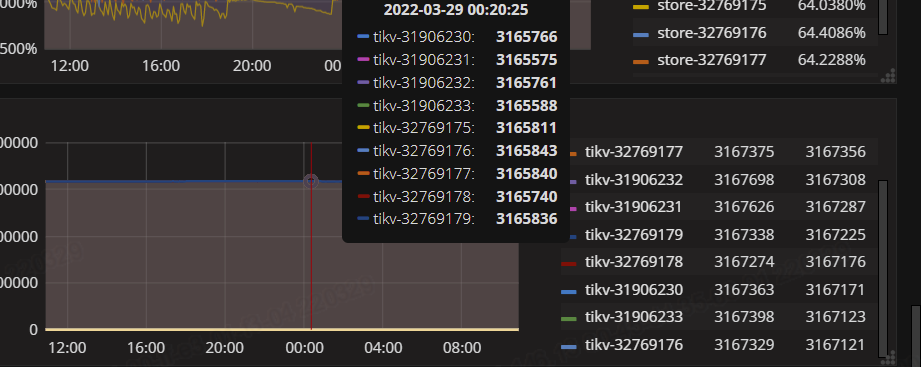
那就还是空region问题,high-sapce-ratio下score是按实际空间大小计算的。
我昨天执行那个统计空region的操作,一直没有返回结果
这些空region 有什么处理方案,可以参考吗?
你看PD或overview面板上有region health监控吗