【 TiDB 使用环境】 集群模式 虚拟机 centos7
【概述】场景+问题概述
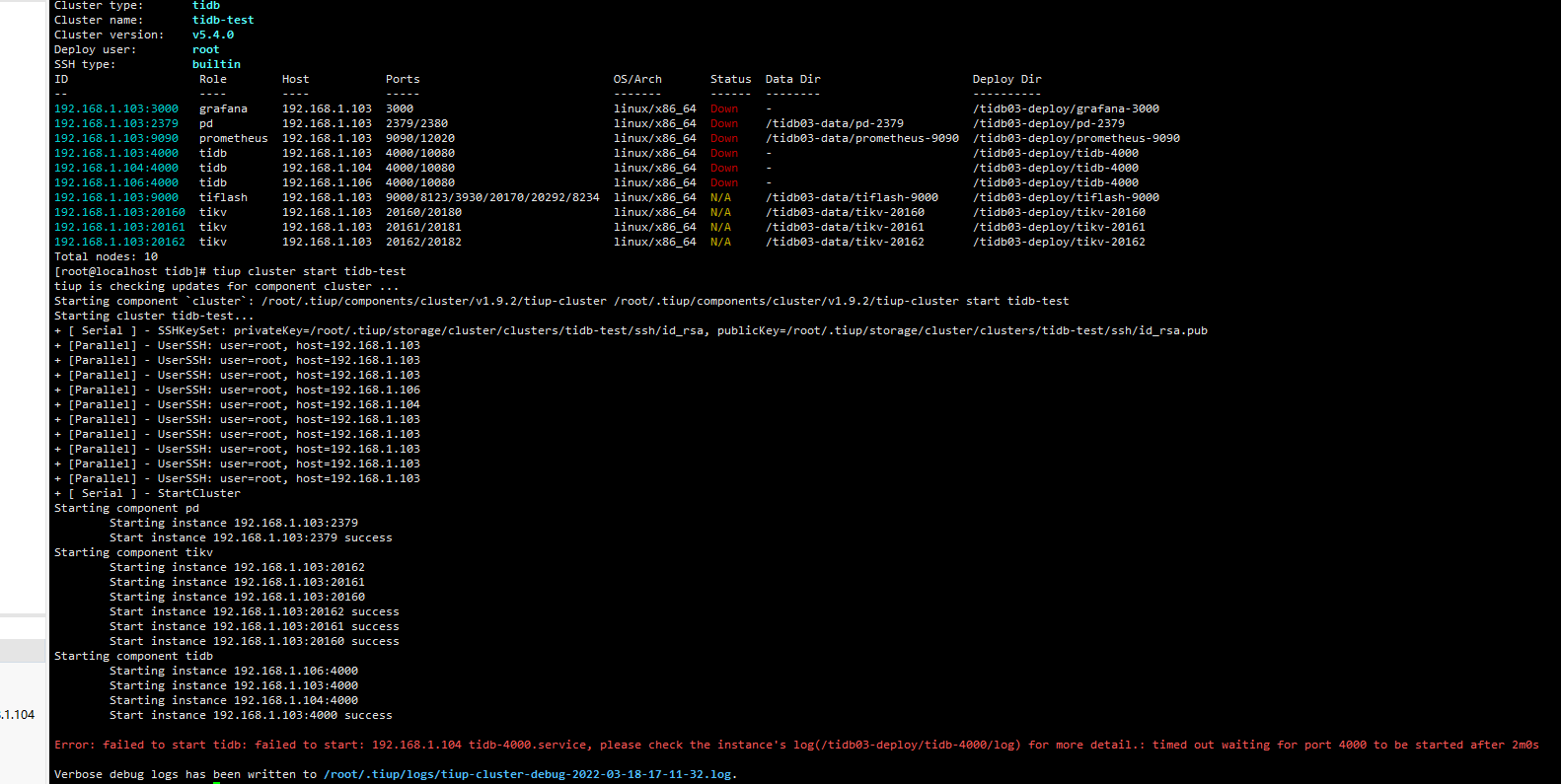
部署tidb集群成功,但是启动tidb集群时会报错,响应时间超长,我目前有三台虚拟机 一台作为中控机部署tidb及tikv等-103 , 另两台作为tidb部署 104 106。 部署时全部成功 但是启动集群时报错,
[timed out waiting for port 4000 to be started after 2m0s],试了一下论坛各种解决办法没有起效。
望解答
【背景】 挂载参数及安装软件环境完成 本地部署单机测试集群成功 网络无问题 远程无问题
【TiDB 版本】5.4
部署:
启动后 报错信息
日志查询信息
tail详细日志
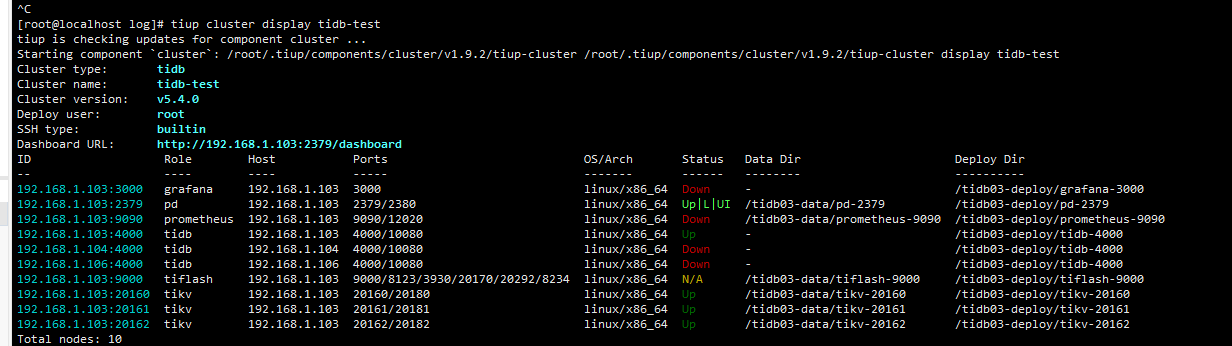
查看104节点 发现tidb已经启动
运行状态
3 个赞
系统日志有没有什么提示呢 比如OOM?系统的资源情况还好么
2 个赞
检查一下网络和端口问题。上次我遇到同样的问题,是因为端口被占用了
2 个赞
dengqee
(Dengqee)
4
检查一下tidb服务是否在监听4000端口,虽然systemd显示启动,但是可能它并没有在监听4000端口,tiup部署实例时是通过查看4000端口是否被监听来判断该组件是否被启动成功
2 个赞
netstat -anp |grep 4000,看看4000端口有没有被占用
1 个赞
dbaspace
(dbaspace)
8
之前遇到你这类似问题,就是之前部署过集群没清理干净,又重新搞或者非常规操作过,实际你启动的4000端口是另外一套的,因此通过systemctl查看状态有,实际并没有存活端口,
Hi70KG
(Harbin70KG)
9
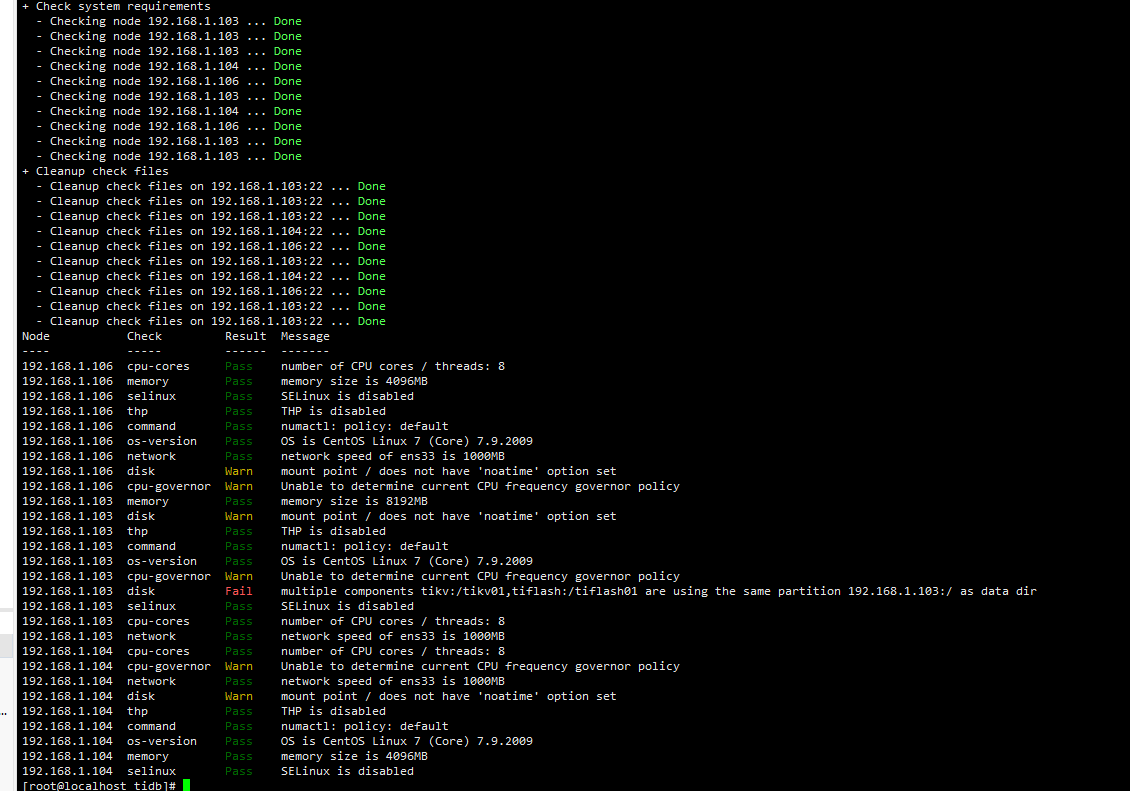
建议安装之前先check一下,查看是否有什么地方配置不正确,如果有fail处,再次check一下,可以修复部分fail,直到没有fail为止
tiup cluster check ./topology.yaml --apply --user root -p (PS:yaml文件是安装部署文件以你部署的文件为准)
以下是和你一样用虚拟机部署的tidb集群,仅供参考,希望对你有帮助
2 个赞
系统资源都没问题 没有oom错误 top查看资源占用也不多 而且主服务103启动成功,104 106没有启动成功
之前确实部署过 当时是可以连接到104 但是在做暴力测试之后(杀进程在启动查看数据、直接重启服务器模拟宕机)就启动失败。删除了(destory)原集群之后重新部署 就出现了这样的问题。不知道怎么彻底清除呢?
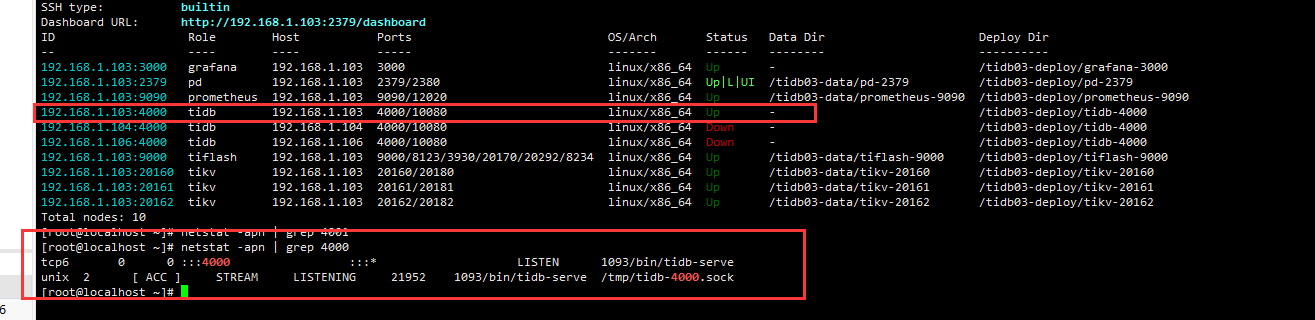
您好 您提到的这个怎么查询或者解决呢?我在104 106的默认情况下 4000端口没有启动,在部署集群后已经查询过了,在启动集群后两台服务器的端口才进行启动的。
查询103-4000端口
查询104 -4000 端口
106也做了同样查询 没有发现占用,至于您说的网络问题具体怎么排查呢?我通过ssh连接都是没问题的
您好,这个怎么判断是否在监听呢,查了一下文档和操作手册没有相关的内容。目前来看应该是之前部署过 但是没有清理掉 启动的是之前部署的集群的 4000端口,主集群我已经进行了destory。
dbaspace
(dbaspace)
17
看来你和当时一样的问题,当时具体操作流程忘记了,貌似journalctl 观察日志 停止现在的已经启动的服务,tidb-4000.service 进行 disable ,修改脚本 启动现在现在的 然后操作systemctl enable tidb-xxx.service 大概是那么搞
通过检测后修改部分参数 目前检测除了data dir问题无法排除之外 没有其他问题
重试部署启动集群 并且修改tidb端口 发现tikv可以启动(大概率排除网络问题)启动tidb失败
端口号没有占用。
之前确实在104部署过一套 之后进行了数据库destory 再次部署就报错,找不到标准的清理手段和方式。
104端口:
报错信息:
看看清除下集群的tidb-server,再重新部署tidb-server
1、查看集群状态tiup cluster display 集群名
2、找到tidb的那行,ip:port tidb
3、停止tidb # tiup cluster stop 集群名 -N ip:port
4、清除tidb节点# tiup cluster scale-in 集群名 --node ip:port
5、清理集群# tiup cluster prune 集群名
–重新增加tidb-server节点