1.版本:TIDB:v5.4.0 BR工具:v5.4.0
2.问题描述:
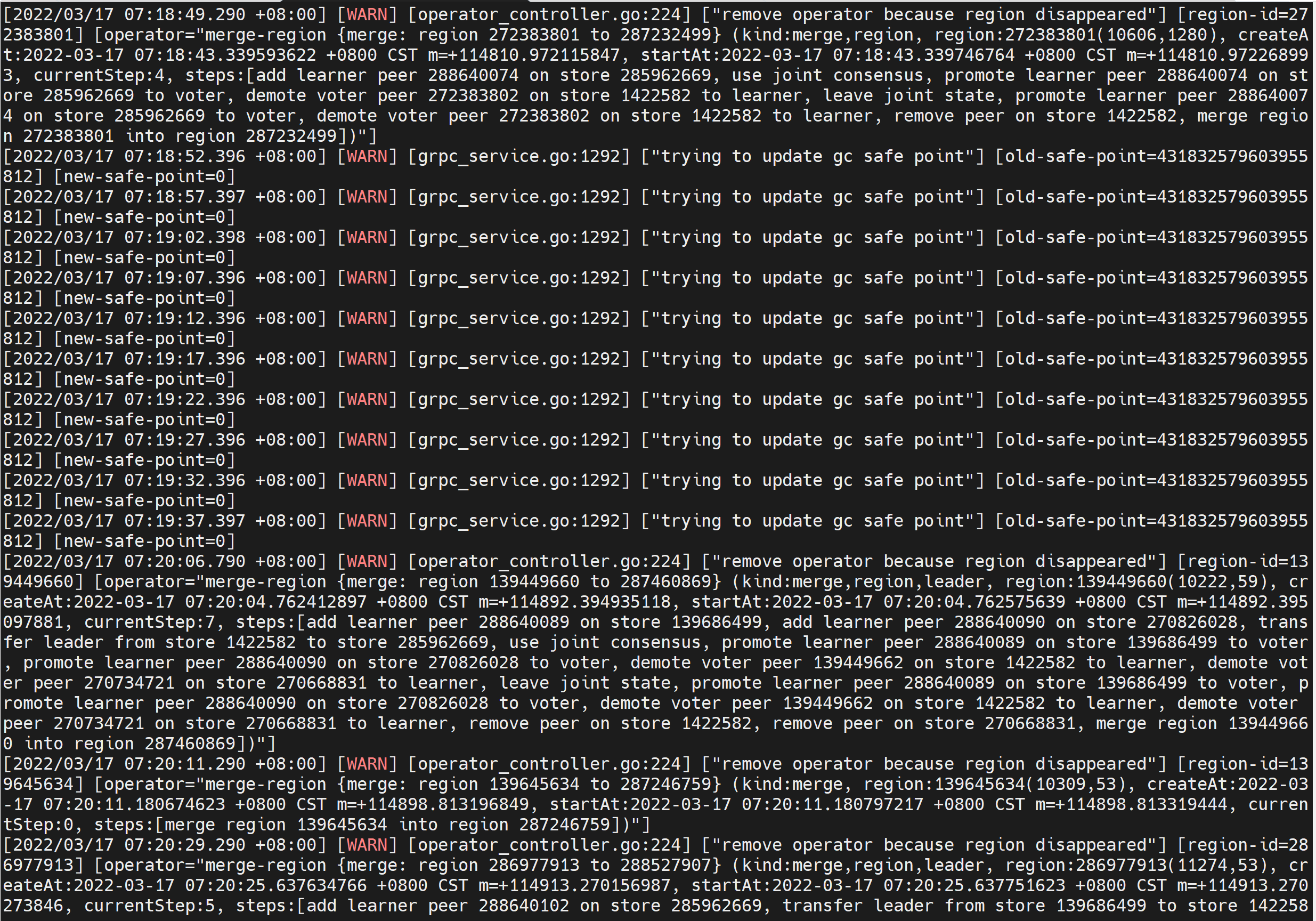
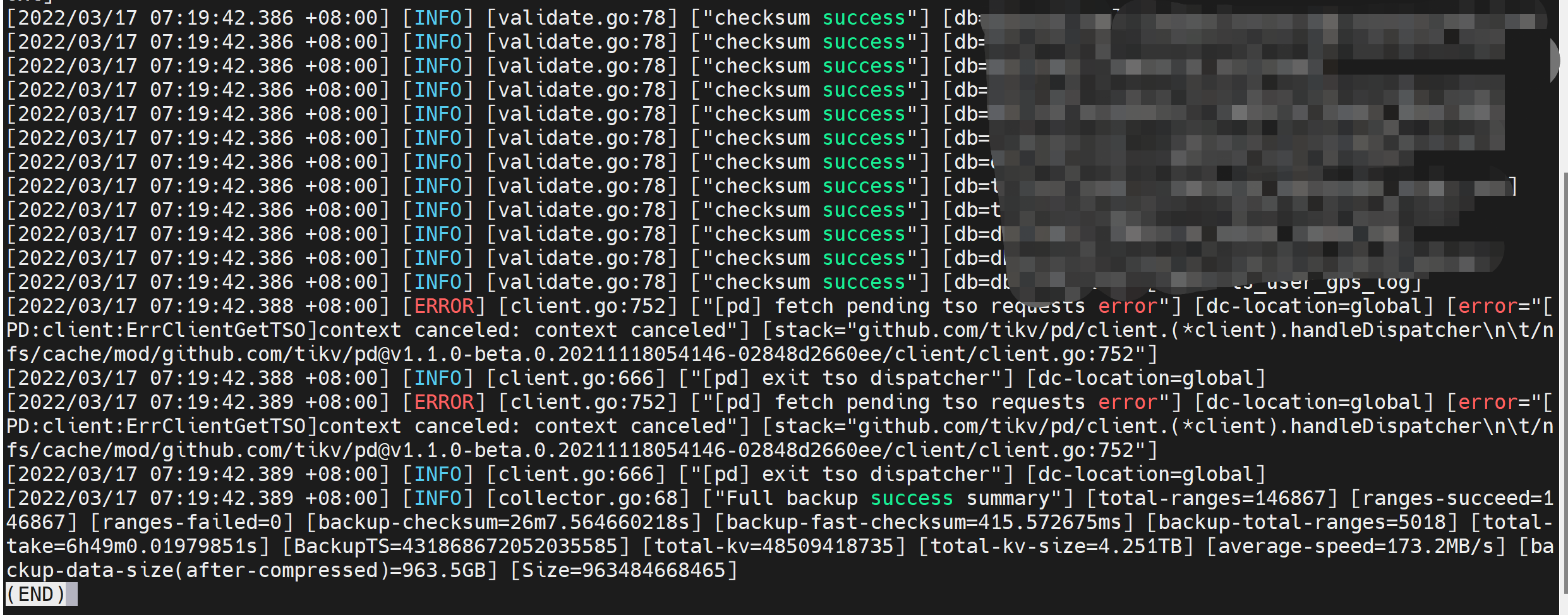
TIDB集群升级到了最新的v5.4.0,使用BR备份数据时出现以下报错,请问是什么问题?
[2022/03/17 07:19:42.388 +08:00] [ERROR] [client.go:752] [“[pd] fetch pending tso requests error”] [dc-location=global] [error=“[PD:client:ErrClientGetTSO]context canceled: context canceled”] [stack=“github.com/tikv/pd/client.(*client).handleDispatcher
\t/nfs/cache/mod/github.com/tikv/pd@v1.1.0-beta.0.20211118054146-02848d2660ee/client/client.go:752”]
啦啦啦啦啦
2
看报错是tso获取失败,看看报错时间段的 pd.log 有没有报错。
PD没有ERROR日志,只有PD leader上有一些WARN日志,其它的pd上连WARN日志也没有。
啦啦啦啦啦
4
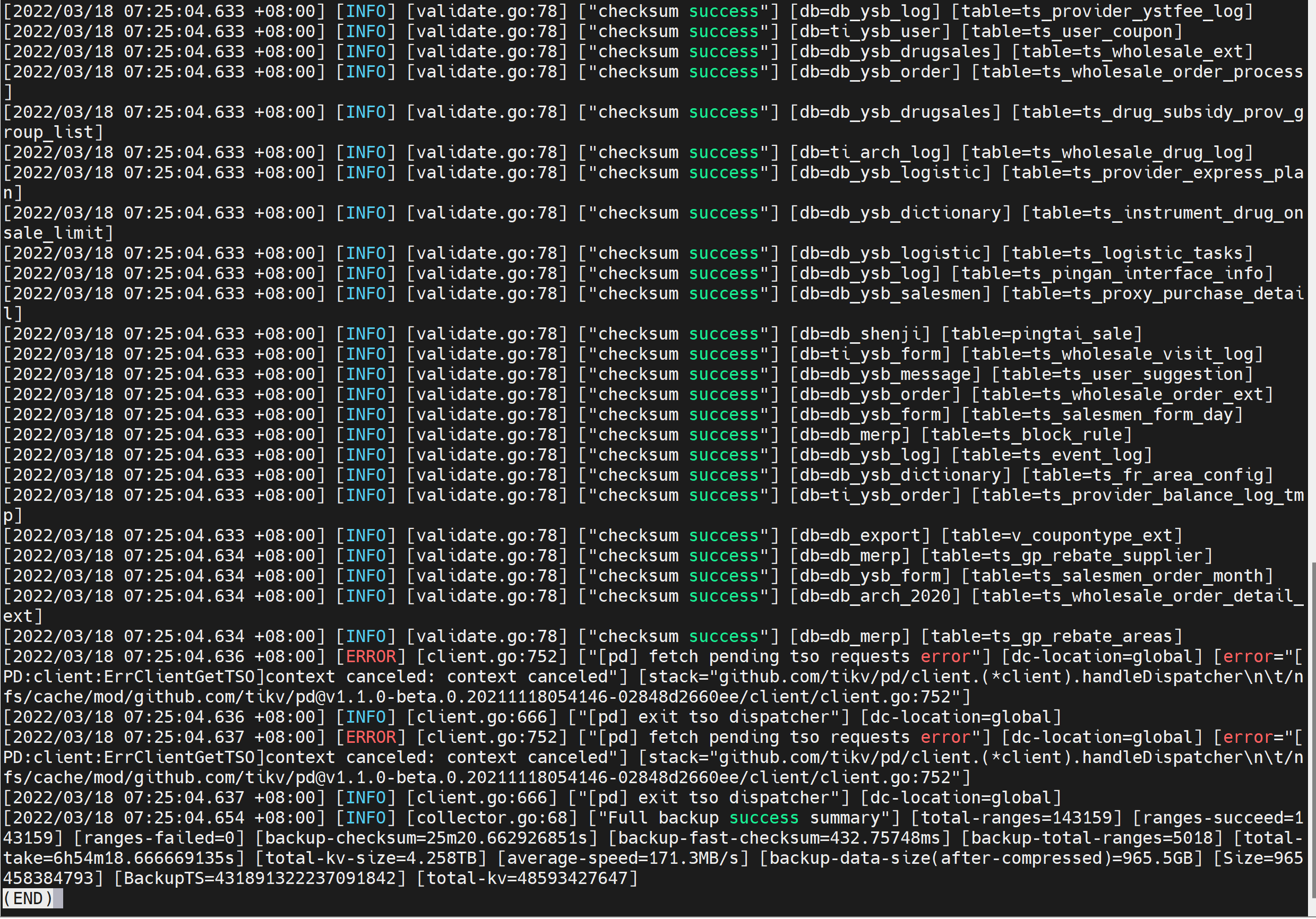
pd这几个warning应该都是正常情况,看BR日志最后备份是成功了
和这个帖子情况很像,应该只是日志输出的问题。
1 个赞
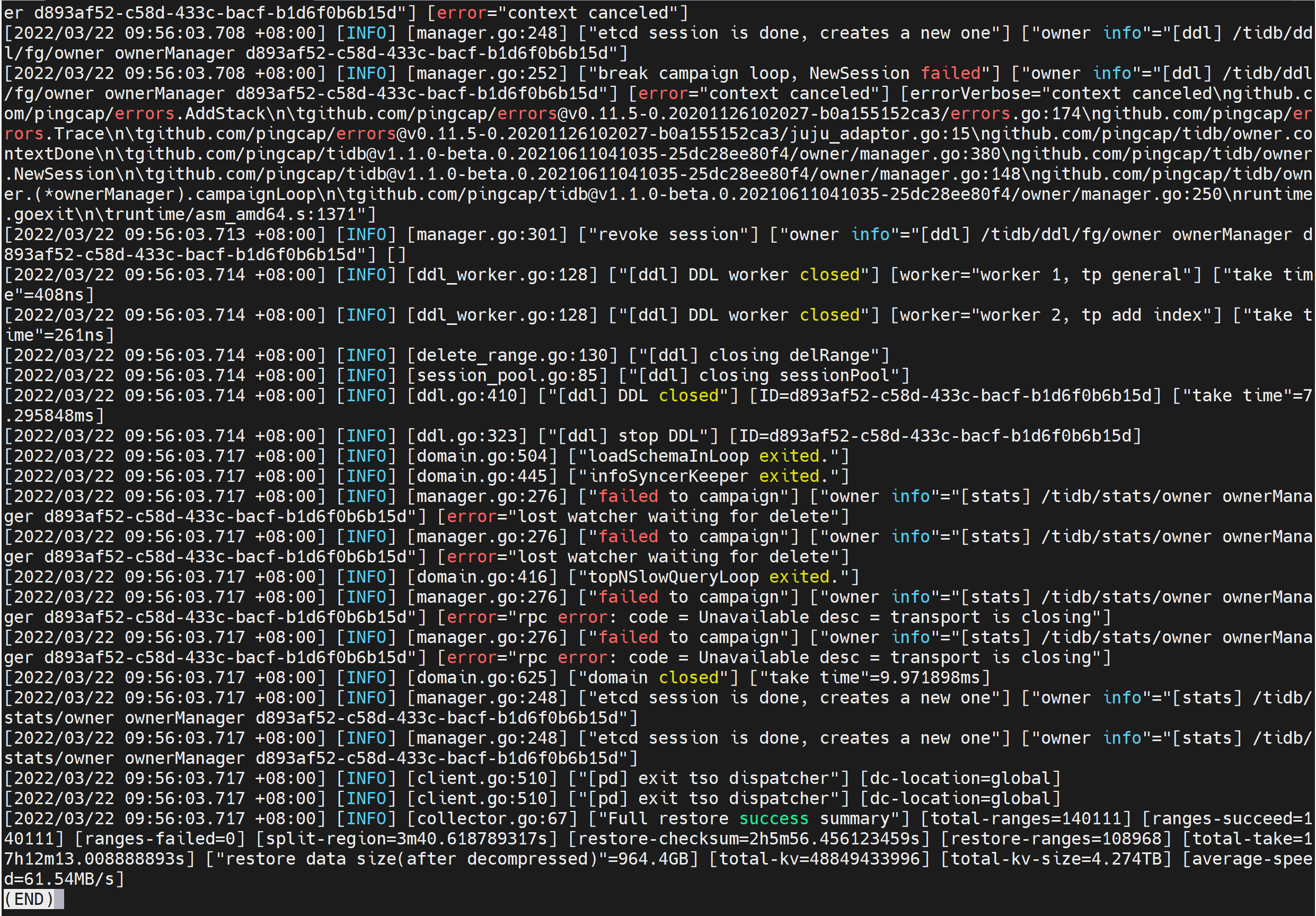
这个报错好像并不能忽略,我们用这些备份的数据在全新的同版本TIDB集群中进行了BR全量恢复,最后出现以下错误:
BR日志文件:restore_full_20220317.tar.gz (11.5 MB)
xfworld
(魔幻之翼)
6
后面这篇的日志描述的 SST 文件没下载完成?
备份的时候,是否按照官方文档上的要求配置了 NFS 给所有的 tikv?
TSO 请求错误是 PD这边的,但是不会导致无法下载SST的
上下游tidb的所有的tikv、tiflash、pd节点都有挂载这个nfs盘。
之前用v5.1.1版本的tidb时,br备份与恢复过程均没有出现错误,本周升级到v5.4.0后环境基本没有做改动,但是在用v5.4.0版本的br备份的时候就出现[pd] fetch pending tso requests error错误。
我们有备份任务每天都跑BR备份,我看今天的备份日志还是同样的问题,下图为今天BR备份的日志截图
xfworld
(魔幻之翼)
10
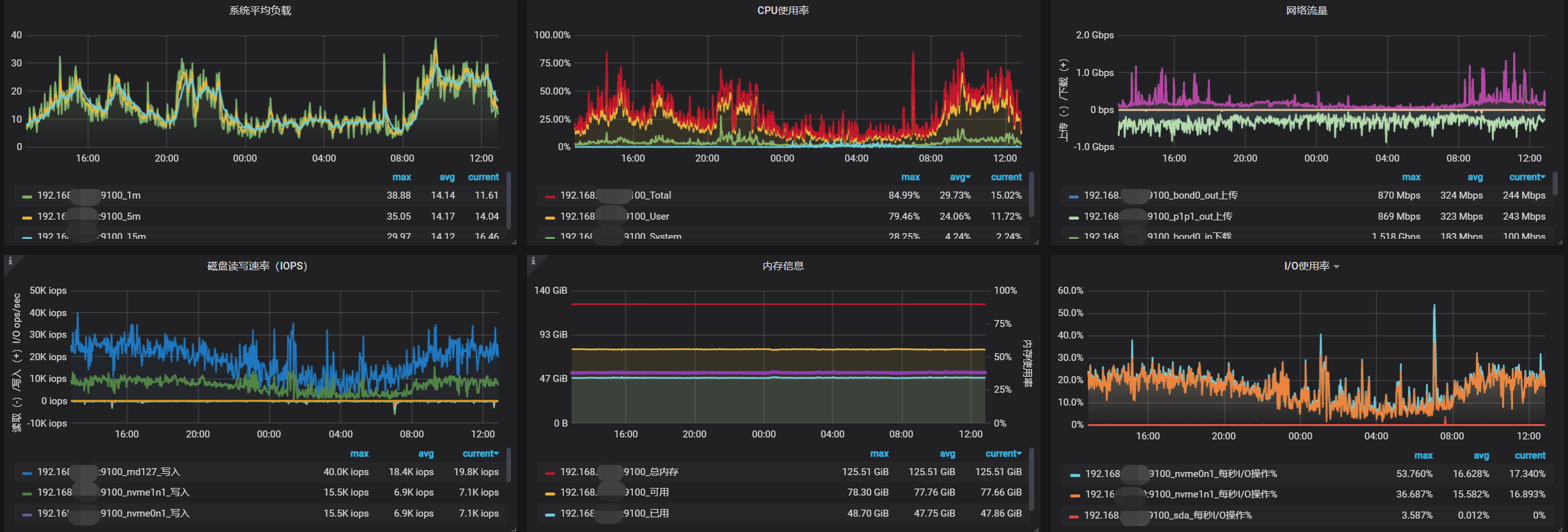
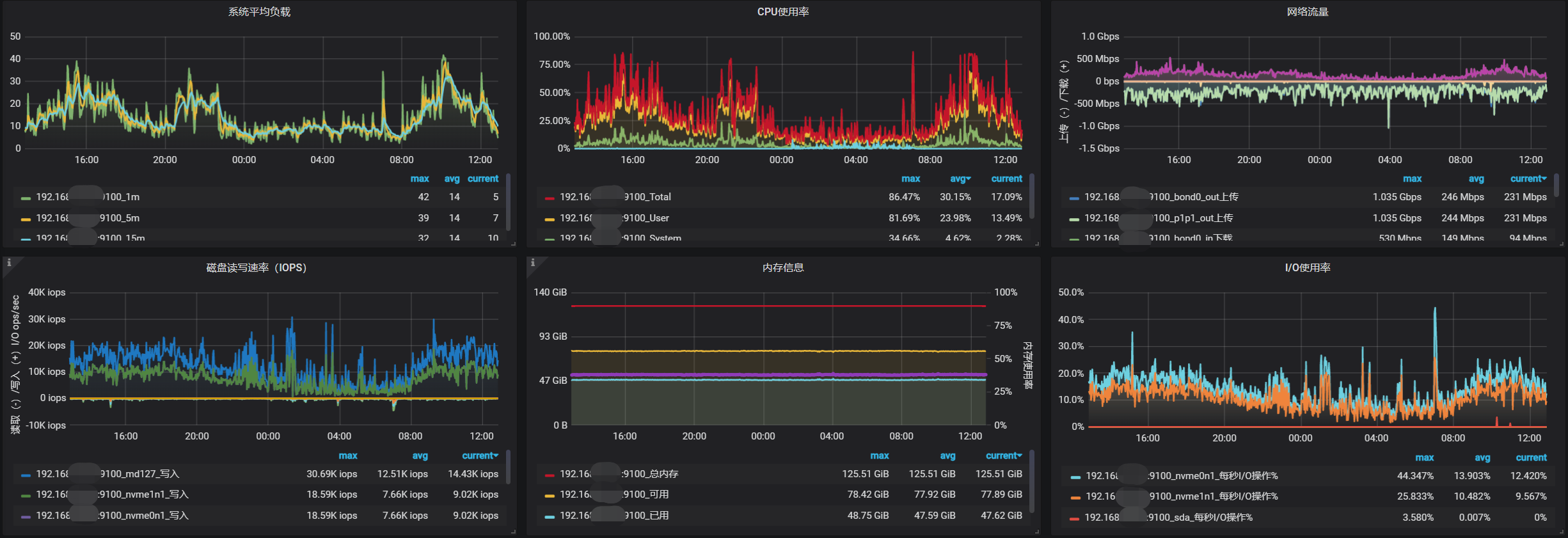
PD 在 早上 7点20 - 7点 30 的监控信息有么?
环境的配置网络足够么?
啦啦啦啦啦
11
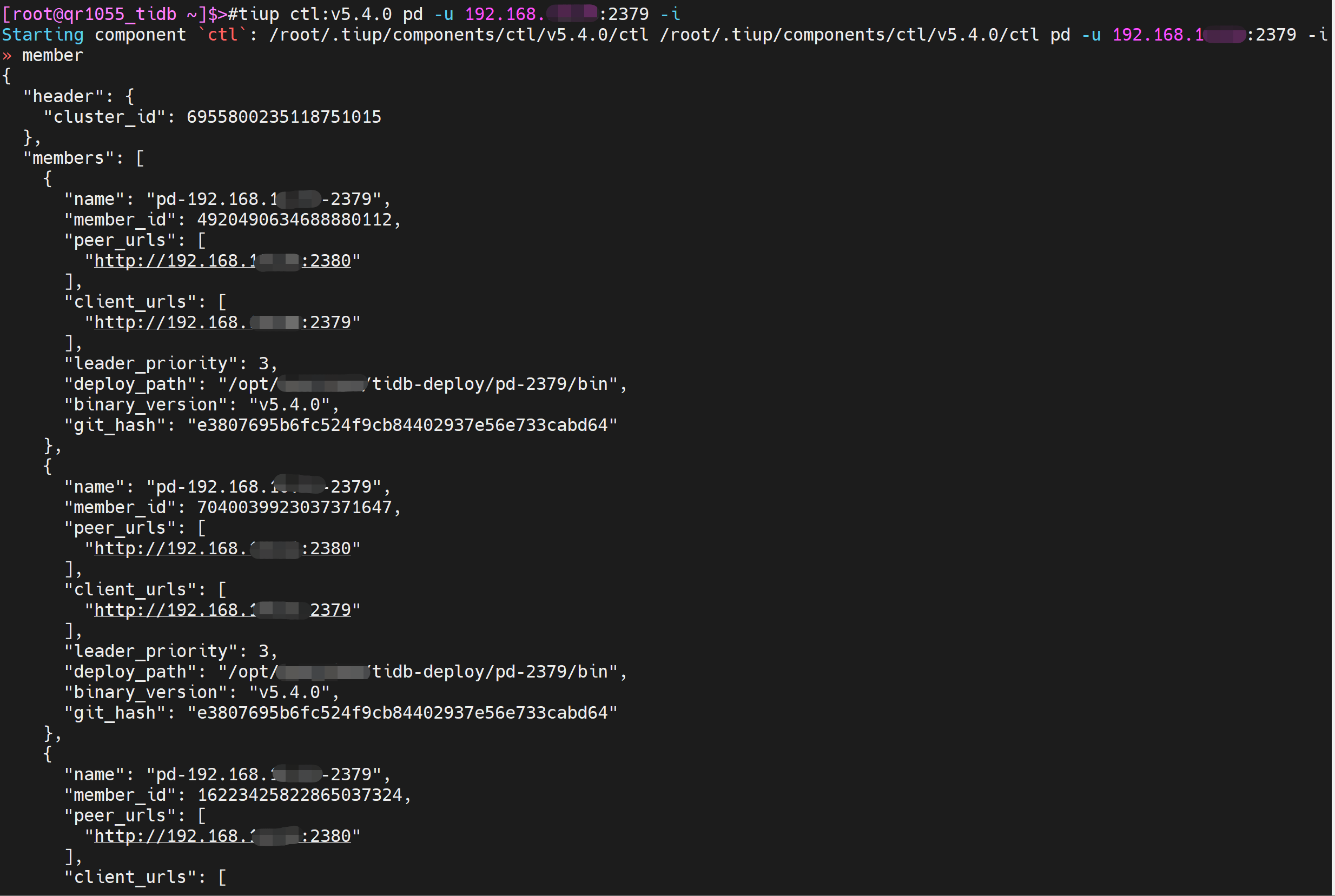
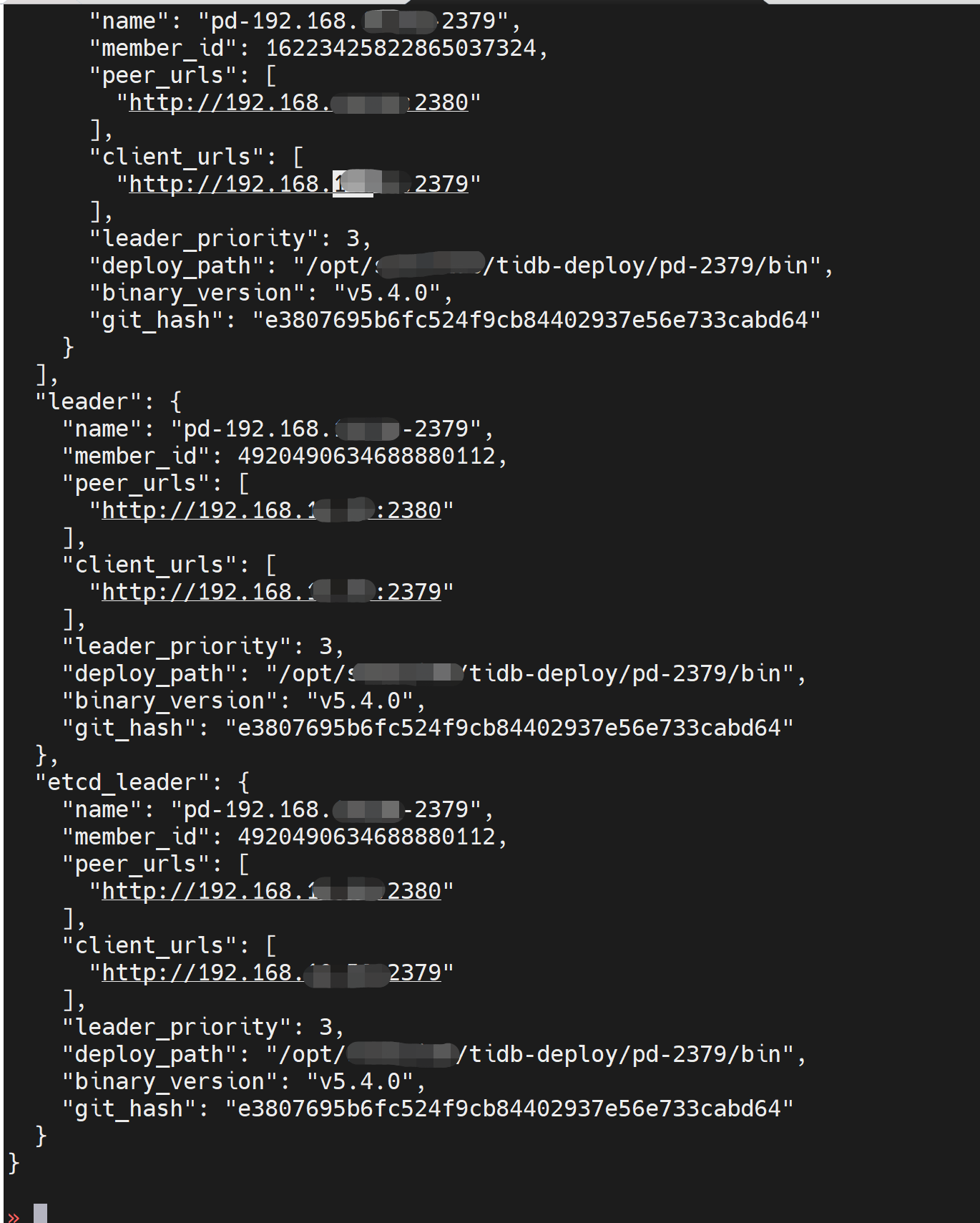
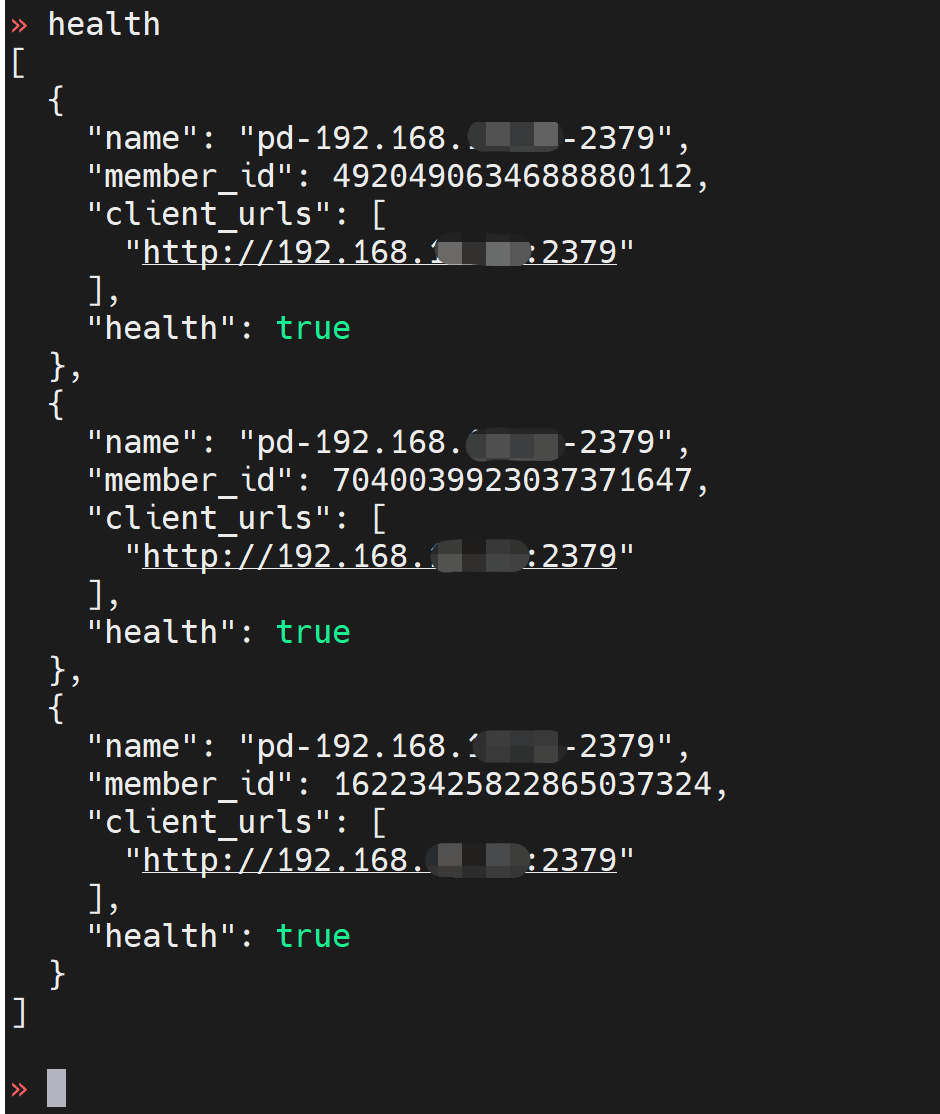
tiup ctl pd看看pd member和health状态
那现在怎样才能解决这个问题啊?
我们BR备份时的–ratelimit参数设置的35,这个参数要调小吗?还是说要改其它设置?
xfworld
(魔幻之翼)
16
–ratelimit 是限制tikv 速率的,对PD 没作用
- 在业务较少的时段,执行试试
- 追加硬件配置,满足性能要求
1.备份任务是在每天0:00开始的,8:00之前基本能结束,这已是业务量最小的时间段了。
2.应该不是性能问题,我看pd节点所在的3台服务器没有达到性能瓶颈,而且在v5.1.1版本没有这个问题啊,怎么升级了一个版本就出现性能问题了?
以下是3台pd节点服务器的监控信息:
YuJuncen
(Yu Juncen)
19
话说能否检查一下硬盘的状态呢?看起来备份文件似乎已经因为未知原因损坏了,经验上这种状况大多发生于备份盘接近寿命上限的时候。(也可以将涉事 SST 下载下来使用 RocksDB 的 ldb 工具检查一下。)
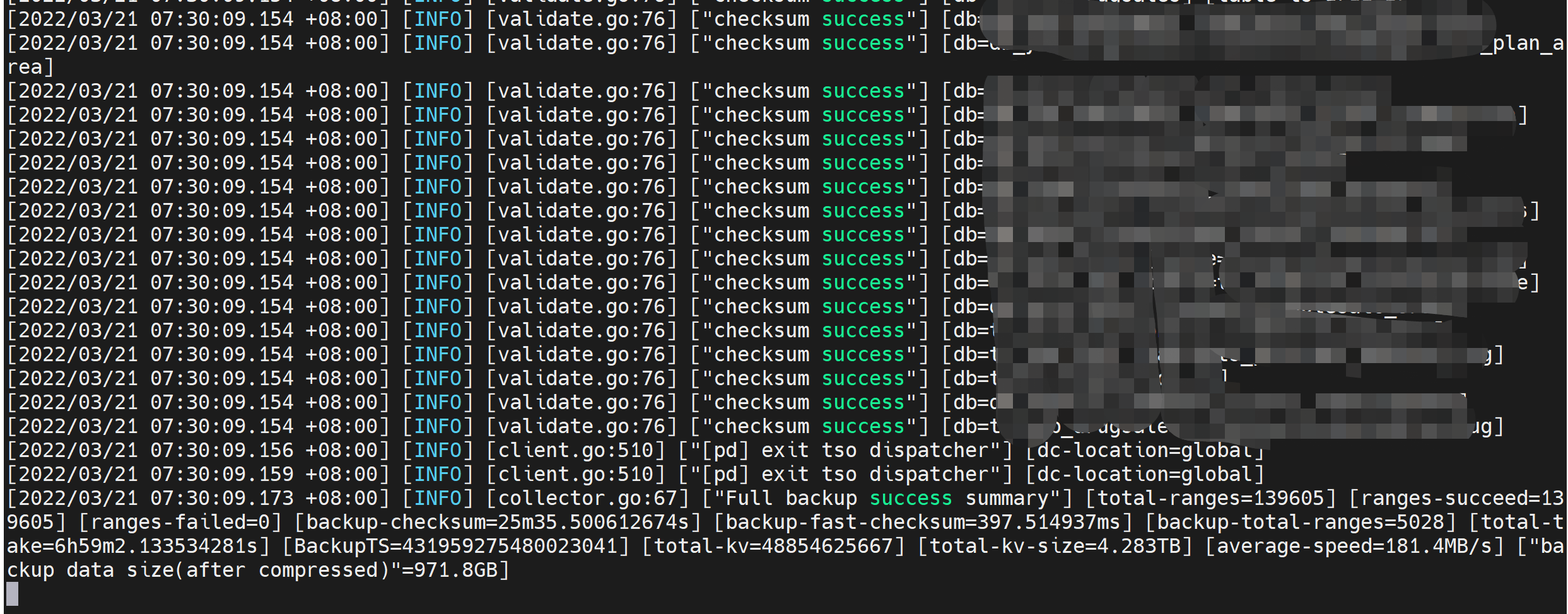
BR工具已退回v5.1.1版本,备份过程未发现报错:
恢复过程也未发现错误日志,但是最后的这些error和fail信息不太清楚是什么情况。