为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:tidb v4.0.0 dm v1.0.3
- 【问题描述】:
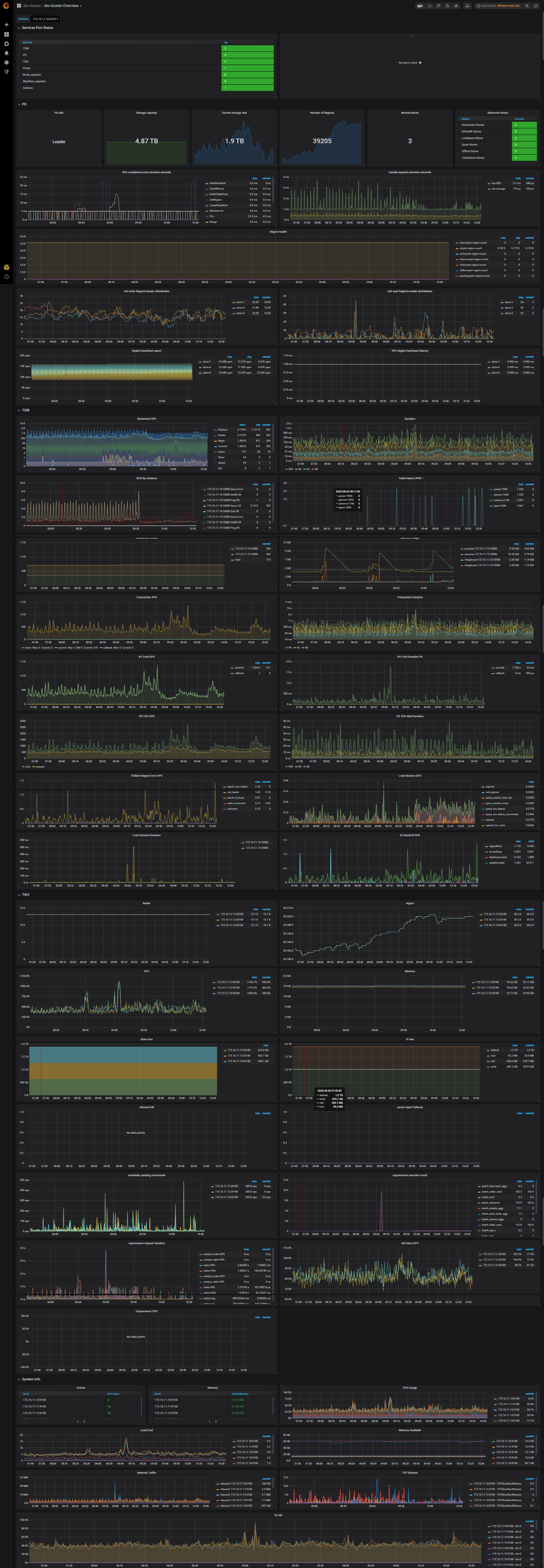
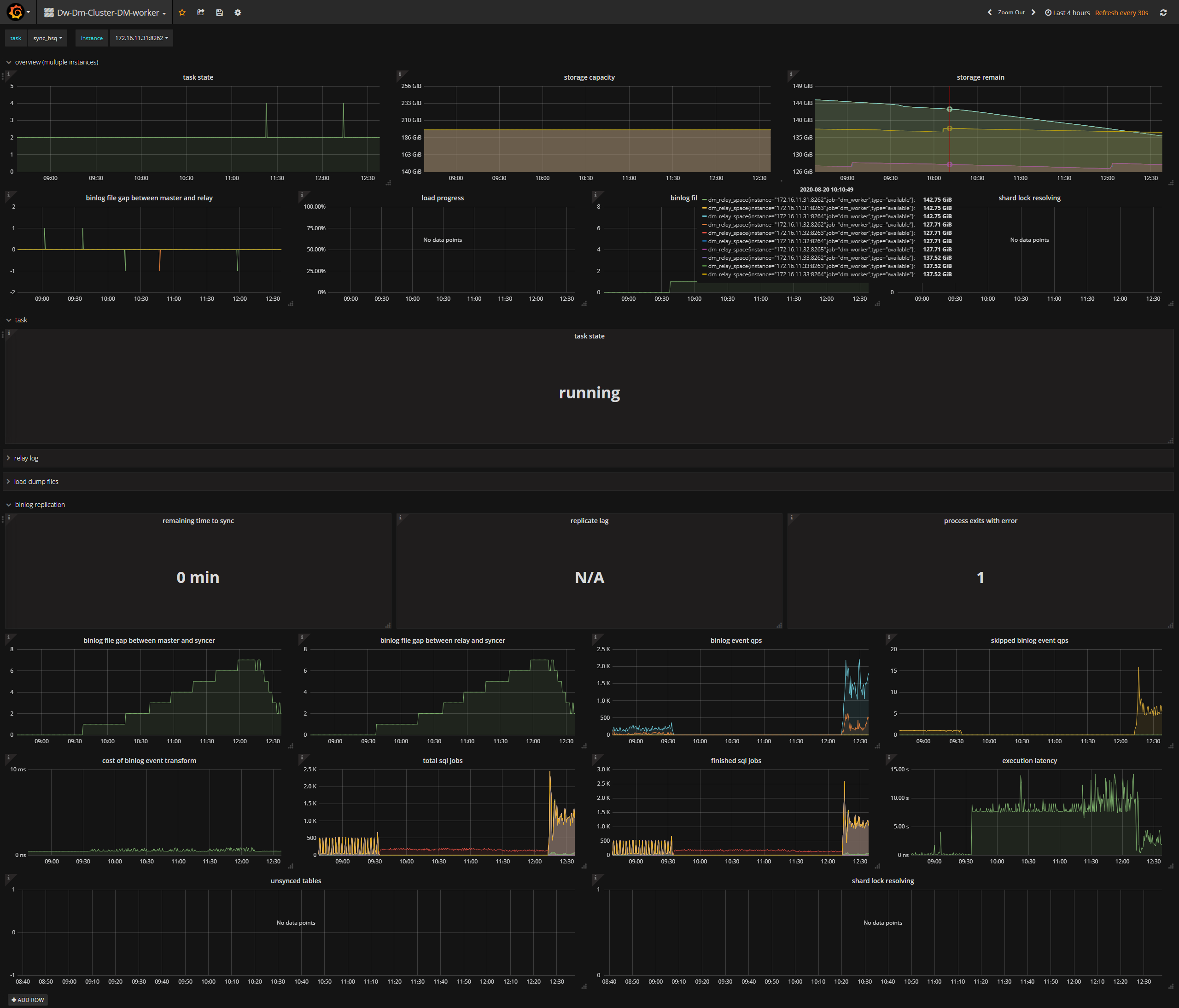
上午9点半前后,上游mysql执行十几条update语句,无where条件,全表更新,然后DM同步开始出现延迟严重,监控图如下:
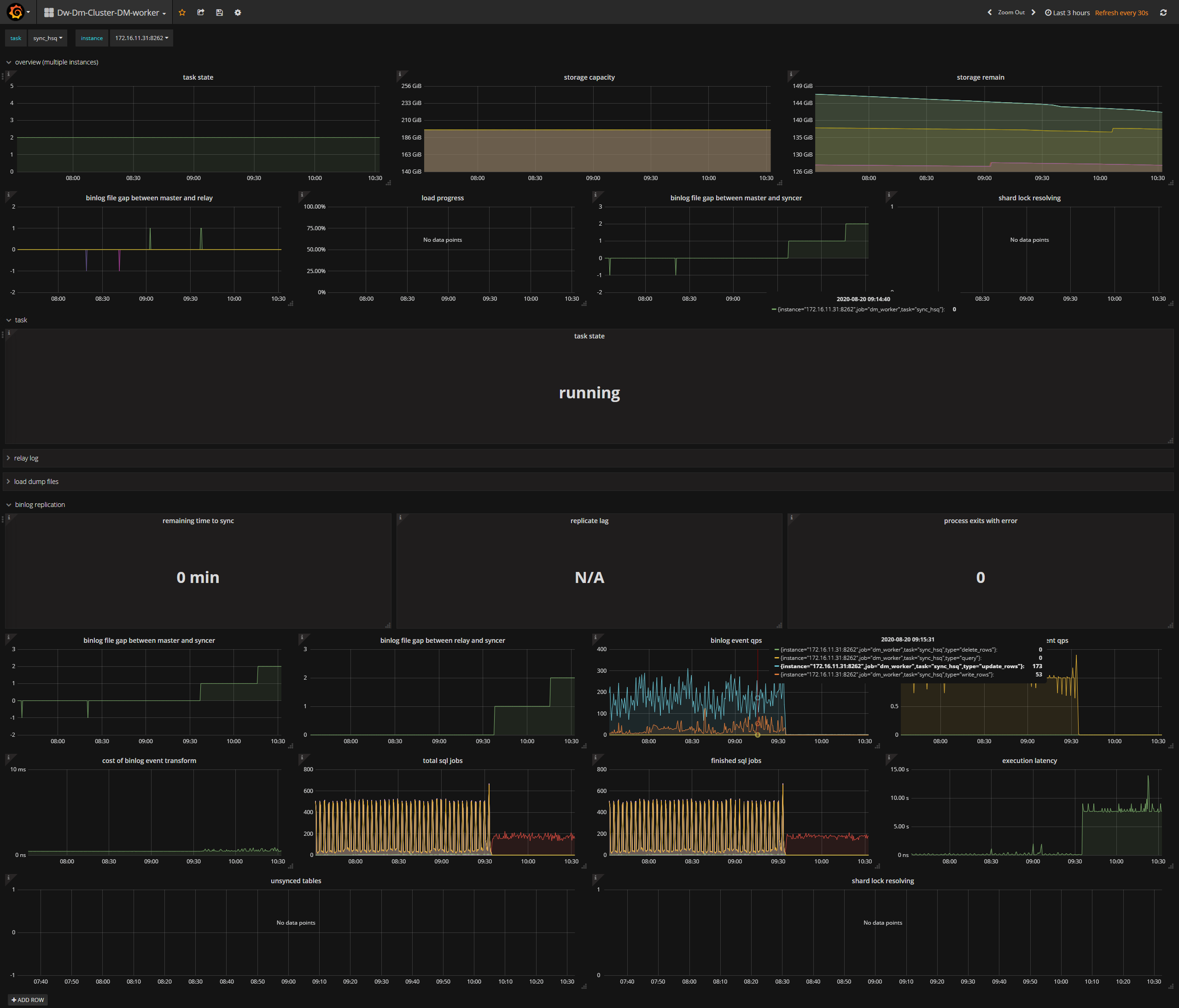
tidb集群监控图如下:
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
上午9点半前后,上游mysql执行十几条update语句,无where条件,全表更新,然后DM同步开始出现延迟严重,监控图如下:
tidb集群监控图如下:
我觉得很正常吧,你换算成mysql,对于这种大事务,就算原生mysql从库 肯定也会有延时
以下监控可以注意下:
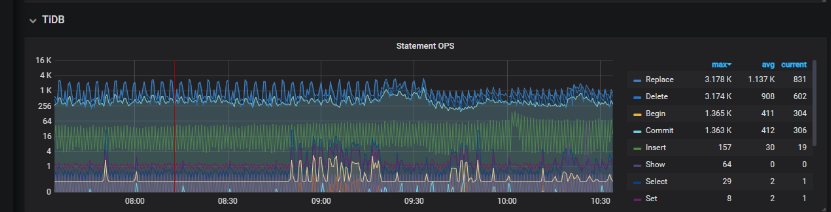
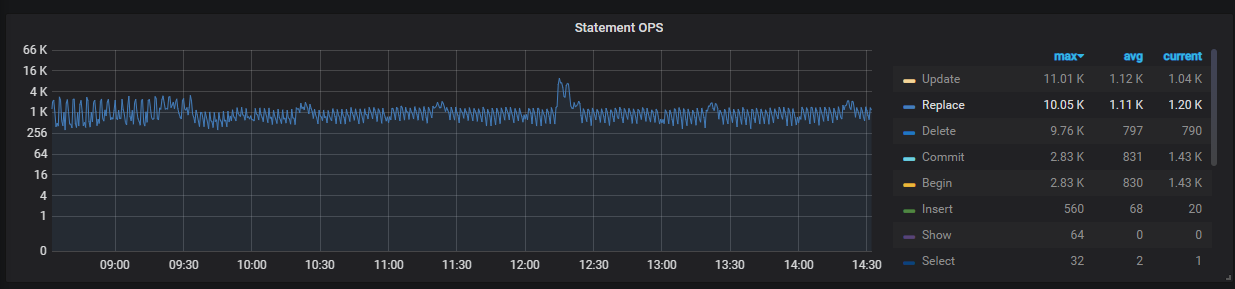
1、看下 dm task 文件,是否开启 safe mode 模式在同步,目前看 tidb 执行的 sql,replace 很高
关键原生的从库,只是9点半那个十来分钟有延迟,9点四五十就追上了。
但是tidb已经延迟快两个小时了
是开启safe-mode模式,这个关闭可以提速吗?关掉有什么影响吗?
辛苦先看下 safe mode,默认也是 false 的状态,不知为什么你们需要设置成 true。如果不是非必须使用建议关闭,会提升很大的性能。
分布式数据库和单机 mysql 在某些场景不具备可比性哈,这个应该是个共识吧。可以将问题关注在为什么慢上面。
根据此楼和楼上的回复操作下,辛苦
safe-mode已经关闭了,观察了半个多小时,延迟没有降,继续在增加
修改region merge,现在的版本4.0.0,查看已经是开启的。我搜到的帖子:[FAQ] 解决已经开启 region merge, empty-region-count 仍然很多问题
这里面的
region merge没改动,我刚把DM同步任务中的 worker-count由128调整为512,DM同步再次重启,同步就好了
这就奇怪了,难道是第一个重启,safe-mode没生效,还有是之前的worker-count配置有点小吗
可以通过 tidb statement ops 看下 replace 语句是否减少,或者 dm worker log 看下 safe mode 是否关闭。
调整 syncers 线程数也是优化的手段之一,在文档中有所体现,目前没有最佳的标准,根据实际情况设置即可,由于从 tidb 的监控上看 duration 没有到 s 级别,况且有其他指标可以优化所以在第一步优化中没有提到此信息。
dm 在启动前 5 min 会进行 replace into 的操作,后面会切换回去,应该是上游存在的 replace into 的 sql 导致的吧。