15:50分左右
有可能是 reload 的 evict leader 的 scheduler 没有正常清理掉,再看下 pd scheduler 下面的监控?
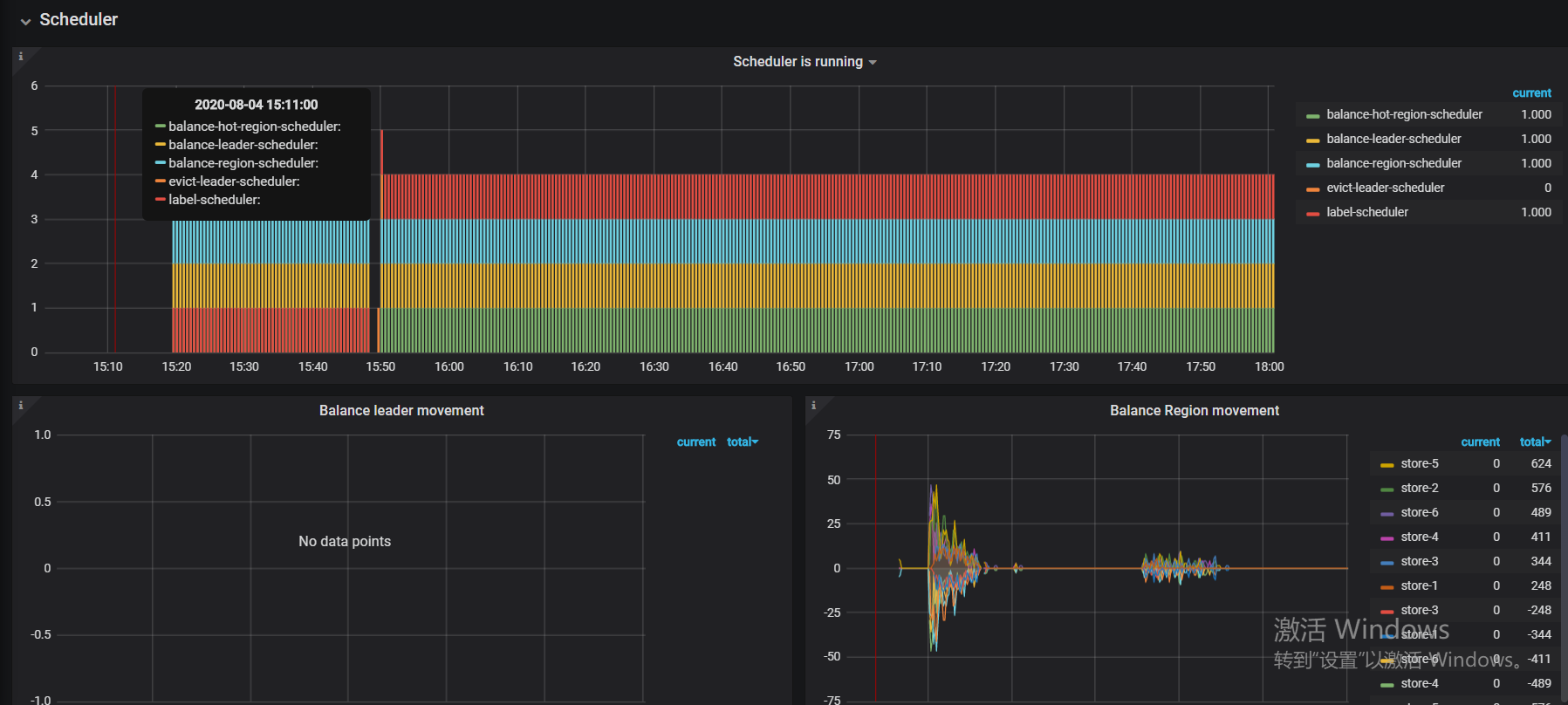
问题重新描述一遍:
tidb 版本:
v4.0.4
1、在使用tiup reload之后,会造成leader region不均衡;重新用tiup restart 之后,leader region开始均衡
2、单机多实例,打上了label,压测的时候发现leader region不是很均衡;貌似hot region也不是太均衡
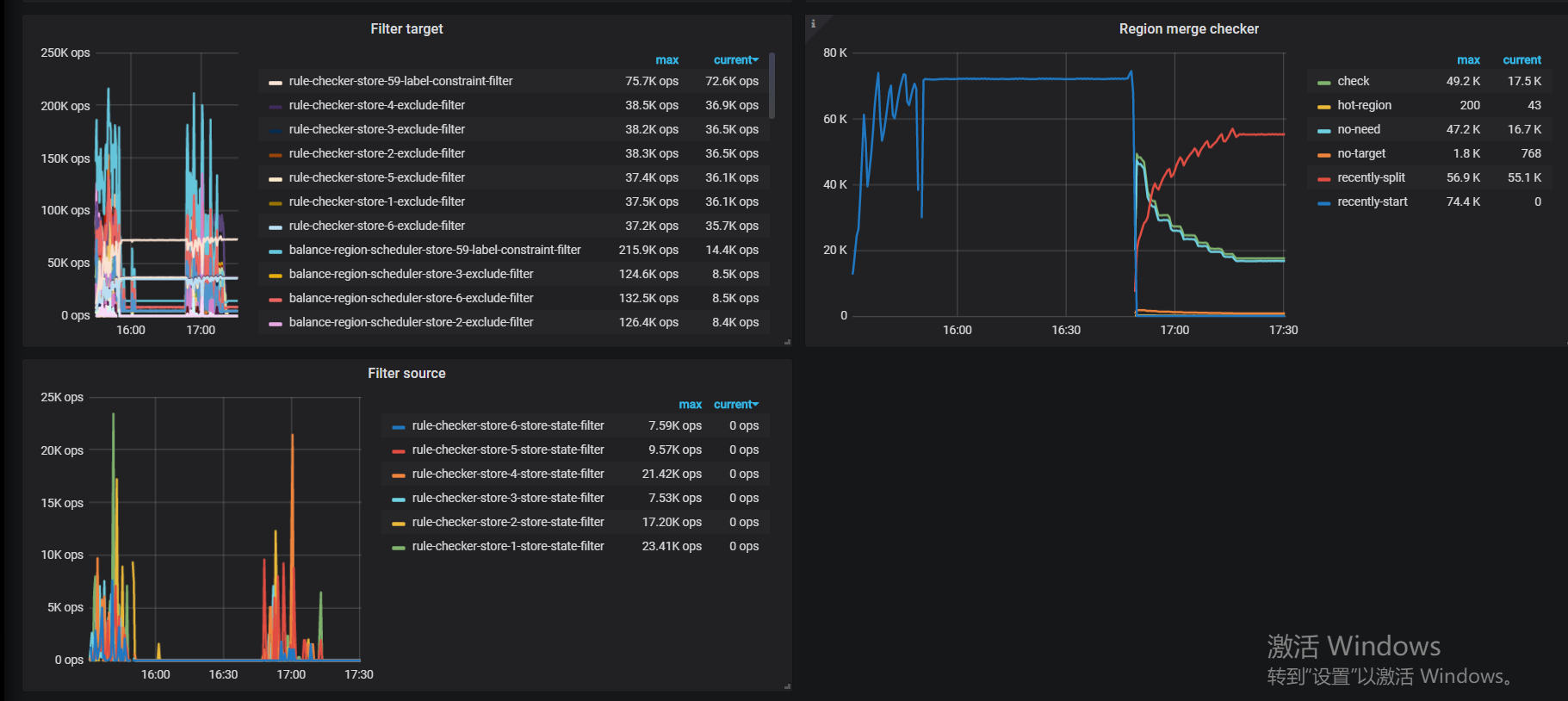
下面有 filter target 和 filter source 的面板,麻烦也截一下
filter target 麻烦截全一点
或者麻烦导一份完整的 pd 监控吧


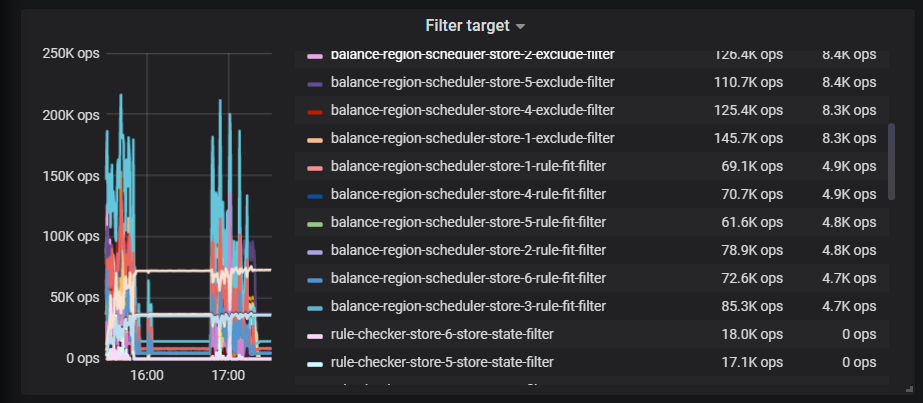
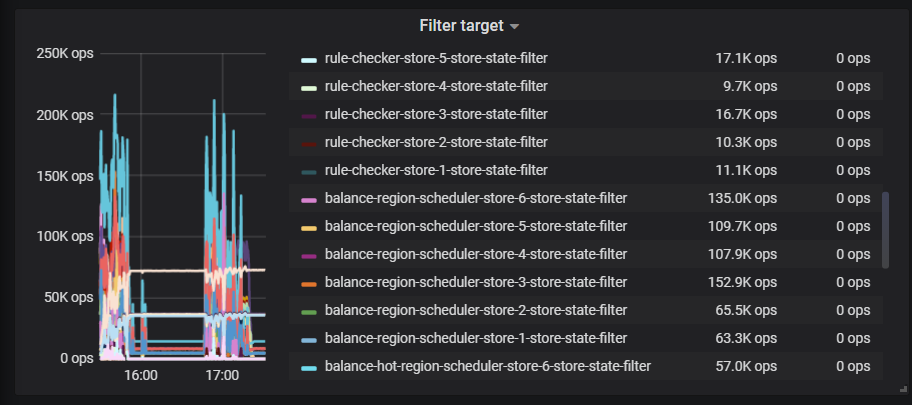

filter target 有 balance leader 相关的吗
没看到,应该是没有
pd-ctl config show all 的结果麻烦也贴一下吧
另外看到您这边有 tiflash, 可以看下 pd-ctl config placement-rules show 的结果
» config show
{
"replication": {
"enable-placement-rules": "true",
"location-labels": "host",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "false",
"enable-debug-metrics": "false",
"enable-location-replacement": "true",
"enable-make-up-replica": "true",
"enable-one-way-merge": "false",
"enable-remove-down-replica": "true",
"enable-remove-extra-replica": "true",
"enable-replace-offline-replica": "true",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 64,
"leader-schedule-limit": 16,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-pending-peer-count": 16,
"max-snapshot-count": 3,
"max-store-down-time": "30m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "100ms",
"region-schedule-limit": 2048,
"replica-schedule-limit": 256,
"scheduler-max-waiting-operator": 5,
"split-merge-interval": "1h0m0s",
"store-limit-mode": "manual",
"tolerant-size-ratio": 0
}
}
» config placement-rules show
[
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3,
"location_labels": [
"host"
]
}
]
请问您这是测试环境吗?
目前是压测环境
是否可以使用 v4.0.2,目前推断是 v4.0.3 引入的修改导致 balance-leader 没有正常工作。
可以使用
意思是v4.0.3就有这个问题么?
是的,建议测试的话可以先使用 v4.0.2