管理工具:
tiup
tidb 版本:
v4.0.4
问题:
tiup cluster reload clustername
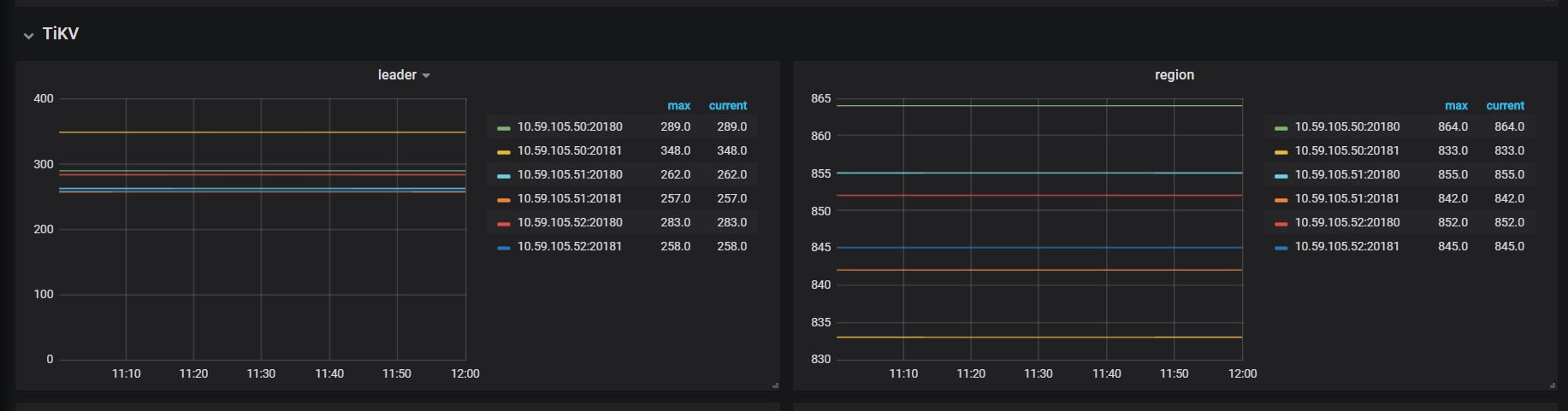
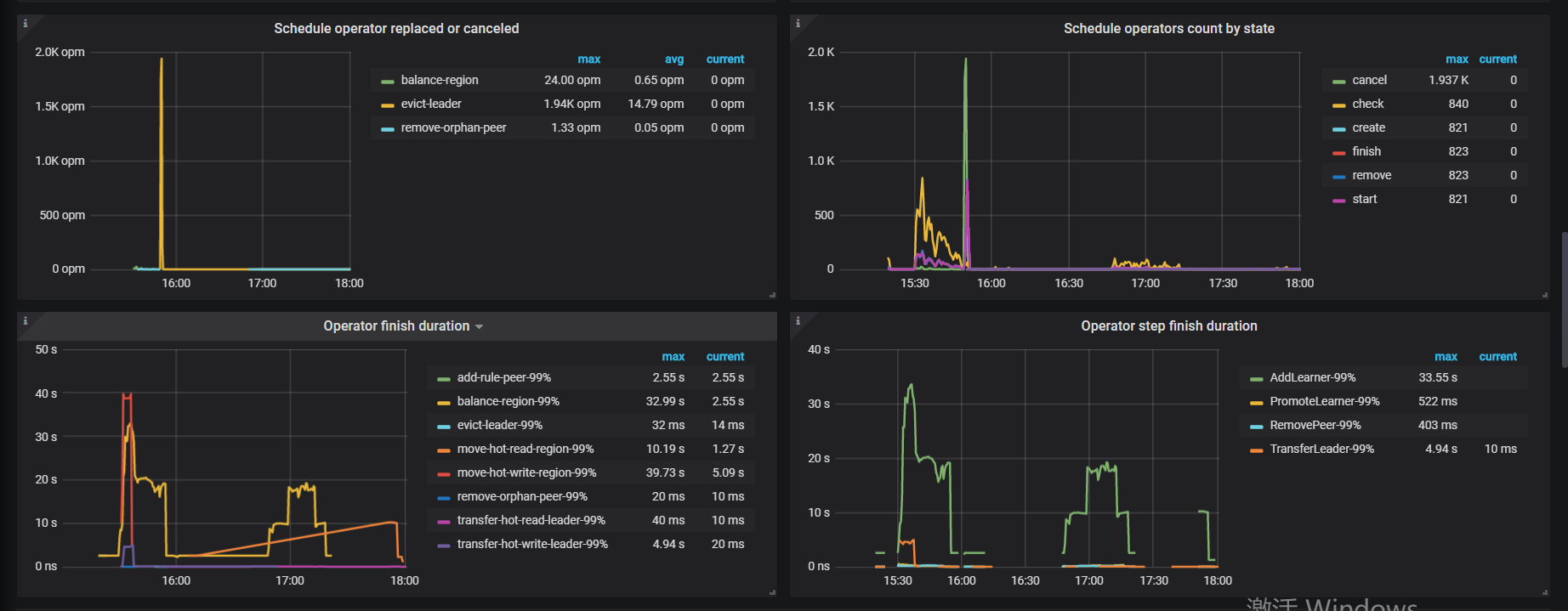
tikv 重载之后leader region不均衡,有一个节点直接为0
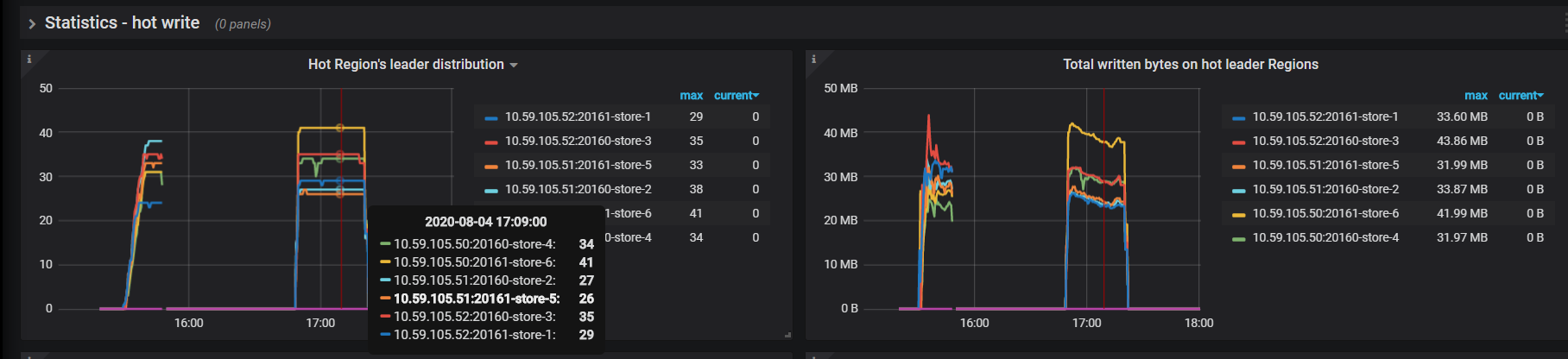
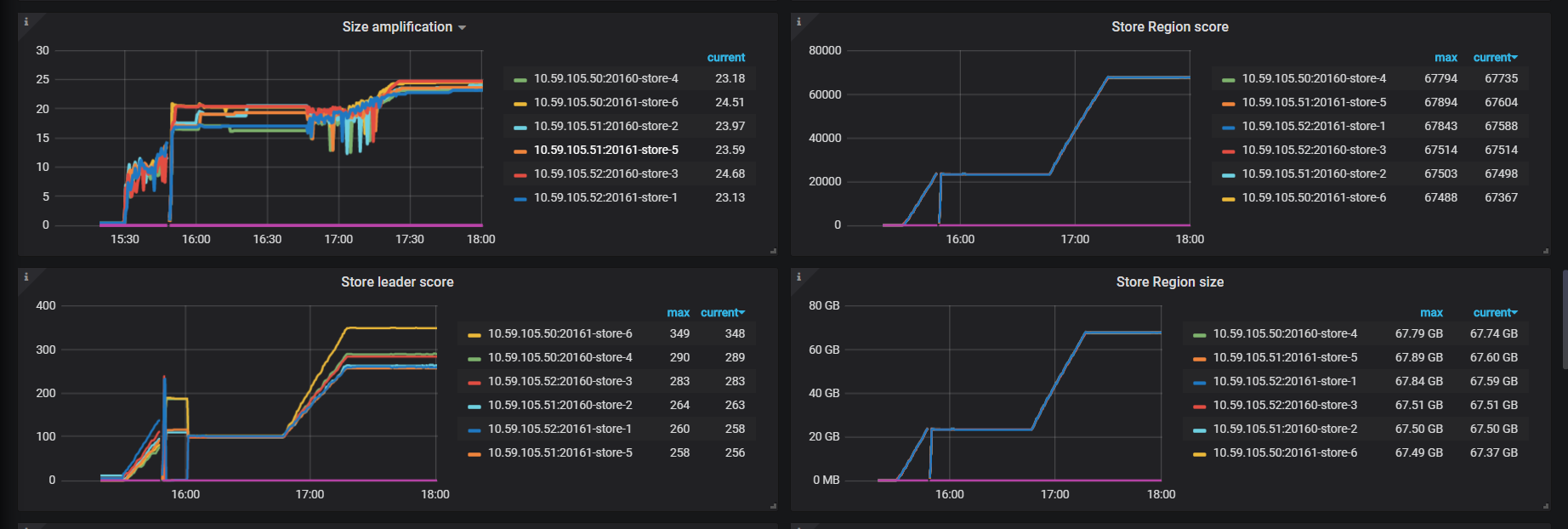
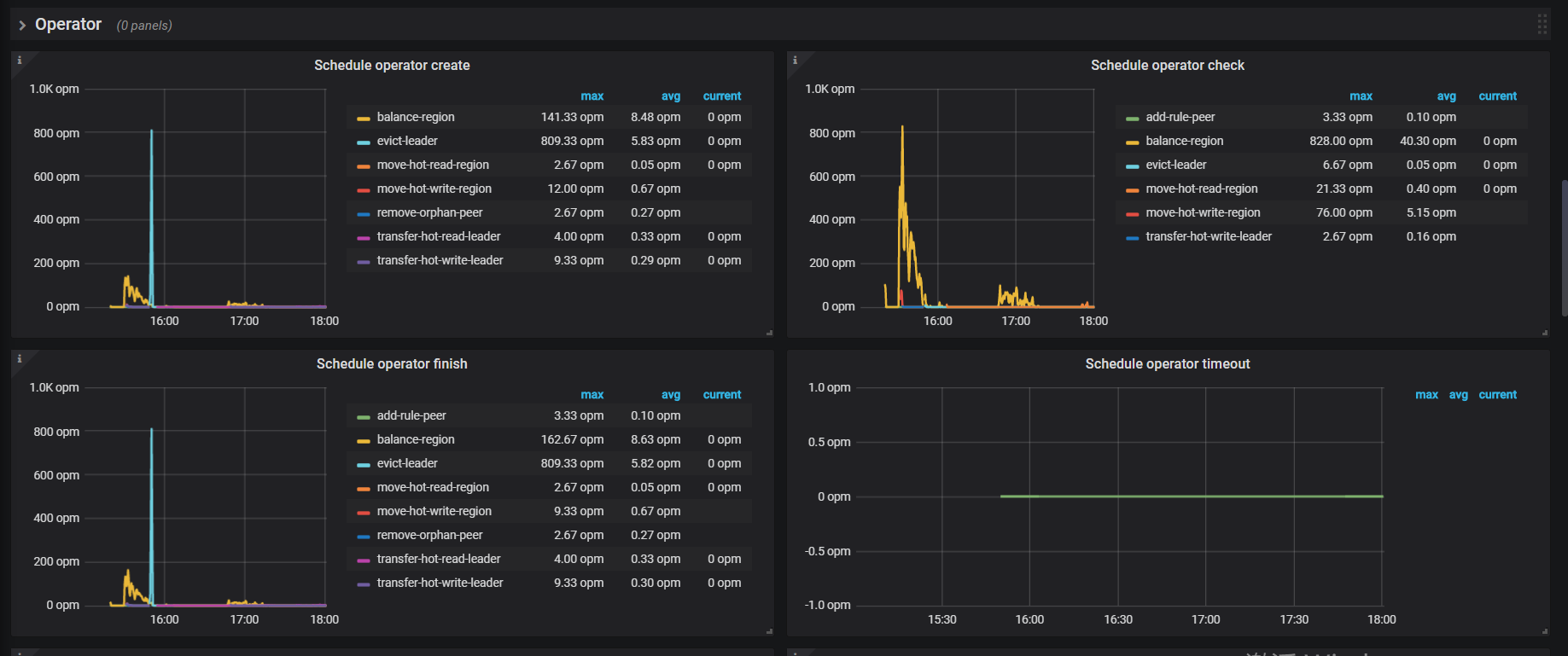
grafana 监控图:

topology:
TiDB Version: v4.0.4
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
10.59.105.70:9093 alertmanager 10.59.105.70 9093/9094 linux/x86_64 Up /data/alertmanager/data /data/alertmanager
10.59.105.70:3000 grafana 10.59.105.70 3000 linux/x86_64 Up - /data/grafana
10.59.105.60:2379 pd 10.59.105.60 2379/2380 linux/x86_64 Up|L /data/pd/data /data/pd
10.59.105.61:2379 pd 10.59.105.61 2379/2380 linux/x86_64 Up /data/pd/data /data/pd
10.59.105.62:2379 pd 10.59.105.62 2379/2380 linux/x86_64 Up /data/pd/data /data/pd
10.59.105.70:9090 prometheus 10.59.105.70 9090 linux/x86_64 Up /data/prometheus/data /data/prometheus
10.59.105.60:4000 tidb 10.59.105.60 4000/10080 linux/x86_64 Up - /data/tidb
10.59.105.61:4000 tidb 10.59.105.61 4000/10080 linux/x86_64 Up - /data/tidb
10.59.105.62:4000 tidb 10.59.105.62 4000/10080 linux/x86_64 Up - /data/tidb
10.59.105.70:9000 tiflash 10.59.105.70 9000/8123/3930/20170/20292/8234 linux/x86_64 Up /data/tiflash/data /data/tiflash
10.59.105.50:20160 tikv 10.59.105.50 20160/20180 linux/x86_64 Up /data/tikv/20160/deploy/store /data/tikv/20160/deploy
10.59.105.50:20161 tikv 10.59.105.50 20161/20181 linux/x86_64 Up /data/tikv/20161/deploy/store /data/tikv/20161/deploy
10.59.105.51:20160 tikv 10.59.105.51 20160/20180 linux/x86_64 Up /data/tikv/20160/deploy/store /data/tikv/20160/deploy
10.59.105.51:20161 tikv 10.59.105.51 20161/20181 linux/x86_64 Up /data/tikv/20161/deploy/store /data/tikv/20161/deploy
10.59.105.52:20160 tikv 10.59.105.52 20160/20180 linux/x86_64 Up /data/tikv/20160/deploy/store /data/tikv/20160/deploy
10.59.105.52:20161 tikv 10.59.105.52 20161/20181 linux/x86_64 Up /data/tikv/20161/deploy/store /data/tikv/20161/deploy