在升级过程中 先是使用 tiup cluster upgrade cluster_name ; 升级 , 但由于kv节点处理太久 , 于是ctrl+c 中止
再次 升级时加了 --force: tiup cluster upgrade cluster_name --force ,升级完 后, 有一个kv节点没有leader了 , 请问这是什么原因 ,怎么恢复
你好,
在升级过程中使用 ctrl+c 可能导致 pd 调度中的 evict-leader-scheduler 调度项无法被正常清理,请返回下以下命令内容,这边判断下:
tiup ctl pd -u http://pdip:pdport scheduler show / config show all
信息如下:
» scheduler show
[
“balance-hot-region-scheduler”,
“balance-leader-scheduler”,
“balance-region-scheduler”,
“evict-leader-scheduler”,
“label-scheduler”
]
» config show all
{
“client-urls”: “http://0.0.0.0:2379”,
“peer-urls”: “http://10.xx.xx.34:2380”,
“advertise-client-urls”: “http://10.xx.xx.34:2379”,
“advertise-peer-urls”: “http://10.xx.xx.34:2380”,
“name”: “pd_10.xx.xx.34”,
“data-dir”: “/data/tidb/deploy/data.pd”,
“force-new-cluster”: false,
“enable-grpc-gateway”: true,
“initial-cluster”: “pd_10.xx.xx.33=http://10.xx.xx.33:2380,pd_10.xx.xx.34=http://10.xx.xx.34:2380,pd_10.xx.xx.35=http://10.xx.xx.35:2380”,
“initial-cluster-state”: “new”,
“join”: “”,
“lease”: 3,
“log”: {
“level”: “info”,
“format”: “text”,
“disable-timestamp”: false,
“file”: {
“filename”: “/data/tidb/deploy/log/pd.log”,
“max-size”: 300,
“max-days”: 0,
“max-backups”: 0
},
“development”: false,
“disable-caller”: false,
“disable-stacktrace”: false,
“disable-error-verbose”: true,
“sampling”: null
},
“tso-save-interval”: “3s”,
“metric”: {
“job”: “pd_10.xx.xx.34”,
“address”: “”,
“interval”: “15s”
},
“schedule”: {
“max-snapshot-count”: 3,
“max-pending-peer-count”: 16,
“max-merge-region-size”: 20,
“max-merge-region-keys”: 200000,
“split-merge-interval”: “1h0m0s”,
“enable-one-way-merge”: “false”,
“enable-cross-table-merge”: “false”,
“patrol-region-interval”: “100ms”,
“max-store-down-time”: “30m0s”,
“leader-schedule-limit”: 4,
“leader-schedule-policy”: “count”,
“region-schedule-limit”: 4,
“replica-schedule-limit”: 8,
“merge-schedule-limit”: 4,
“hot-region-schedule-limit”: 4,
“hot-region-cache-hits-threshold”: 3,
“store-limit”: {
“15182”: {
“add-peer”: 15,
“remove-peer”: 15
},
“26585”: {
“add-peer”: 15,
“remove-peer”: 15
},
“4”: {
“add-peer”: 15,
“remove-peer”: 15
}
},
“tolerant-size-ratio”: 5,
“low-space-ratio”: 0.8,
“high-space-ratio”: 0.6,
“scheduler-max-waiting-operator”: 3,
“enable-remove-down-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“enable-make-up-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-location-replacement”: “true”,
“enable-debug-metrics”: “false”,
“schedulers-v2”: [
{
“type”: “balance-region”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “balance-leader”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “hot-region”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “label”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “evict-leader”,
“args”: [
“15182”
],
“disable”: false,
“args-payload”: “”
},
{
“type”: “evict-leader”,
“args”: [
“4”
],
“disable”: false,
“args-payload”: “”
}
],
“schedulers-payload”: {
“balance-hot-region-scheduler”: “null”,
“balance-leader-scheduler”: “{"name":"balance-leader-scheduler","ranges":[{"start-key":"","end-key":""}]}”,
“balance-region-scheduler”: “{"name":"balance-region-scheduler","ranges":[{"start-key":"","end-key":""}]}”,
“evict-leader-scheduler”: “{"store-id-ranges":{"4":[{"start-key":"","end-key":""}]}}”,
“label-scheduler”: “{"name":"label-scheduler","ranges":[{"start-key":"","end-key":""}]}”
},
“store-limit-mode”: “manual”
},
“replication”: {
“max-replicas”: 2,
“location-labels”: “”,
“strictly-match-label”: “false”,
“enable-placement-rules”: “false”
},
“pd-server”: {
“use-region-storage”: “true”,
“max-gap-reset-ts”: “24h0m0s”,
“key-type”: “table”,
“runtime-services”: “”,
“metric-storage”: “http://10.xx.xx.48:9090”,
“dashboard-address”: “http://10.xx.xx.35:2379”
},
“cluster-version”: “4.0.2”,
“quota-backend-bytes”: “8GiB”,
“auto-compaction-mode”: “periodic”,
“auto-compaction-retention-v2”: “1h”,
“TickInterval”: “500ms”,
“ElectionInterval”: “3s”,
“PreVote”: true,
“security”: {
“cacert-path”: “”,
“cert-path”: “”,
“key-path”: “”,
“cert-allowed-cn”: null
},
“label-property”: {},
“WarningMsgs”: [
“Config contains undefined item: namespace-classifier”
],
“DisableStrictReconfigCheck”: false,
“HeartbeatStreamBindInterval”: “1m0s”,
“LeaderPriorityCheckInterval”: “1m0s”,
“dashboard”: {
“tidb_cacert_path”: “”,
“tidb_cert_path”: “”,
“tidb_key_path”: “”,
“public_path_prefix”: “”,
“internal_proxy”: false,
“disable_telemetry”: false
},
“replication-mode”: {
“replication-mode”: “majority”,
“dr-auto-sync”: {
“label-key”: “”,
“primary”: “”,
“dr”: “”,
“primary-replicas”: 0,
“dr-replicas”: 0,
“wait-store-timeout”: “1m0s”,
“wait-sync-timeout”: “1m0s”
}
}
}
»
移除 “evict-leader-scheduler”, 此调度即可:
tiup ctl pd -u http://pdip:pdport scheduler remove evict-leader-scheduler
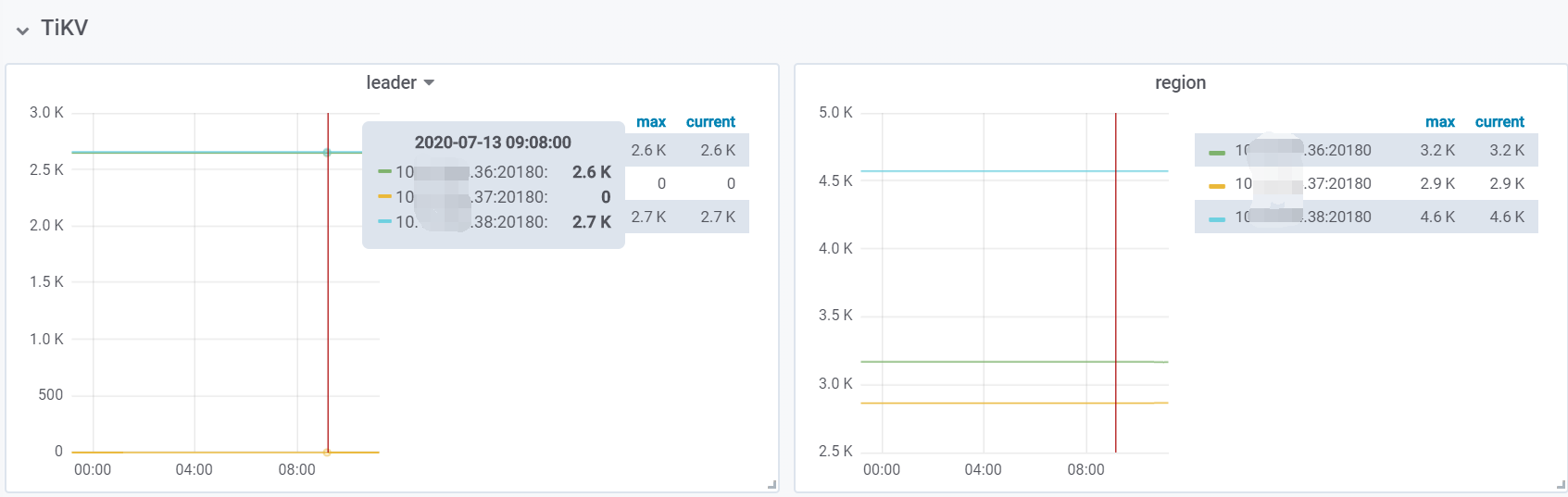
并通过 store 查看 leader count 0 的 tikv 节点是否有回升,并最终与其他 tikv 相同或接近
好的, 已经恢复了 , 谢谢
另外 ,请看下刚才图片的右边 regions 的分布, IP38的regions 比其他两台高出了一半的regions, 三台机器的配置完全一致,也只存放kv的数据 ,没存放其他东西,三台机的磁盘空间占用也接近 ,
36,37,38 数据盘占用空间分别为 9.3G ,8.6G, 7.4G
附上 store size 图表:
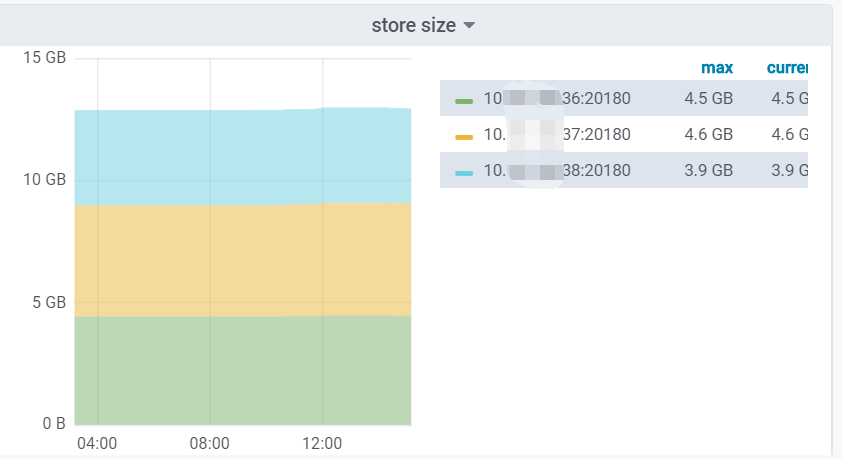
请问这是什么原因, 是否正常
请问三台 tikv 的 data dir 目录的总量是否完全相同呢



反馈下 pd-ctl store 的信息,看下 region_score 情况。
store 信息如下:
[tidb@localhost ~]$ tiup ctl pd -u 10.xx.xx.33:2379 store
Starting component ctl: /home/tidb/.tiup/components/ctl/v4.0.2/ctl pd -u 10.xx.xx.33:2379 store
{
“count”: 3,
“stores”: [
{
“store”: {
“id”: 4,
“address”: “10.xx.xx.37:20160”,
“version”: “4.0.2”,
“status_address”: “10.xx.xx.37:20180”,
“git_hash”: “98ee08c587ab47d9573628aba6da741433d8855c”,
“start_timestamp”: 1594428082,
“last_heartbeat”: 1594658544939357698,
“state_name”: “Up”
},
“status”: {
“capacity”: “101.4GiB”,
“available”: “92.92GiB”,
“used_size”: “4.2GiB”,
“leader_count”: 1764,
“leader_weight”: 1,
“leader_score”: 1764,
“leader_size”: 15086,
“region_count”: 2884,
“region_weight”: 1,
“region_score”: 21624,
“region_size”: 21624,
“start_ts”: “2020-07-11T08:41:22+08:00”,
“last_heartbeat_ts”: “2020-07-14T00:42:24.939357698+08:00”,
“uptime”: “64h1m2.939357698s”
}
},
{
“store”: {
“id”: 15182,
“address”: “10.xx.xx.36:20160”,
“version”: “4.0.2”,
“status_address”: “10.xx.xx.36:20180”,
“git_hash”: “98ee08c587ab47d9573628aba6da741433d8855c”,
“start_timestamp”: 1594421791,
“last_heartbeat”: 1594658549370108727,
“state_name”: “Up”
},
“status”: {
“capacity”: “101.3GiB”,
“available”: “92.04GiB”,
“used_size”: “4.071GiB”,
“leader_count”: 1771,
“leader_weight”: 1,
“leader_score”: 1771,
“leader_size”: 7879,
“region_count”: 3137,
“region_weight”: 1,
“region_score”: 21599,
“region_size”: 21599,
“start_ts”: “2020-07-11T06:56:31+08:00”,
“last_heartbeat_ts”: “2020-07-14T00:42:29.370108727+08:00”,
“uptime”: “65h45m58.370108727s”
}
},
{
“store”: {
“id”: 26585,
“address”: “10.xx.xx.38:20160”,
“version”: “4.0.2”,
“status_address”: “10.xx.xx.38:20180”,
“git_hash”: “98ee08c587ab47d9573628aba6da741433d8855c”,
“start_timestamp”: 1594455570,
“last_heartbeat”: 1594658551539271484,
“state_name”: “Up”
},
“status”: {
“capacity”: “101.5GiB”,
“available”: “94.12GiB”,
“used_size”: “3.596GiB”,
“leader_count”: 1766,
“leader_weight”: 1,
“leader_score”: 1766,
“leader_size”: 9461,
“region_count”: 4581,
“region_weight”: 1,
“region_score”: 21629,
“region_size”: 21629,
“start_ts”: “2020-07-11T16:19:30+08:00”,
“last_heartbeat_ts”: “2020-07-14T00:42:31.539271484+08:00”,
“uptime”: “56h23m1.539271484s”
}
}
]
}
看下 grafana 监控中 pd - scheduler 关于 region 的监控项,辛苦上传下

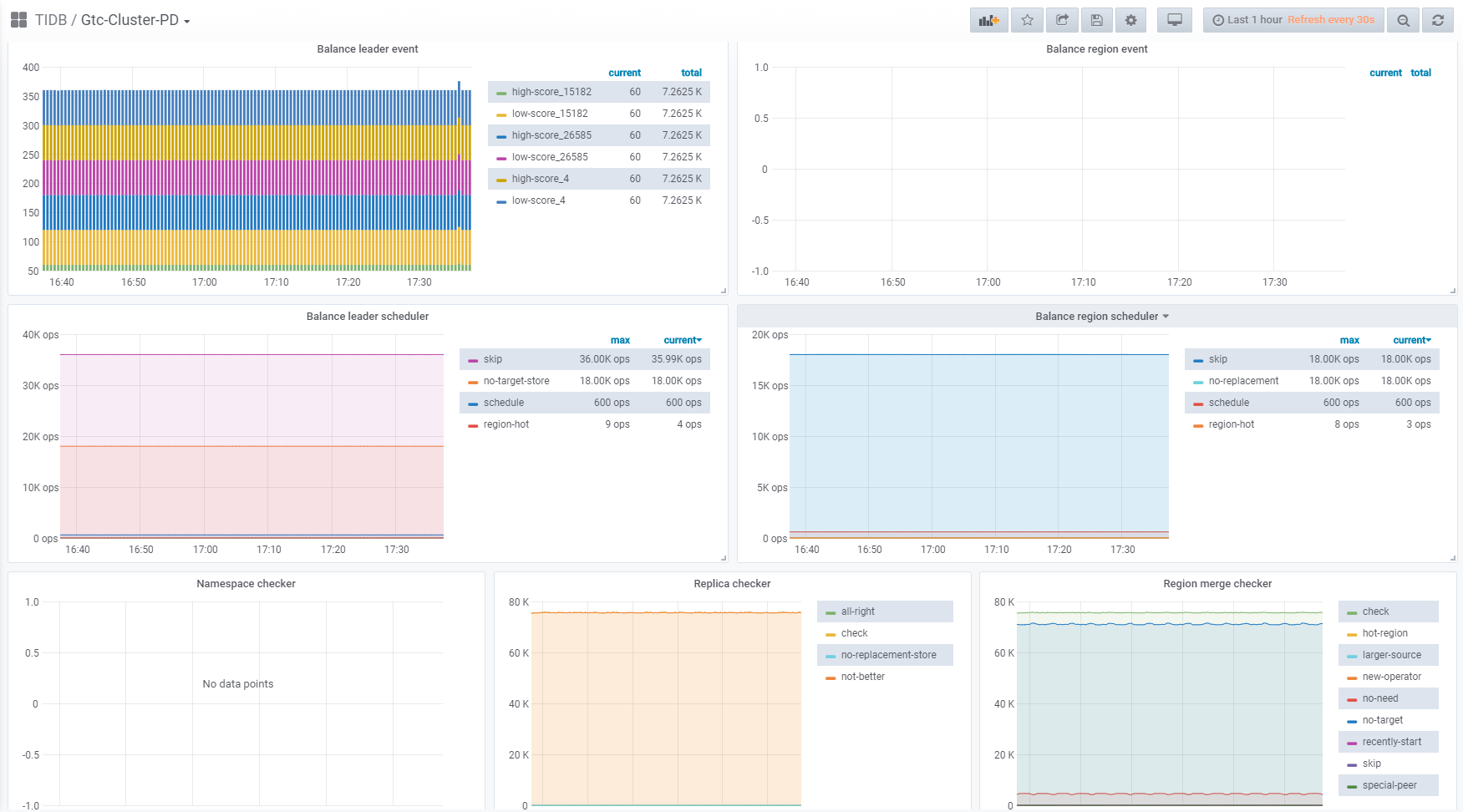
是的,感谢反馈,辛苦在看下 scheduler show 的信息
信息如下:
Starting component ctl: /home/tidb/.tiup/components/ctl/v4.0.2/ctl pd -u 10.xx.xx.33:2379 scheduler show
[
“balance-leader-scheduler”,
“balance-region-scheduler”,
“label-scheduler”,
“balance-hot-region-scheduler”
]
你好,
当前 “balance-region-scheduler”, 是正常调度的,store 信息中“used_size”: “3.596GiB”, 空间有 “region_count”: 4581,默认 region 大小为 96M 所以可能有空 region 存在,请上传下 Overview - PD - region health 的监控,判断下 empty region count 是否很多。并根据文档进行 merge 下。
是的 ,有空块 如图
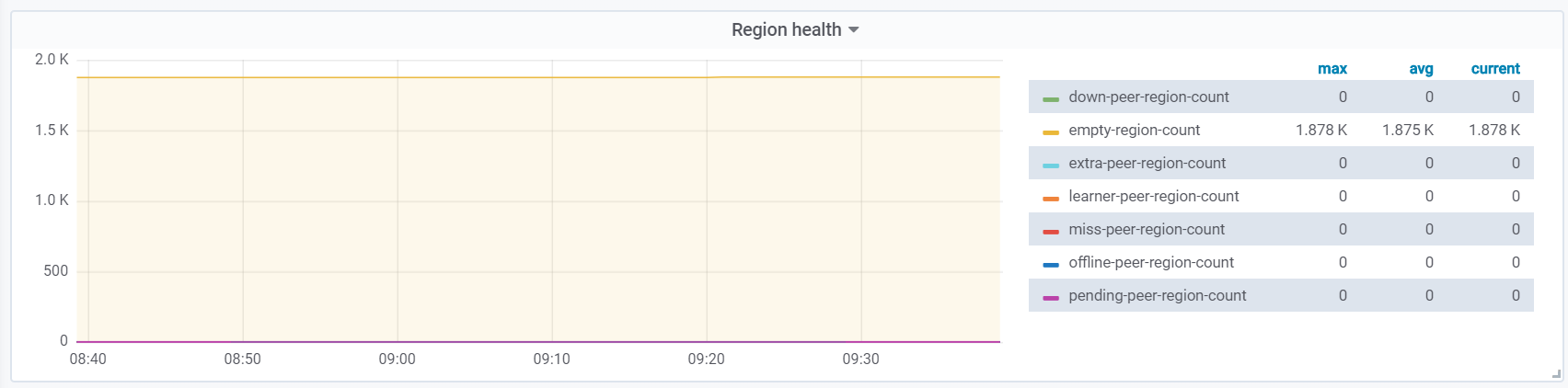
合并 region 是把以下3参数打开吗?我找到的文档可能不太适用, 能否给下相关链接?
当前merge的相关参数如下
[tidb@localhost config-cache]$ tiup ctl pd -u 10.xx.xx.33:2379 config show|grep merge
“enable-cross-table-merge”: “false”,
“enable-one-way-merge”: “false”,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“merge-schedule-limit”: 4,
“split-merge-interval”: “1h0m0s”,
还有怎么确认 region 的默认大小为 96M ?
tikv 配置文件中可以看下,如果没有设置,就是默认值,可以在 tikv.log 中搜索下这两个参数。

好的 谢谢 ,
我只把 enable-cross-table-merge 改成了 true 后 , region 已经在减少了 ,
split-region-on-table key-type 保持原值 ,
这三个参数是在释放 空region 后 改回原值 还是保持改后的值?
region merge 完成之后先观察下,可以反馈下当前的 cofnig show all 看下。目前不了解改了哪些参数
region merge 完成之后,已经没有空块了
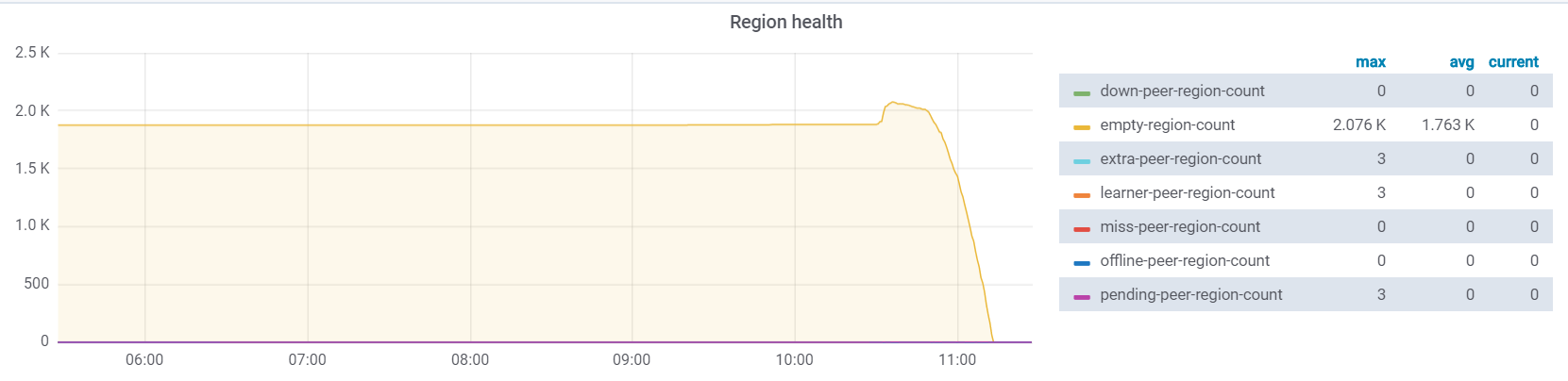
我只调整了 enable-cross-table-merge=true
config show all 输出如下:
Starting component ctl: /home/tidb/.tiup/components/ctl/v4.0.2/ctl pd -u 10.xx.xx.33:2379 config show all
{
“client-urls”: “http://0.0.0.0:2379”,
“peer-urls”: “http://10.xx.xx.34:2380”,
“advertise-client-urls”: “http://10.xx.xx.34:2379”,
“advertise-peer-urls”: “http://10.xx.xx.34:2380”,
“name”: “pd_10.xx.xx.34”,
“data-dir”: “/data/tidb/deploy/data.pd”,
“force-new-cluster”: false,
“enable-grpc-gateway”: true,
“initial-cluster”: “pd_10.xx.xx.33=http://10.xx.xx.33:2380,pd_10.xx.xx.34=http://10.xx.xx.34:2380,pd_10.xx.xx.35=http://10.xx.xx.35:2380”,
“initial-cluster-state”: “new”,
“join”: “”,
“lease”: 3,
“log”: {
“level”: “info”,
“format”: “text”,
“disable-timestamp”: false,
“file”: {
“filename”: “/data/tidb/deploy/log/pd.log”,
“max-size”: 300,
“max-days”: 0,
“max-backups”: 0
},
“development”: false,
“disable-caller”: false,
“disable-stacktrace”: false,
“disable-error-verbose”: true,
“sampling”: null
},
“tso-save-interval”: “3s”,
“metric”: {
“job”: “pd_10.xx.xx.34”,
“address”: “”,
“interval”: “15s”
},
“schedule”: {
“max-snapshot-count”: 3,
“max-pending-peer-count”: 16,
“max-merge-region-size”: 20,
“max-merge-region-keys”: 200000,
“split-merge-interval”: “1h0m0s”,
“enable-one-way-merge”: “false”,
“enable-cross-table-merge”: “true”,
“patrol-region-interval”: “100ms”,
“max-store-down-time”: “30m0s”,
“leader-schedule-limit”: 4,
“leader-schedule-policy”: “count”,
“region-schedule-limit”: 4,
“replica-schedule-limit”: 8,
“merge-schedule-limit”: 4,
“hot-region-schedule-limit”: 4,
“hot-region-cache-hits-threshold”: 3,
“store-limit”: {
“15182”: {
“add-peer”: 15,
“remove-peer”: 15
},
“26585”: {
“add-peer”: 15,
“remove-peer”: 15
},
“4”: {
“add-peer”: 15,
“remove-peer”: 15
}
},
“tolerant-size-ratio”: 5,
“low-space-ratio”: 0.8,
“high-space-ratio”: 0.6,
“scheduler-max-waiting-operator”: 3,
“enable-remove-down-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“enable-make-up-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-location-replacement”: “true”,
“enable-debug-metrics”: “false”,
“schedulers-v2”: [
{
“type”: “balance-region”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “balance-leader”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “hot-region”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “label”,
“args”: null,
“disable”: false,
“args-payload”: “”
},
{
“type”: “evict-leader”,
“args”: [
“4”
],
“disable”: false,
“args-payload”: “”
}
],
“schedulers-payload”: {
“balance-hot-region-scheduler”: “null”,
“balance-leader-scheduler”: “{"name":"balance-leader-scheduler","ranges":[{"start-key":"","end-key":""}]}”,
“balance-region-scheduler”: “{"name":"balance-region-scheduler","ranges":[{"start-key":"","end-key":""}]}”,
“label-scheduler”: “{"name":"label-scheduler","ranges":[{"start-key":"","end-key":""}]}”
},
“store-limit-mode”: “manual”
},
“replication”: {
“max-replicas”: 2,
“location-labels”: “”,
“strictly-match-label”: “false”,
“enable-placement-rules”: “false”
},
“pd-server”: {
“use-region-storage”: “true”,
“max-gap-reset-ts”: “24h0m0s”,
“key-type”: “table”,
“runtime-services”: “”,
“metric-storage”: “http://10.xx.xx.48:9090”,
“dashboard-address”: “http://10.xx.xx.35:2379”
},
“cluster-version”: “4.0.2”,
“quota-backend-bytes”: “8GiB”,
“auto-compaction-mode”: “periodic”,
“auto-compaction-retention-v2”: “1h”,
“TickInterval”: “500ms”,
“ElectionInterval”: “3s”,
“PreVote”: true,
“security”: {
“cacert-path”: “”,
“cert-path”: “”,
“key-path”: “”,
“cert-allowed-cn”: null
},
“label-property”: {},
“WarningMsgs”: [
“Config contains undefined item: namespace-classifier”
],
“DisableStrictReconfigCheck”: false,
“HeartbeatStreamBindInterval”: “1m0s”,
“LeaderPriorityCheckInterval”: “1m0s”,
“dashboard”: {
“tidb_cacert_path”: “”,
“tidb_cert_path”: “”,
“tidb_key_path”: “”,
“public_path_prefix”: “”,
“internal_proxy”: false,
“disable_telemetry”: false
},
“replication-mode”: {
“replication-mode”: “majority”,
“dr-auto-sync”: {
“label-key”: “”,
“primary”: “”,
“dr”: “”,
“primary-replicas”: 0,
“dr-replicas”: 0,
“wait-store-timeout”: “1m0s”,
“wait-sync-timeout”: “1m0s”
}
}
}
ok,可以先这样或者如果判断不会出现 drop table 和 drop database 的操作,可以将其置为默认值