为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:4.0.1
- 【问题描述】:cpu过高
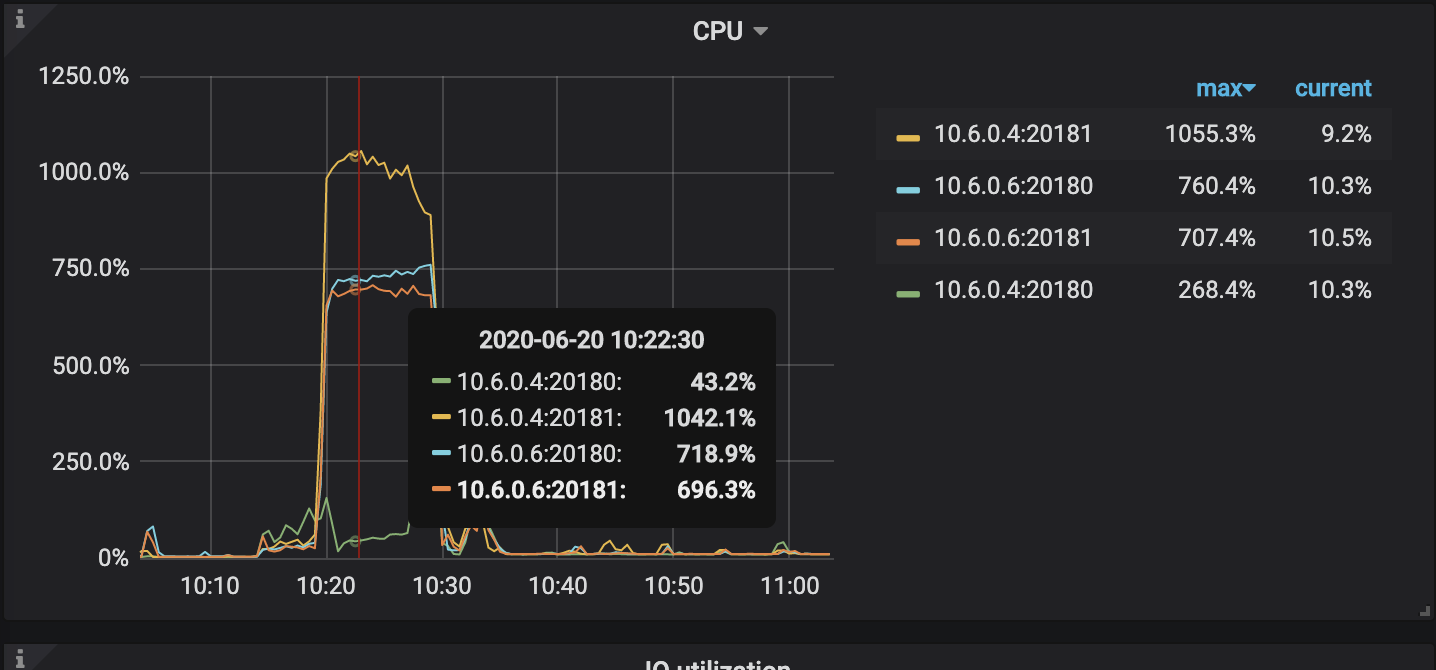
目前我们对4.0.1进行压测使用sysbench的oltp_insert脚本,出现了cpu负载过高的情况,请问这个可能是哪里引起的?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
目前我们对4.0.1进行压测使用sysbench的oltp_insert脚本,出现了cpu负载过高的情况,请问这个可能是哪里引起的?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
1、在高并发压测场景下 cpu 使用率高可能是预期内的现象,监控显示的是在压测时,tikv 节点 cpu 最高用了 10c 左右。
2、tidb 进行压测建议参考下述文档,并且建议替换 sysbench 默认的脚本为 tidb 修改好的 oltp_common.lua。
https://docs.pingcap.com/zh/tidb/v4.0/benchmark-tidb-using-sysbench#数据导入
3、在压测时,默认的表结构含有自增主键,建议根据实际诉求,使用 auto_random 或者如果使用 auto_increment,建议将 pk 改为 uk ,pk 使用 tidb 自动生成的 rowid,并配合 shard bit rowid 一起使用,来打散数据,减少热点发生的概率。
当前我们已经改了表结构使用的是uk+客户端uuid,在使用shard bit rowid之后性能反而会下降。
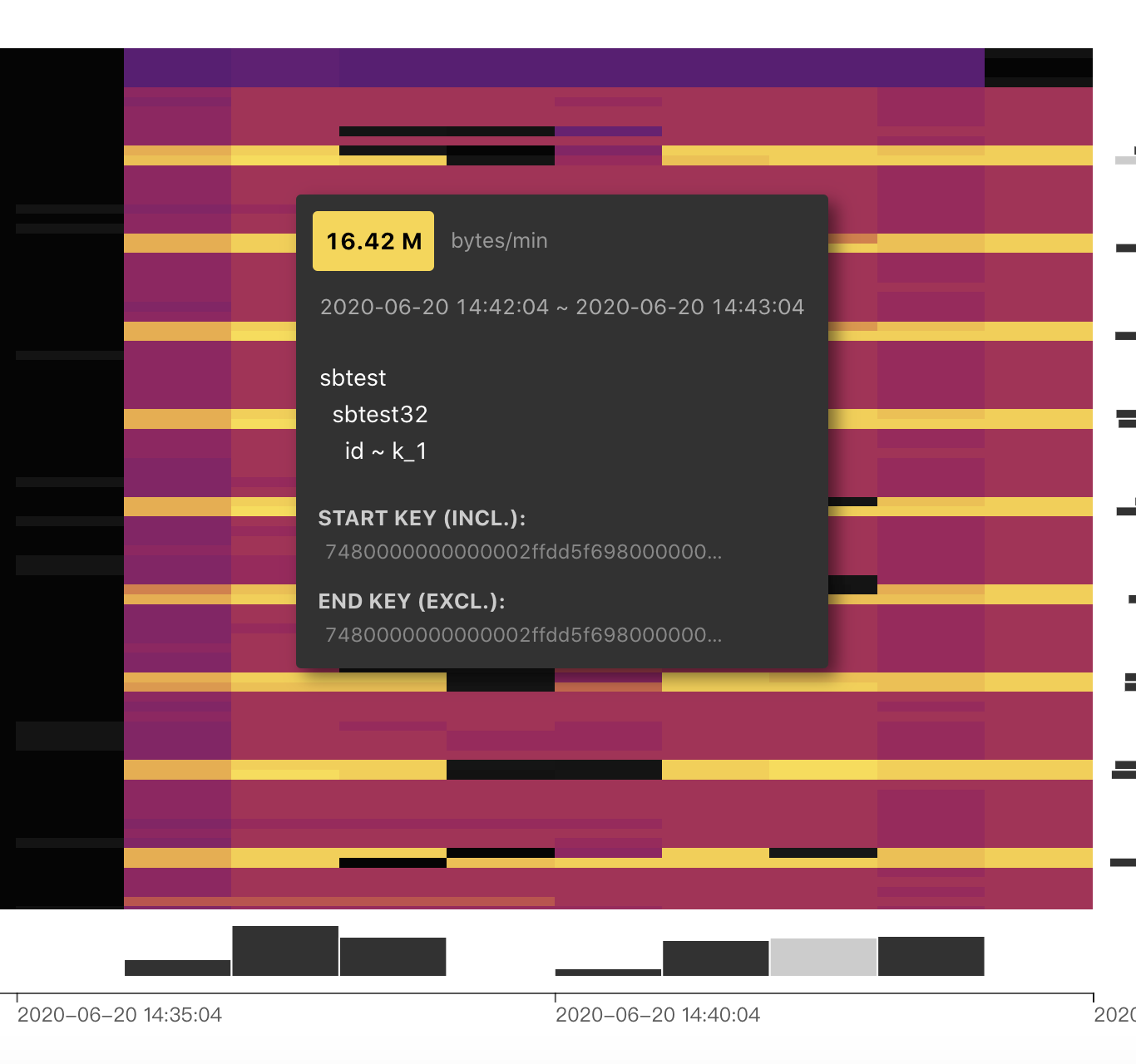
目前的热力图是这样的:
目前我们使用的是16c64g服务器,根据官方建议8c的配置我们一台服务器部署了两个kv。如果我们只部署一个是否会有改观?
1.是的。总共32个表脚本:
CREATE TABLE sbtest1 (
id varchar(45) NOT NULL,
k int(11) NOT NULL DEFAULT 0,
c char(120) NOT NULL DEFAULT ‘’,
pad char(60) NOT NULL DEFAULT ‘’,
create_time timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT ‘创建时间’,
update_time timestamp(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT ‘更新时间’,
UNIQUE KEY (id),
KEY k_1 (k)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin SHARD_ROW_ID_BITS=4 pre_split_regions=3;
2.据观察比较均衡
3.没有两个硬盘。但是据监控看,io并没有打满。
目前我们将集群拓扑改回来了。
TiDB Cluster: tidb-vm
TiDB Version: v4.0.1
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
10.6.8.10:9093 alertmanager 10.6.8.10 9093/9094 linux/x86_64 Up /data/tidb-data/alertmanager-9093 /data/tidb-deploy/alertmanager-9093
10.6.8.10:3000 grafana 10.6.8.10 3000 linux/x86_64 Up - /data/tidb-deploy/grafana-3000
10.6.0.15:2379 pd 10.6.0.15 2379/2380 linux/x86_64 Healthy|L /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
10.6.0.5:2379 pd 10.6.0.5 2379/2380 linux/x86_64 Healthy|UI /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
10.6.0.7:2379 pd 10.6.0.7 2379/2380 linux/x86_64 Healthy /data/tidb-data/pd-2379 /data/tidb-deploy/pd-2379
10.6.8.10:9090 prometheus 10.6.8.10 9090 linux/x86_64 Up /data/tidb-data/prometheus-9090 /data/tidb-deploy/prometheus-9090
10.6.8.12:4000 tidb 10.6.8.12 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
10.6.8.2:4000 tidb 10.6.8.2 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
10.6.8.4:4000 tidb 10.6.8.4 4000/10080 linux/x86_64 Up - /data/tidb-deploy/tidb-4000
10.6.0.4:20160 tikv 10.6.0.4 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160
10.6.0.6:20160 tikv 10.6.0.6 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160
10.6.8.16:20160 tikv 10.6.8.16 20160/20180 linux/x86_64 Up /data/tidb-data/tikv-20160 /data/tidb-deploy/tikv-20160
在更改之前,我们加了一台服务器,压测插入性能的时候能够去到2w6,但是改成单kv单机器之后,现在反而只能压到2w1左右了。性能反而有下降。
1.没开
2.开启之后会降低约1000左右
3.当前不适用2w左右
4.采用 NVNe SSD 的实例存储。目标3w
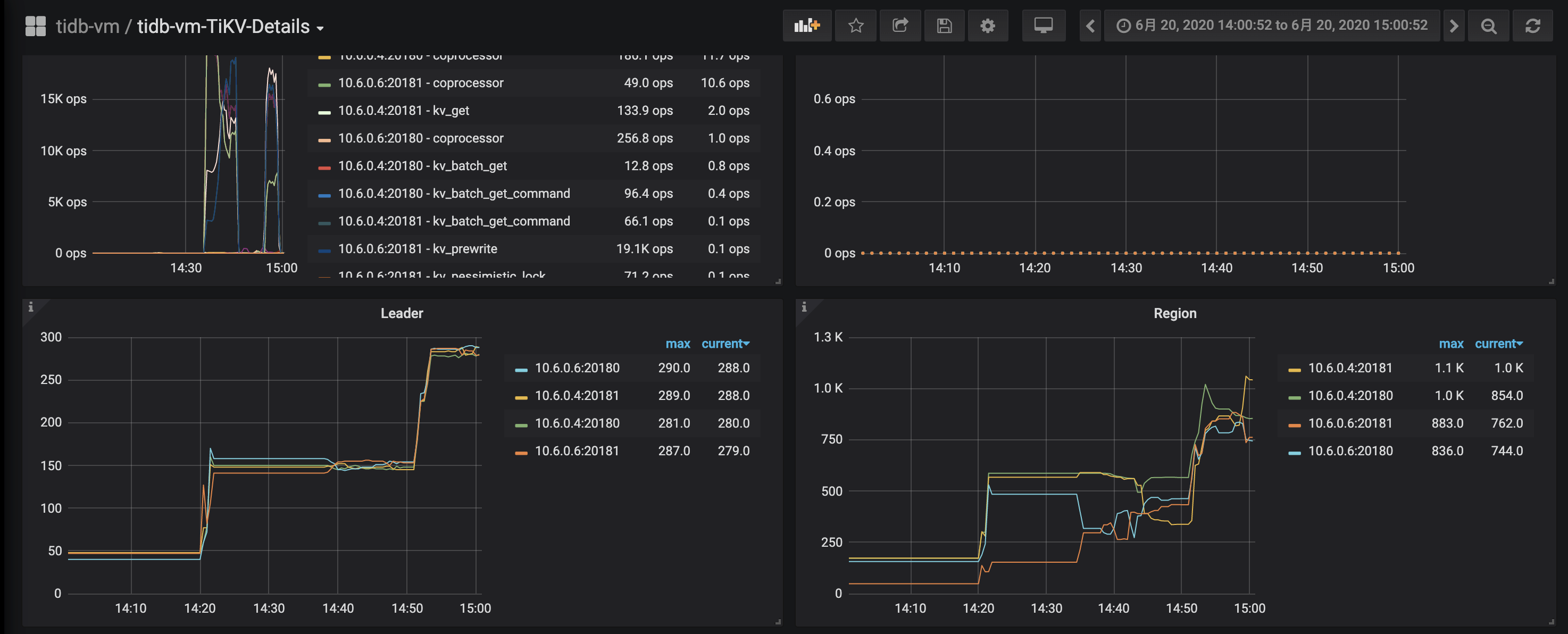
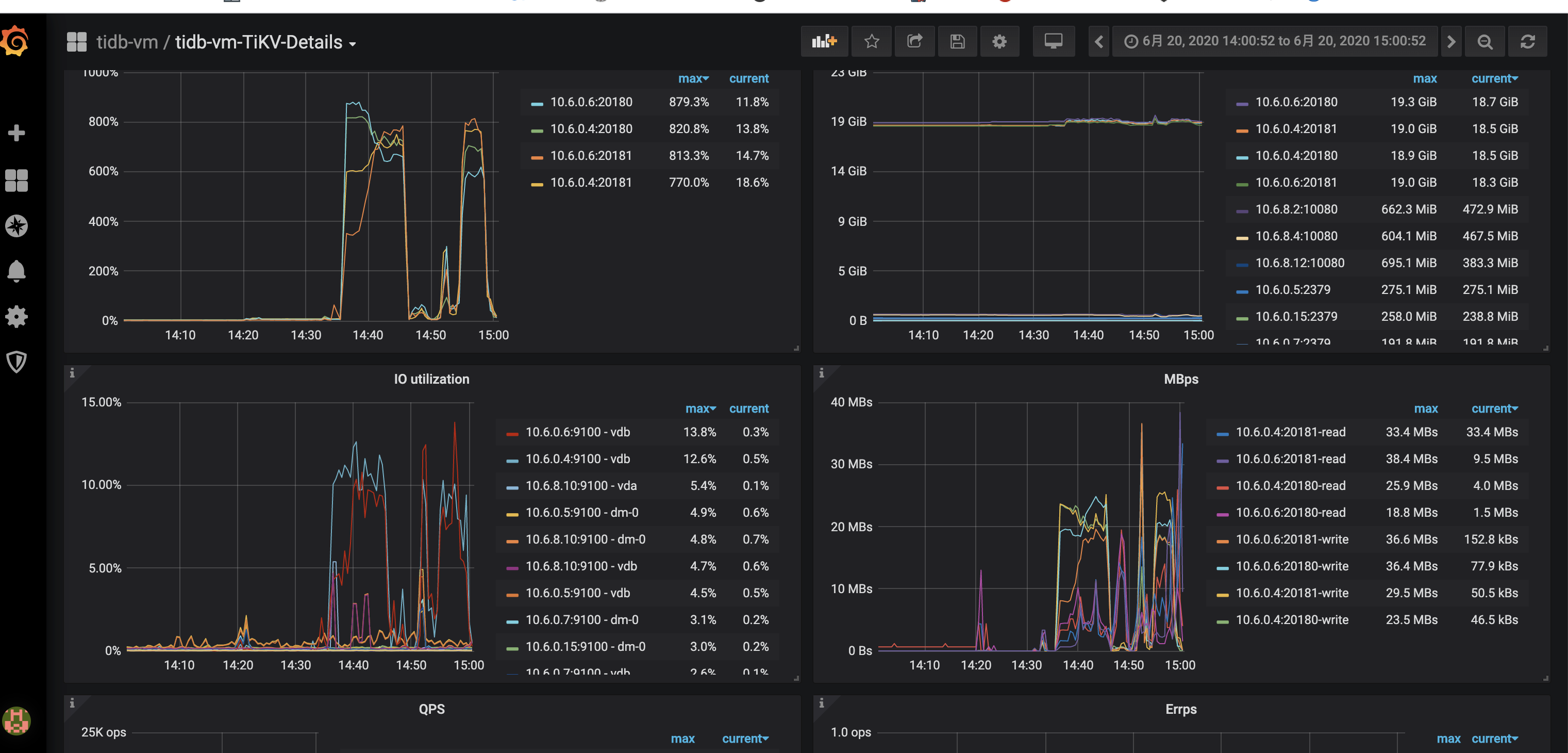
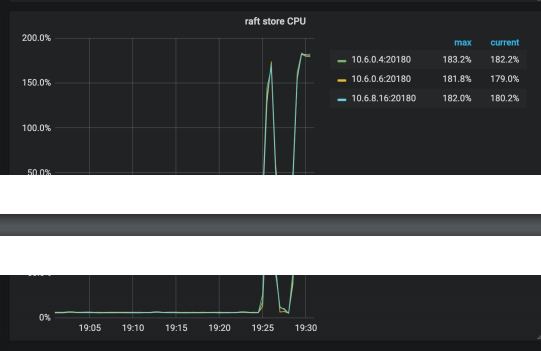
麻烦先发送over-view,tidb,detail-tikv监控看看,多谢。
导出监控为 pdf 的方式: 1)使用 chrome 浏览器,安装“Full Page Screen Capture”插件:https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
2)展开grafana 监控的 “cluster-name-overview” 的所有 dashboard (先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成)
3)使用插件导出 pdf
目前我取消了一些之前双kv的自定义参数,刚刚压测了一次,但是写并发也只能去到2w4。