为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】: V2.1.13
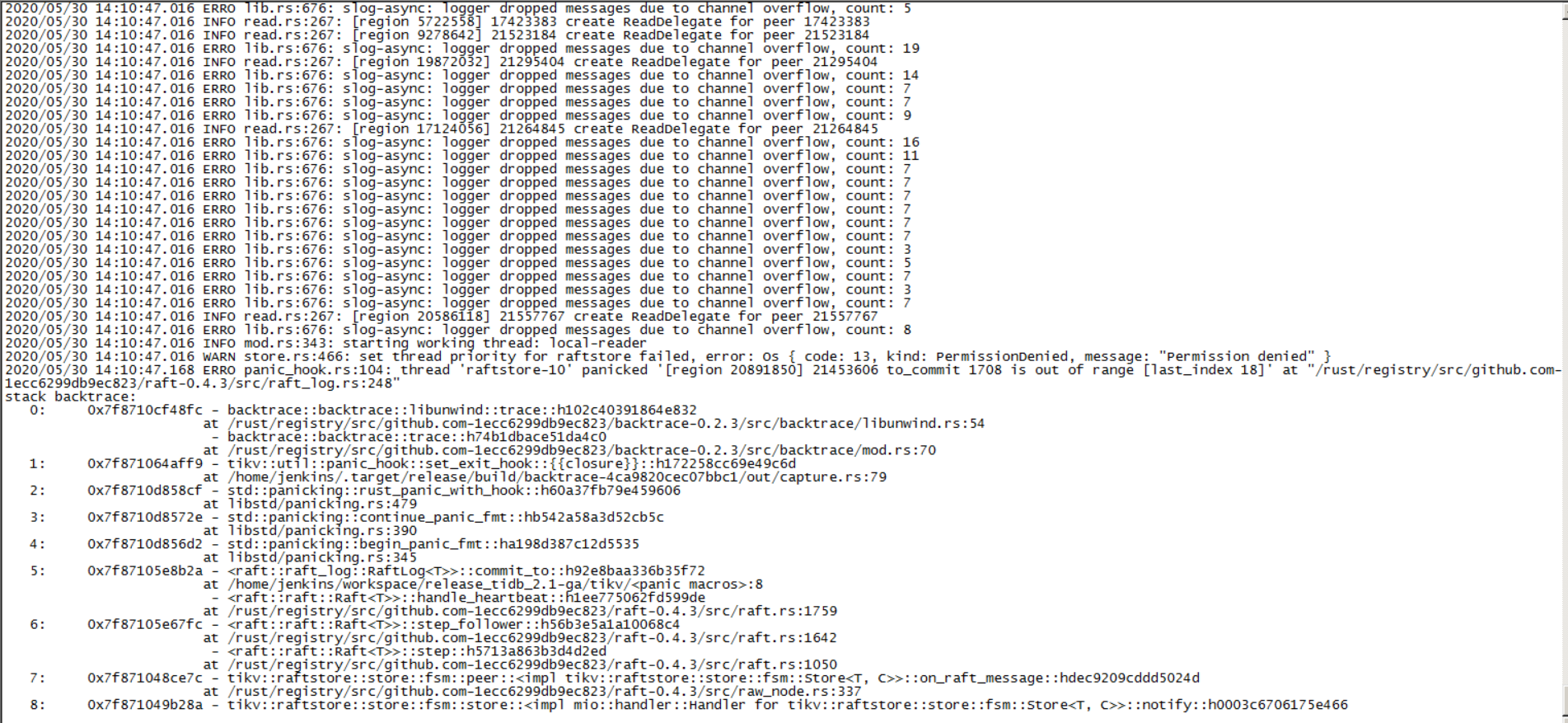
- 【问题描述】: tikv节点服务器磁盘损坏导致down掉,现在加了新的盘并把原有数据复制过来后启动tikv service一直在重启 若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
sync_log 设置为 false,机器掉电后可能导致启动时 panic,建议修改 sync_log 为 true
对于报错 commit index is out of range,可以通过如下步骤恢复
1.滚动重启所有可以正常启动的 TiKV
2.尝试启动这个 TiKV
如果仍有其他类似 last index,commit index 报错,则需要
1.把 Raft 状态机损坏的 Region 找出来
tikv-ctl --db /path/to/tikv-data/db bad-regions
2.把 Region 设置为 tombstone 状态
tikv-ctl --db /path/to/tikv-data/db tombstone -r --force
说明:上述命令在掉电故障的 TiKV 上执行,且TiKV 处于 stop 关闭状态
tikv-ctl 使用说明参考 https://pingcap.com/docs-cn/stable/tikv-control/
论坛也有类似问题修复案例
如果希望简单处理,可以放弃这个 TiKV 实例,按照正常的缩容流程下线,等状态变成 tombstone 后,再扩容进集群(2.1.13 版本扩容时可能需要指定与原 TiKV 实例不同的端口号如 20182)
集群的sync-log确认是为true的,我先按步骤解决试试
有问题,请跟帖继续反馈,多谢
执行tikv-ctl --db /path/to/tikv-data/db bad-regions后打印出的结果为“all regions are healthy”,然后我直接按照建议放弃这个TiKV节点,按照正常的缩容流程下线,状态变为offline后滚动更新了所有tikv节点,更新到该故障节点时提示在集群中不存在该节点,从pd查看状态已变成tombstone,再按照扩容流程扩容进集群,端口未做指定,现该节点tikv服务进程已正常,非常感谢各位PingCAP的老师热心快速的解答和帮助。
现在看日志和监控还有一些疑问:
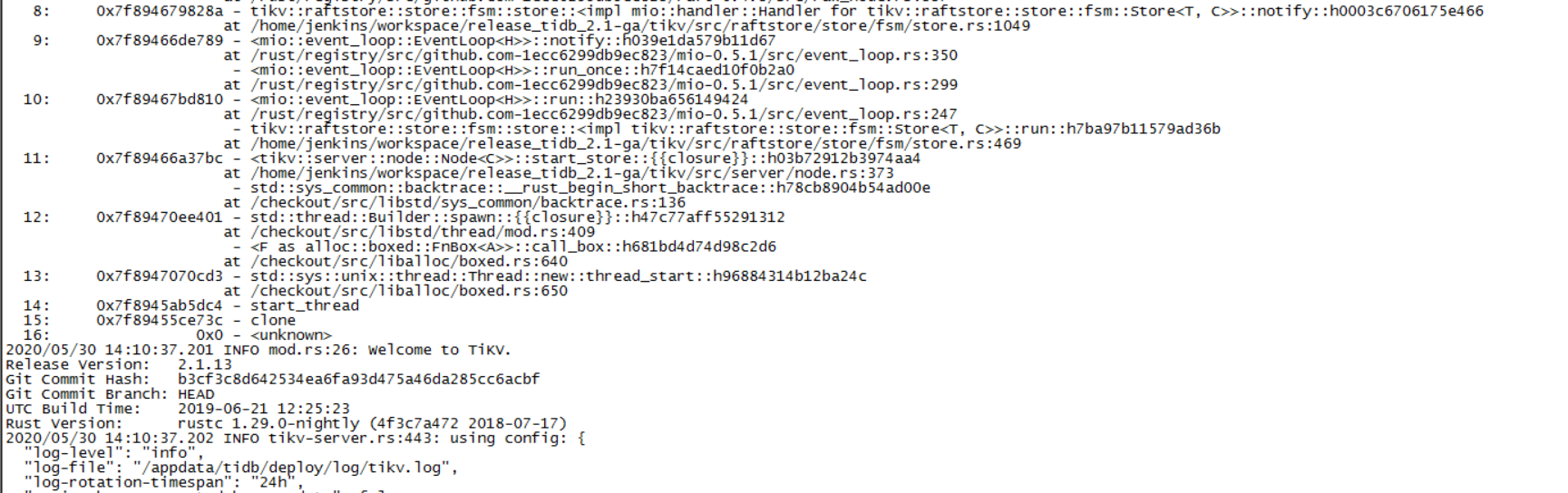
日志中当前未发现panic错误,有一些其他错误:
2020/06/01 12:13:09.265 ERRO process.rs:179: get snapshot failed for cid=33614060, error Request(message: “peer is not leader” not_leader {region_id: 7108792 leader {id: 21794209 store_id: 9}})
2020/06/01 12:14:07.063 ERRO process.rs:179: get snapshot failed for cid=33634689, error Request(message: “region is not found” region_not_found {region_id: 5742608})
2020/06/01 12:14:08.369 ERRO process.rs:179: get snapshot failed for cid=33638389, error Request(message: “region epoch is not match” epoch_not_match
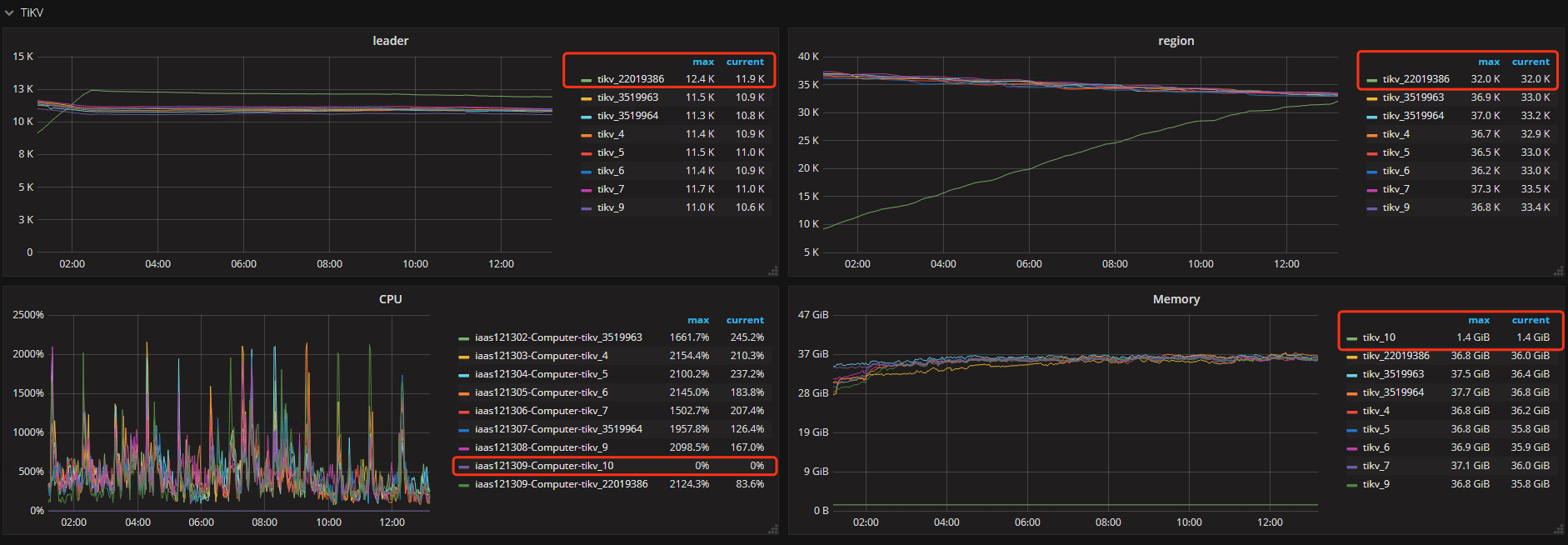
id为10的tikv节点状态已经为tombstone并且缩容再扩容后重新加入集群的id为22019386,但看监控页面部分面板还能看到两个id同时存在,如下图:
这两个问题是否影响该tikv节点正常服务?
参考帖子删除清理tombstone状态。如果可以,版本考虑升级一下吧。
还是404
抱歉,这个方式也是2.1.17 支持,您需要升级之后再使用,多谢。
好的,感谢。
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。