为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:TiDB 4.0-rc
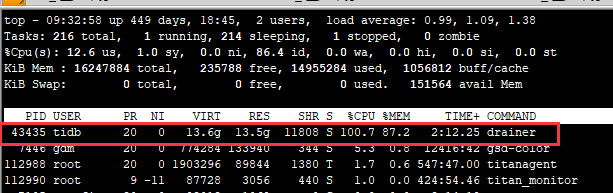
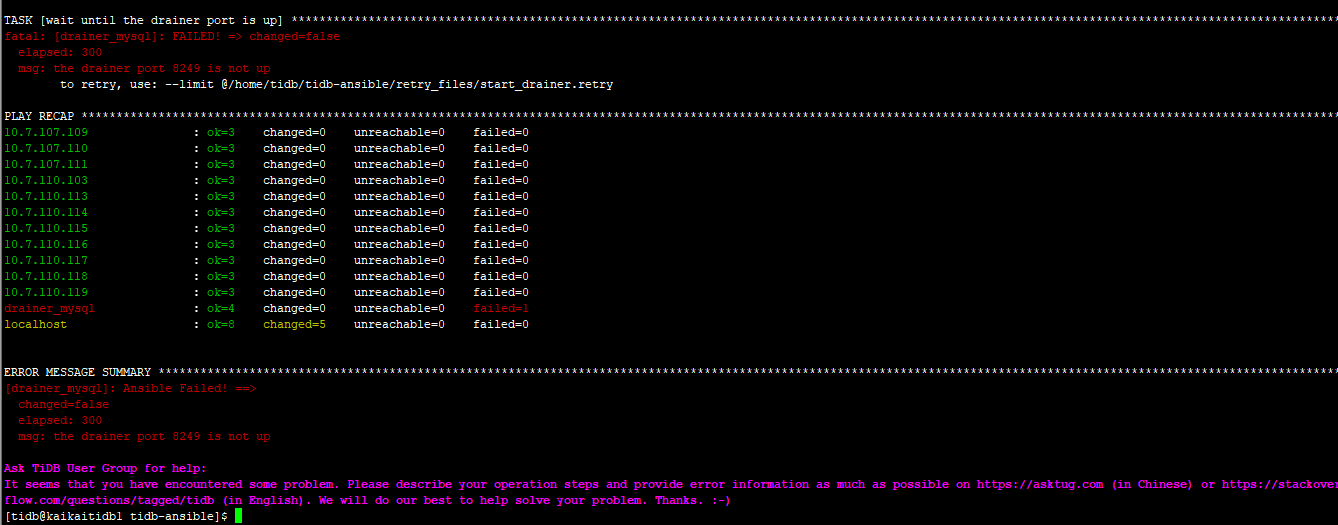
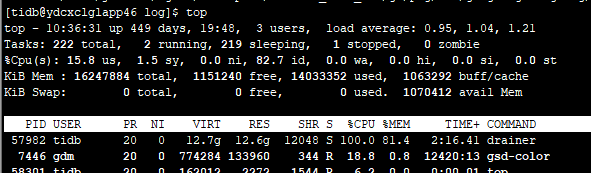
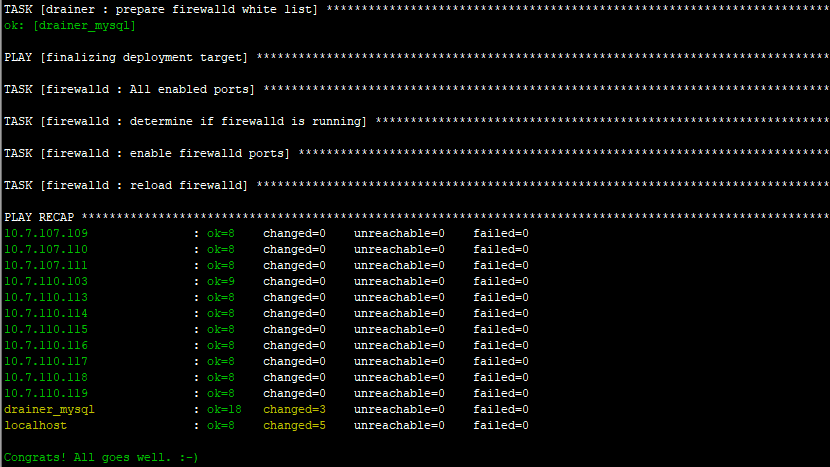
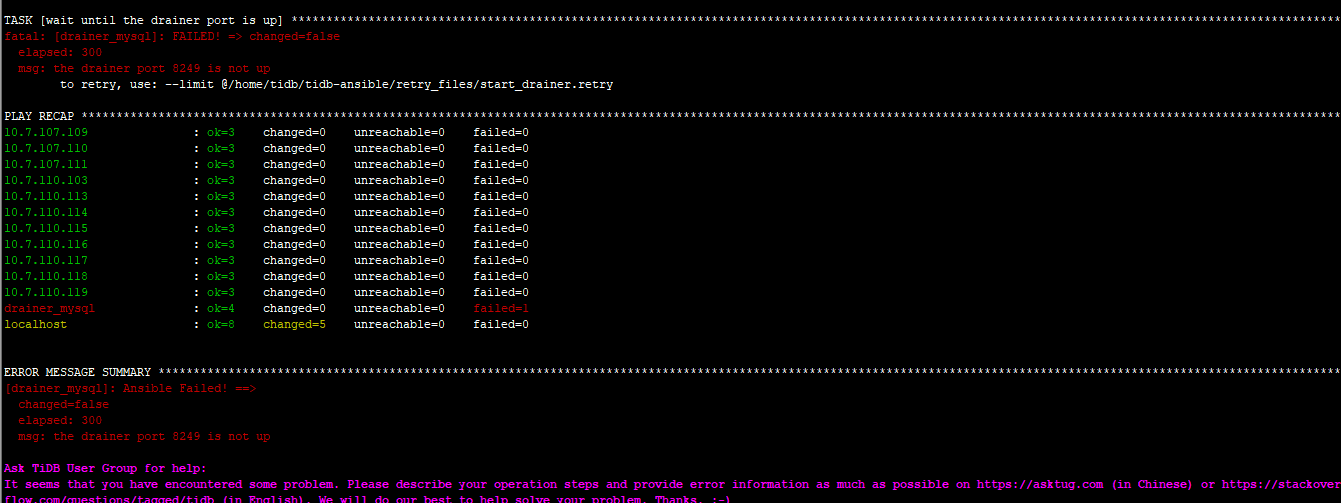
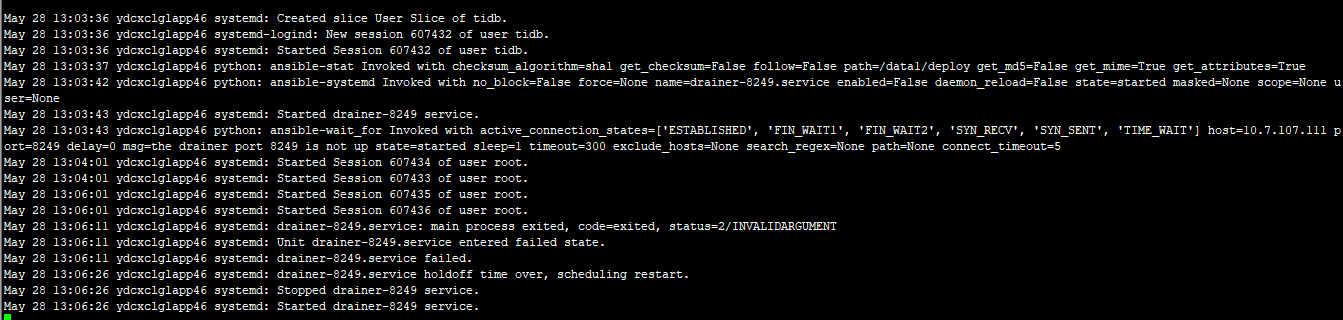
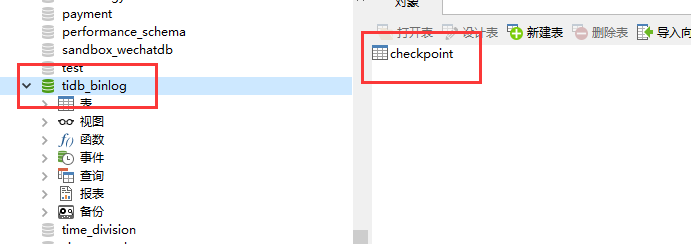
- 【问题描述】:Drainer启动失败,但在下游mysql当中,tidb_binlog的库和表都建上了,但里面没有数据。
下载mysql截图:
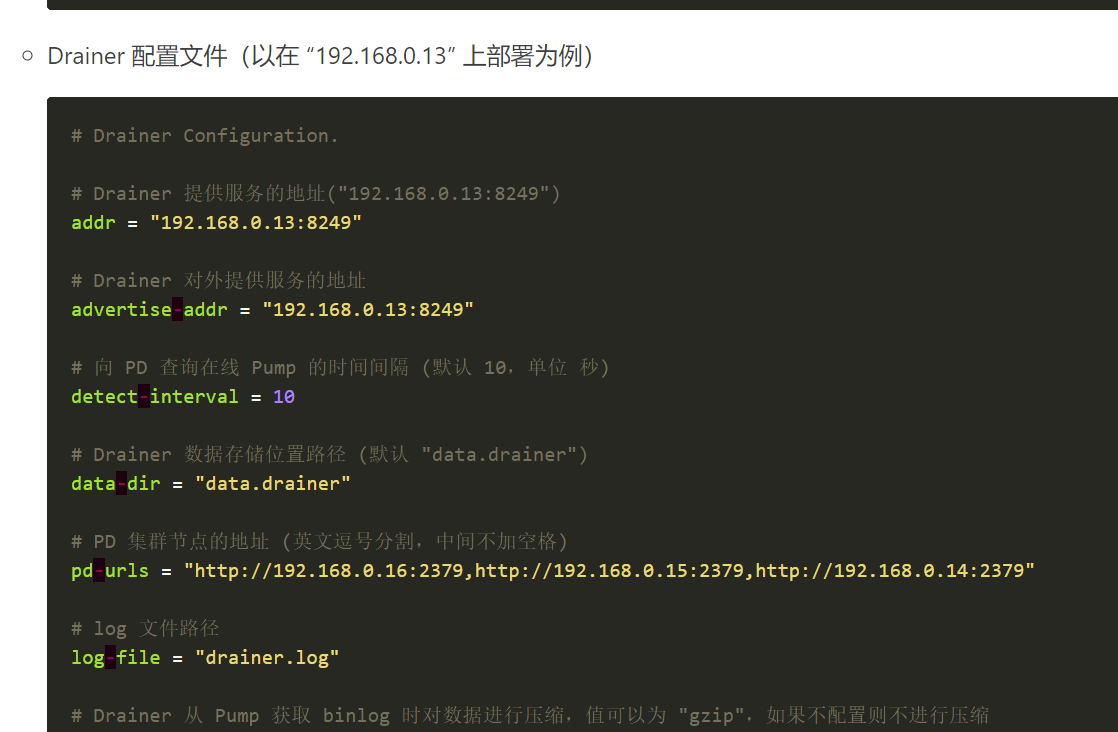
Drainer的配置文件:
drainer_mysql_drainer.toml (2.5 KB)
drainer启动时的日志:
[2020/05/27 16:45:39.793 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=1.667744642s]
[2020/05/27 16:45:56.994 +08:00] [INFO] [version.go:50] [“Welcome to Drainer”] [“Release Version”=v4.0.0-rc] [“Git Commit Hash”=b9af7839b97cfb26a71307a8b6334f2269b60a95] [“Build TS”=“2020-04-08 07:55:27”] [“Go Version”=go1.13] [“Go OS/Arch”=linux/amd64]
[2020/05/27 16:45:56.995 +08:00] [INFO] [main.go:46] [“start drainer…”] [config=“{"log-level":"info","node-id":"","addr":"http://10.7.107.111:8249","advertise-addr":"http://10.7.107.111:8249","data-dir":"/data1/deploy/data.drainer","detect-interval":10,"pd-urls":"http://10.7.110.114:2379,http://10.7.110.115:2379,http://10.7.110.116:2379","log-file":"/data1/deploy/log/drainer.log","initial-commit-ts":-1,"sycner":{"sql-mode":null,"ignore-txn-commit-ts":[],"ignore-schemas":"INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql","ignore-table":null,"txn-batch":20,"loopback-control":false,"sync-ddl":true,"channel-id":0,"worker-count":16,"to":{"host":"10.7.110.120","user":"hqzc_online","password":"hqzc_online@com!","security":{"ssl-ca":"","ssl-cert":"","ssl-key":"","cert-allowed-cn":null},"encrypted_password":"","sync-mode":0,"port":3306,"checkpoint":{"type":"","schema":"","host":"","user":"","password":"","encrypted_password":"","port":0},"dir":"","retention-time":0,"zookeeper-addrs":"","kafka-addrs":"","kafka-version":"","kafka-max-messages":0,"kafka-client-id":"","topic-name":""},"replicate-do-table":null,"replicate-do-db":["cw"],"db-type":"mysql","relay":{"log-dir":"","max-file-size":10485760},"disable-dispatch-flag":null,"enable-dispatch-flag":null,"disable-dispatch":false,"enable-dispatch":null,"safe-mode":false,"disable-detect-flag":null,"enable-detect-flag":null,"disable-detect":null,"enable-detect":null},"security":{"ssl-ca":"","ssl-cert":"","ssl-key":"","cert-allowed-cn":null},"synced-check-time":5,"compressor":"","EtcdTimeout":5000000000,"MetricsAddr":"","MetricsInterval":15}”]
[2020/05/27 16:45:56.995 +08:00] [INFO] [client.go:135] [“[pd] create pd client with endpoints”] [pd-address=“[http://10.7.110.114:2379,http://10.7.110.115:2379,http://10.7.110.116:2379]”]
[2020/05/27 16:45:56.998 +08:00] [INFO] [base_client.go:242] [“[pd] switch leader”] [new-leader=http://10.7.110.116:2379] [old-leader=]
[2020/05/27 16:45:56.999 +08:00] [INFO] [base_client.go:92] [“[pd] init cluster id”] [cluster-id=6812808469366657611]
[2020/05/27 16:45:56.999 +08:00] [INFO] [server.go:119] [“get cluster id from pd”] [id=6812808469366657611]
[2020/05/27 16:45:57.000 +08:00] [INFO] [server.go:128] [“set InitialCommitTS”] [ts=416958161088151553]
[2020/05/27 16:45:57.003 +08:00] [INFO] [checkpoint.go:64] [“initialize checkpoint”] [type=mysql] [checkpoint=416958161088151553] [cfg=“{"CheckpointType":"mysql","Db":{"host":"10.7.110.120","user":"hqzc_online","password":"hqzc_online@com!","port":3306},"Schema":"tidb_binlog","Table":"checkpoint","ClusterID":6812808469366657611,"InitialCommitTS":416958161088151553,"dir":"/data1/deploy/data.drainer/savepoint"}”]
[2020/05/27 16:45:57.003 +08:00] [INFO] [store.go:68] [“new store”] [path=“tikv://10.7.110.114:2379,10.7.110.115:2379,10.7.110.116:2379?disableGC=true”]
[2020/05/27 16:45:57.004 +08:00] [INFO] [client.go:135] [“[pd] create pd client with endpoints”] [pd-address=“[10.7.110.114:2379,10.7.110.115:2379,10.7.110.116:2379]”]
[2020/05/27 16:45:57.007 +08:00] [INFO] [base_client.go:242] [“[pd] switch leader”] [new-leader=http://10.7.110.116:2379] [old-leader=]
[2020/05/27 16:45:57.007 +08:00] [INFO] [base_client.go:92] [“[pd] init cluster id”] [cluster-id=6812808469366657611]
[2020/05/27 16:45:57.009 +08:00] [INFO] [store.go:74] [“new store with retry success”]
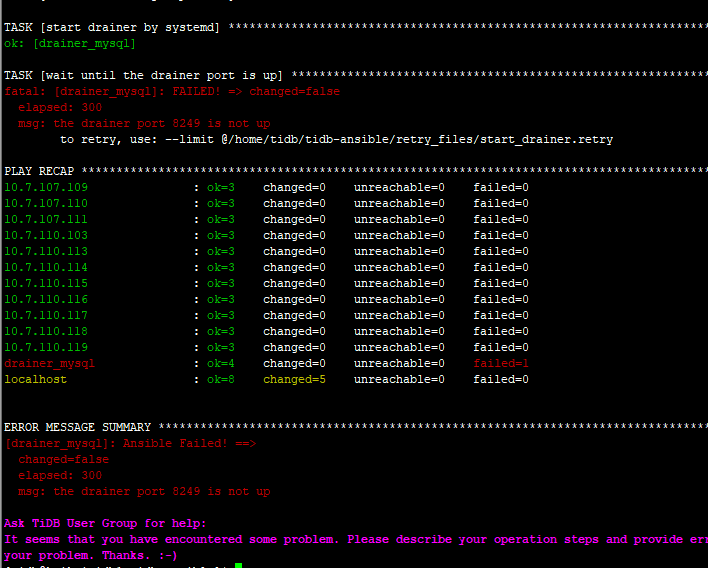
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。