重新启动后,一直观察内存的使用情况,可以发现,内存一直在增长当中,当涨到95%后,就被停止了。
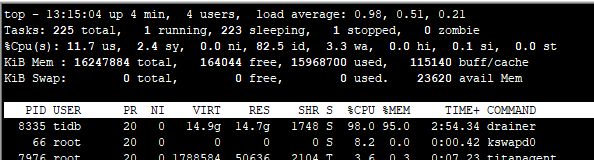
在启动时,会向下游mysql库中建立checkpont表,但里面的数据是空的。是不是可以判断出drainer在启动时,已经运行到哪一步了,但由于读取pump的某些信息,导致内存溢出了。
目前TiDB当中的库非常多,表就更多了,和这个有没有关系?
虽然有这些库和表,但在drainer配置文件当中,已经配置了 replicate-do-db这个,只同步一个库的数据,这个库现在还是个只有一个表的库(为了测试使用,尽量简化部署问题)
暂时能想到的就这些了,还有就是需要看看,是不是TiDB4.0-rc中,使用ansible部署drainer是否有什么问题了
在 drainer 日志中发现一些 error,例如
[2020/05/28 08:56:35.826 +08:00] [ERROR] [kv.go:275] [“fail to load safepoint from pd”] [error=“context deadline exceeded”] [errorVerbose=“context deadline exceeded\ngithub.com/pingcap/errors.AddStack\ \t/home/jenkins/a gent/workspace/release_tidb_4.0/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/errors.go:174\ngithub.com/pingcap/errors.Trace\ \t/home/jenkins/agent/workspace/release_tidb_4.0/go/pkg/mod/gith ub.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/juju_adaptor.go:15\ github.com/pingcap/tidb/store/tikv.(*EtcdSafePointKV).Get\ \t/home/jenkins/agent/workspace/release_tidb_4.0/go/pkg/mod/github.com/pingcap/t idb@v1.1.0-beta.0.20200312095702-bbcc42ff81bc/store/tikv/safepoint.go:124\ngithub.com/pingcap/tidb/store/tikv.loadSafePoint\ \t/home/jenkins/agent/workspace/release_tidb_4.0/go/pkg/mod/github.com/pingcap/tidb@v1.1.0-bet a.0.20200312095702-bbcc42ff81bc/store/tikv/safepoint.go:154\ngithub.com/pingcap/tidb/store/tikv.(*tikvStore).runSafePointChecker\ \t/home/jenkins/agent/workspace/release_tidb_4.0/go/pkg/mod/github.com/pingcap/tidb@v1.1. 0-beta.0.20200312095702-bbcc42ff81bc/store/tikv/kv.go:268\ runtime.goexit\ \t/usr/local/go/src/runtime/asm_amd64.s:1357”]
[2020/05/28 08:05:37.556 +08:00] [ERROR] [client.go:174] [“tso request is canceled due to timeout”] [2020/05/28 08:56:44.623 +08:00] [WARN] [pd.go:109] [“get timestamp too slow”] [“cost time”=3.020452521s]
先检查一下 PD 是否有异常吧
你好,PD异常怎么查看?有方法么?
看pd 的日志一直在报错,这个集群是测试集群吗? 可以尝试 ansible 完整 stop 集群,再重新start 吗?
这个是生产集群,先和用户申请一下啊。
还有其他的办法么?
- 先检查这些端口都放通了吗?是否都关闭了防火墙
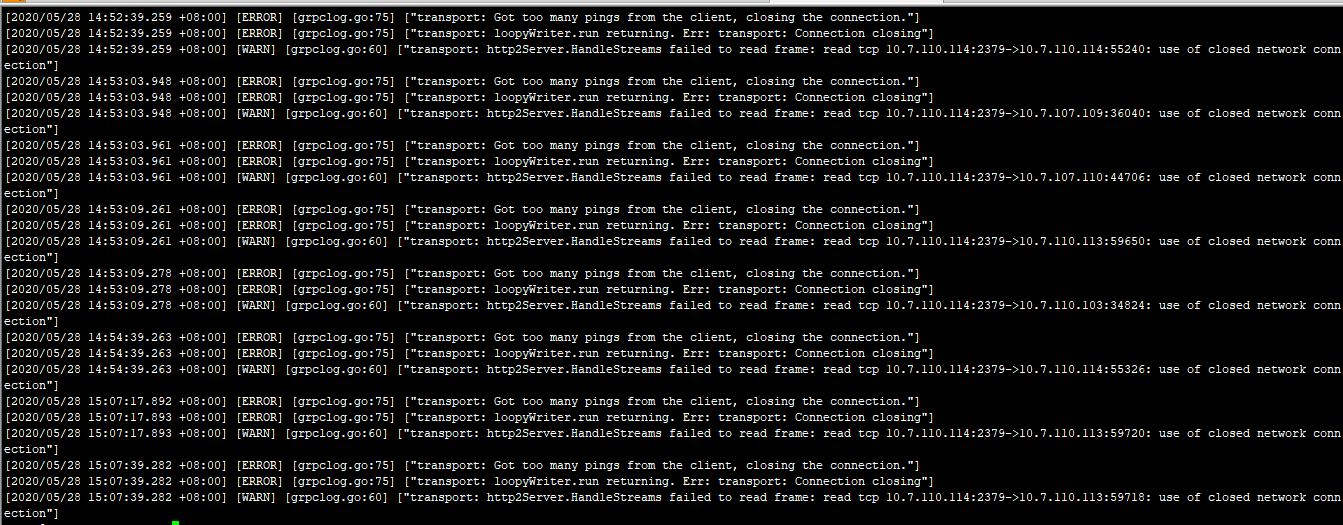
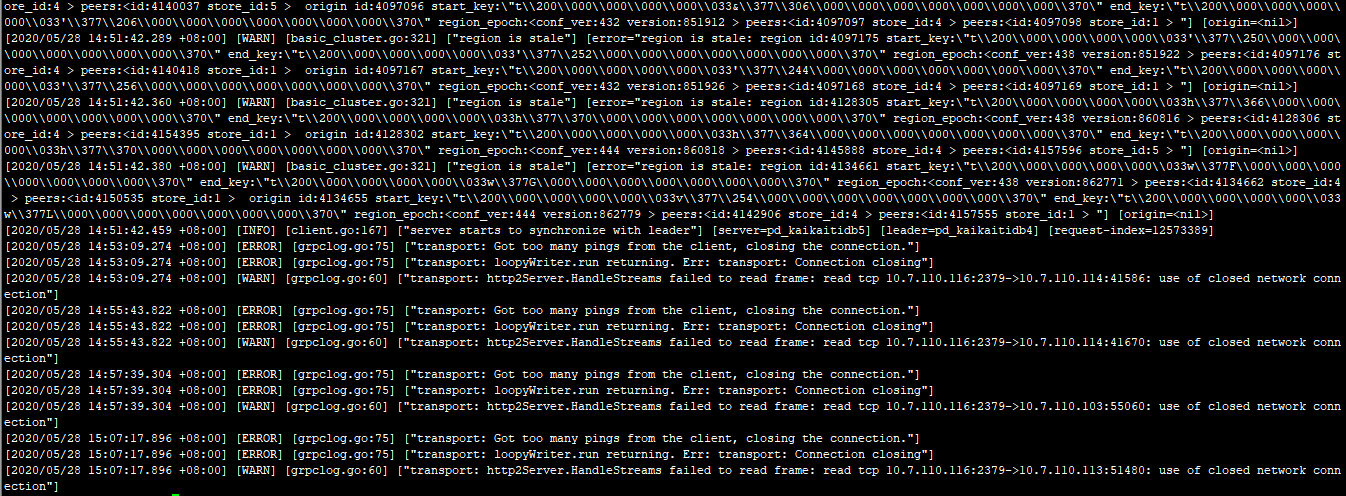
[2020/05/28 13:54:34.502 +08:00] [ERROR] [grpclog.go:75] [“transport: Got too many pings from the client, closing the connection.”] [2020/05/28 13:54:34.502 +08:00] [ERROR] [grpclog.go:75] [“transport: loopyWriter.run returning. Err: transport: Connection closing”] [2020/05/28 13:54:34.502 +08:00] [WARN] [grpclog.go:60] [“transport: http2Server.HandleStreams failed to read frame: read tcp 10.7.110.114:2379->10.7.107.111:36942: use of closed network connection”]
- 使用 pd-ctl命令 执行 下 health , store ,member 命令,多谢。

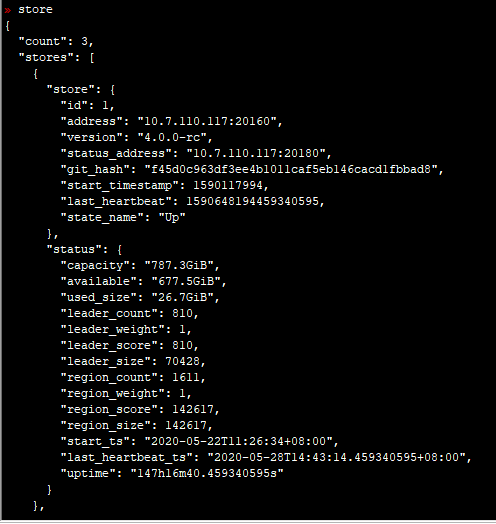
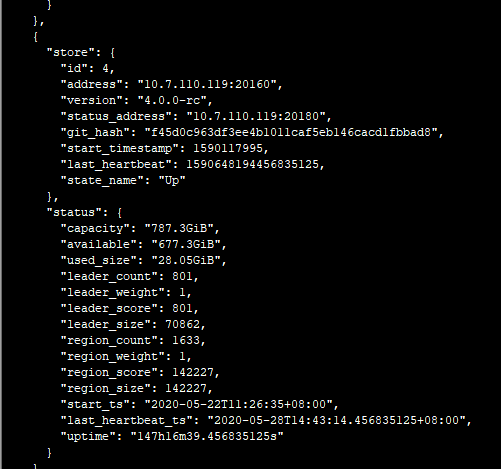
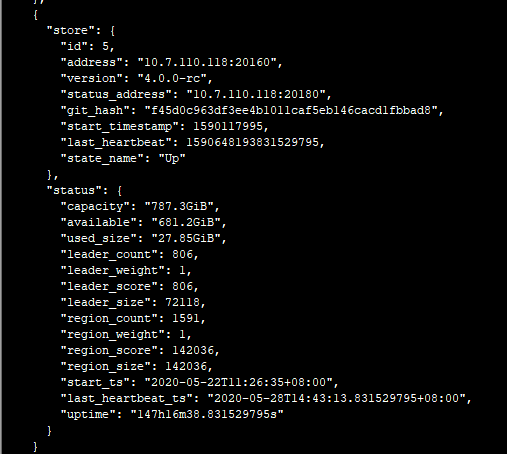
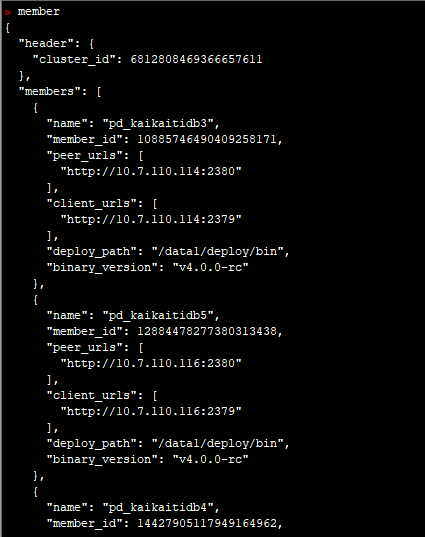
麻烦帮忙确认下, pd 到 drainer , drainer 到 pd 的网络是通的吗?是否不同机架,中间交换机或者防火墙有配置策略, 是否有端口未放通,多谢。 可以先互相测试 ping ,telnet 命令是否通,多谢。
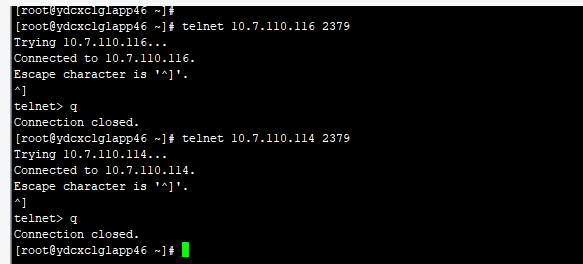
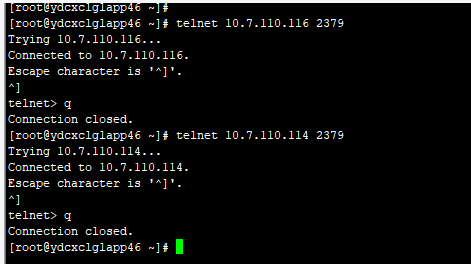
pd到drainer,只能看ping,这个是通的。因为drainer没有启动,所以没有端口可telnet
drainer到pd,通过下截图可以看到drainer到pd的2379是通的。
他们之间交换机和防火墙,是没有什么的,都在一个机房里面,做的虚拟机。
还有什么其他信息需要提供么?
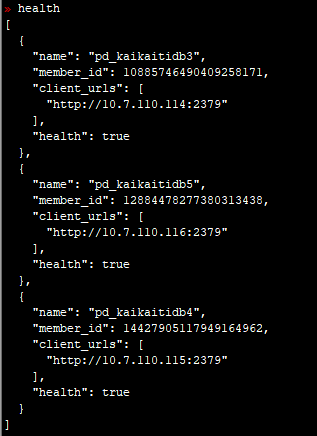
感觉pd里面也不一定有错,因为pd的leader节点是没有异常日志的。
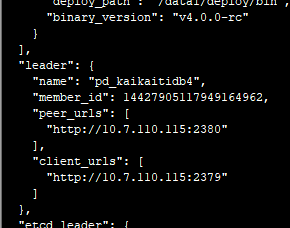
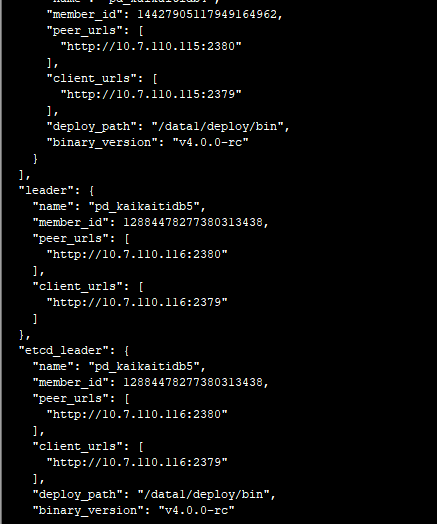
从这里知道10.7.110.115是leader节点
pd的10.7.110.114从节点的pd.log日志:
pd的10.7.110.115主节点的pd.log日志:
pd的10.7.110.116从节点的pd.log日志:
除了库多表多外,就是dm当中的task也非常多,都是同时实步的task,大约有200多个吧。
其中dm常用连接数就需要保持将近3000个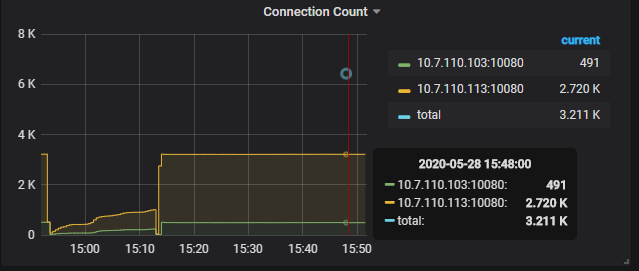
麻烦重启一次drianer,记录下时间,上传最新的drainer 日志和 pd 日志,tidb 日志,多谢。
好的,现在操作
重新启动了drainer,之后将pd的leader日志,还有两个tidb日志,还有drainer里面的日志,都拿出来了。
drainer_stderr.log (2.7 MB)
drainer_stderr.log (4.1 MB) tidb_113.log (22.5 KB) tidb_103.log (37.5 KB) drainer.log (7.5 KB)
感觉就是内存溢出了,可以向这方面考虑。怎么能找出来溢出的原因。
pd 的日志 和 pump 的日志,麻烦也上传下,多谢。