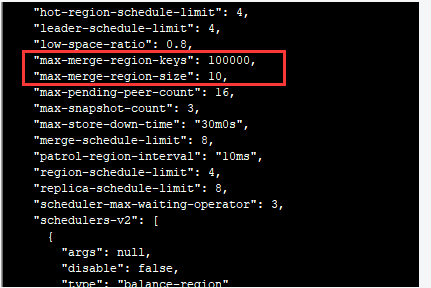
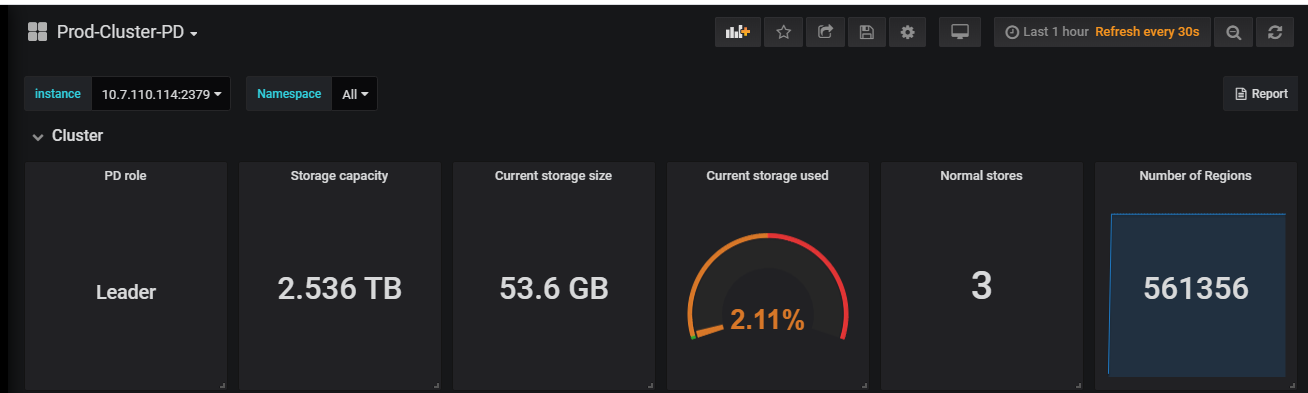
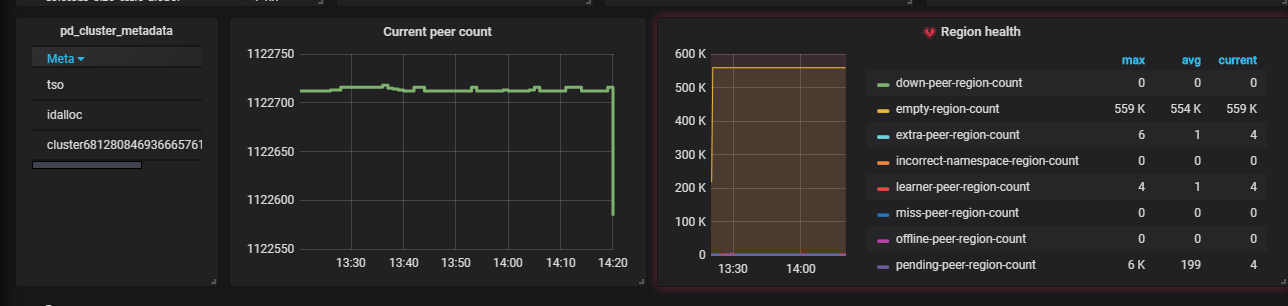
[tidb@kaikaitidb1 bin]$ ./pd-ctl -u http://10.7.110.114:2379 store
{
“count”: 3,
“stores”: [
{
“store”: {
“id”: 1,
“address”: “10.7.110.117:20160”,
“version”: “3.0.5”,
“state_name”: “Up”
},
“status”: {
“capacity”: “787.3GiB”,
“available”: “708.1GiB”,
“leader_count”: 359166,
“leader_weight”: 1,
“leader_score”: 441621,
“leader_size”: 441621,
“region_count”: 375090,
“region_weight”: 1,
“region_score”: 461278,
“region_size”: 461278,
“start_ts”: “2020-05-13T08:59:19+08:00”,
“last_heartbeat_ts”: “2020-05-13T09:17:05.366187782+08:00”,
“uptime”: “17m46.366187782s”
}
},
{
“store”: {
“id”: 4,
“address”: “10.7.110.119:20160”,
“version”: “3.0.5”,
“state_name”: “Up”
},
“status”: {
“capacity”: “787.3GiB”,
“available”: “710.4GiB”,
“leader_count”: 11861,
“leader_weight”: 1,
“leader_score”: 14020,
“leader_size”: 14020,
“region_count”: 377530,
“region_weight”: 1,
“region_score”: 458212,
“region_size”: 458212,
“receiving_snap_count”: 1,
“start_ts”: “2020-05-13T09:14:59+08:00”,
“last_heartbeat_ts”: “2020-05-13T09:17:02.357081996+08:00”,
“uptime”: “2m3.357081996s”
}
},
{
“store”: {
“id”: 5,
“address”: “10.7.110.118:20160”,
“version”: “3.0.5”,
“state_name”: “Up”
},
“status”: {
“capacity”: “787.3GiB”,
“available”: “713.6GiB”,
“leader_count”: 190350,
“leader_weight”: 1,
“leader_score”: 234804,
“leader_size”: 234804,
“region_count”: 370138,
“region_weight”: 1,
“region_score”: 461404,
“region_size”: 461404,
“start_ts”: “2020-05-13T09:06:04+08:00”,
“last_heartbeat_ts”: “2020-05-13T09:16:57.427564841+08:00”,
“uptime”: “10m53.427564841s”
}
}
]
}