1、io util 使用率上升和业务写入的特性有一定的正相关性,从上面的 DM 的配置,以及磁盘的使用带宽看到用量是比较大的在 140+M,并且存在使用量突然增长的情况,这个可以通过 DM 同步的 binlog 数量来确认下。
2、上面提到的 2.1 不会这样,但是 4.0 rc 会这样,请问下是在同样的 DM 7 个 task 并且相同 thread 的配置以及业务压力下,表现不一样吗?
3、从 3.0 开始 tidb 对写入进行了相关优化,比如,将 raftstore 和 apply 进行分拆
综上,建议先调小 task 的 syncer 的同步线程后,再观察下。
gzp1
(g)
24
1.以我们源头数据库的修改,大约 1 小时产生 1GB 的 binlog,就算复制成三份全落到一个 tikv,也只是 3GB,也就是一个 TiKV 一小时以内只有不到 10GB 的 IO,相当小的.
10GB / 3600s,每秒平均在 3MB 的写入.
从 iotop 看,io 最高的是 raftstore。可能 raft 协议那里实现有点啥问题,或者默认配置不合适——按说我们的数据量不大,raft 那里默认配置可以的
2 2.1的同步任务还要多一些,写入压力也比新集群大。
3 调小task的syncer 同步进程,会导致,task在binlog新增量较大的情况下,task任务延迟。体现就是binlog file gap between relay and syncer 值会大于3,业务实时查询,不能忍受。
gzp1
(g)
25
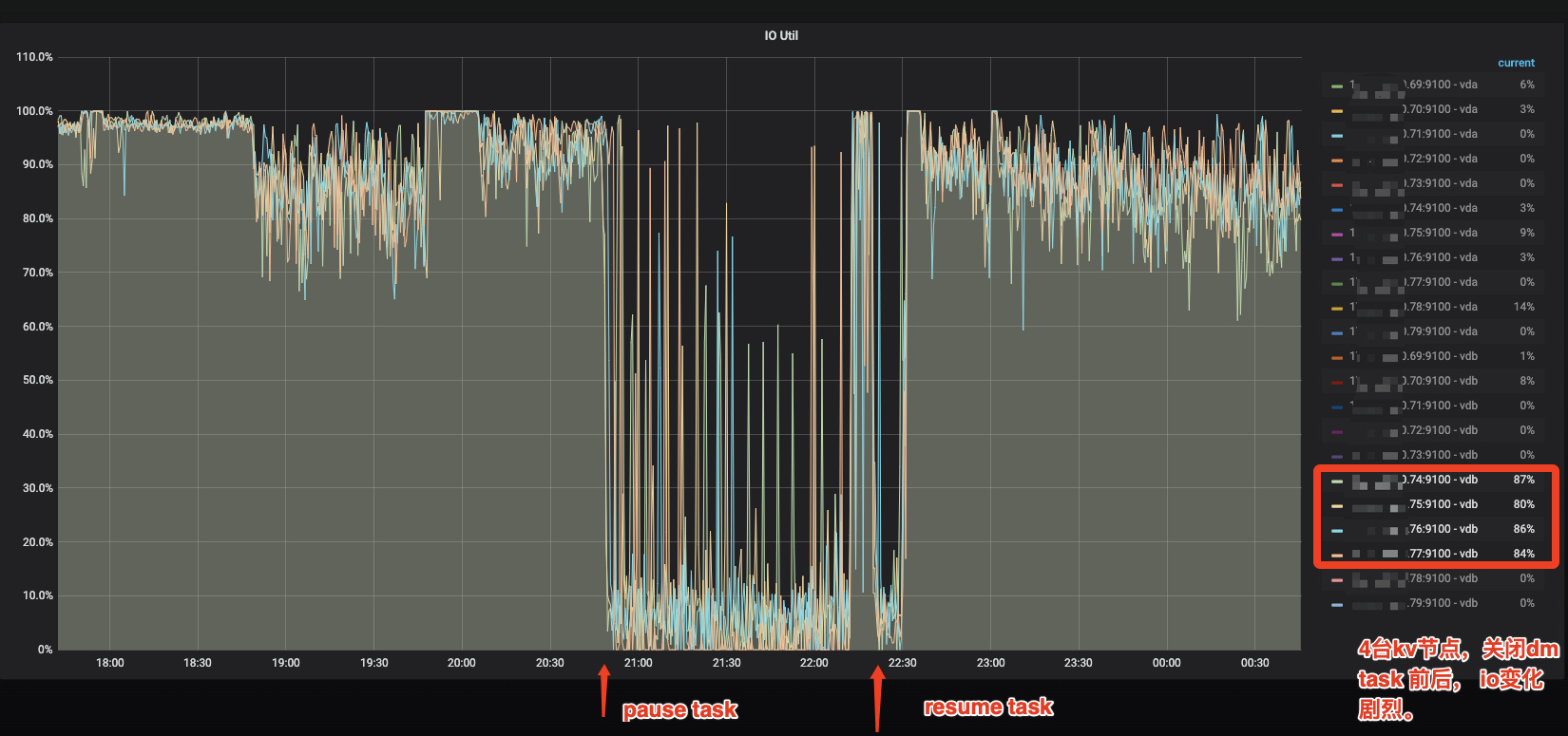
补一幅监控图。
关闭dm task前后变化。按道理,我们的写入速度 比老集群要低,但这里会到100%。对比老集群只有 20~40%
gzp1
(g)
27
确定一致。
jbd2 进程 在集群停止数据写入的时候,是正常的。
yilong
(yi888long)
28
如果都没有写入,jdb2有可能也会降低。 你可以测试安装mysql或者其他业务来压测,看看当IO上来的时候,jdb2会升高吗?
johnwa-CD
(Hacker Yp Yw Bvas)
31
请问这个有结论吗?
我们貌似也碰到类似问题,我是 4.0.4
明明写入的东西都不多.但是tikv的io非常高,而且也是这个jdb2涨的飞快
io uitl基本都在 90%
观察disk write 每秒都有 100M+
但是总的磁盘占用就没涨~~~
请检查tikv节点的RAID卡是有电池,是否开启了缓存,机械盘必须要打开缓存。