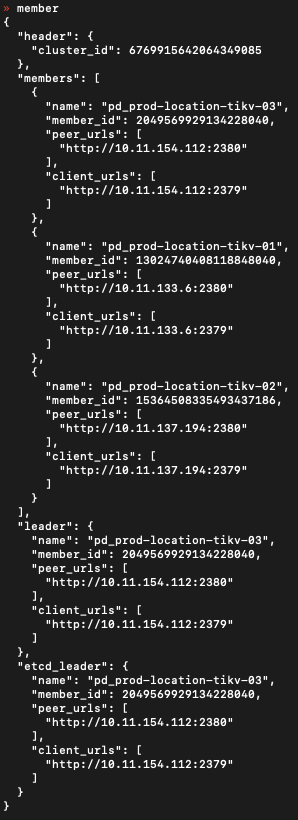
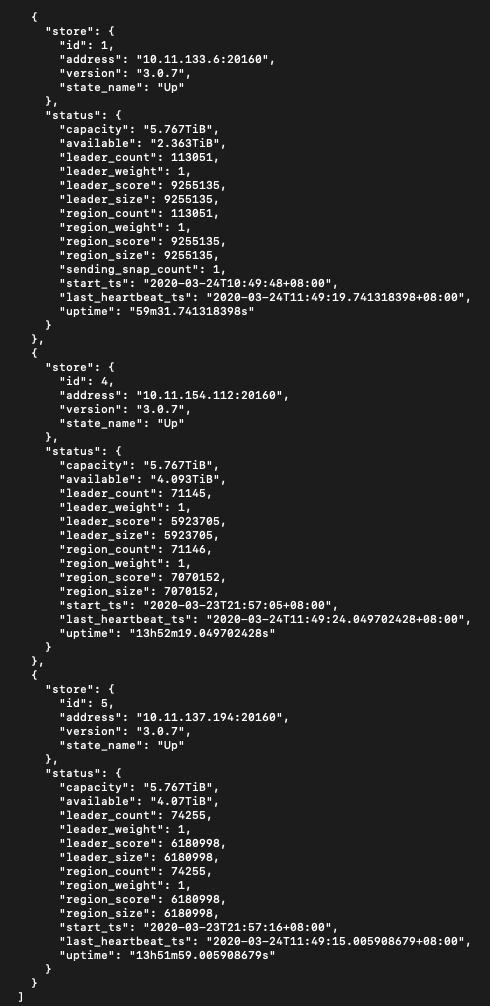
部署结构:目前还在测试接入,部署了 3 node,每台上一个 pd、一个 tikv
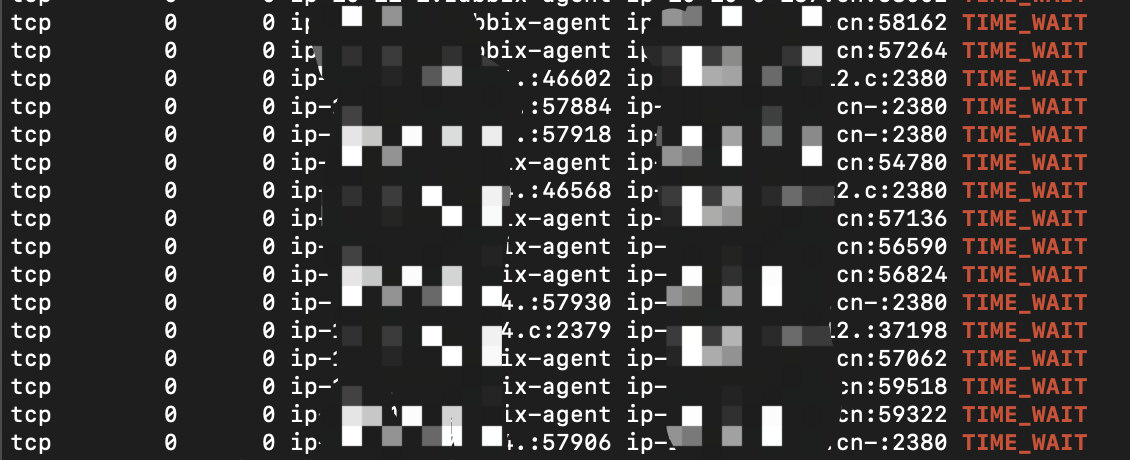
使用 tikv 的 go client,发现 batch put 操作的时候经常连不上 tikv server,请问可能是什么原因?pd 和 tikv 都存活
time=“2020-03-21T13:26:37Z” level=info msg="drop regions that on the store 1(xxx) due to send request fail, err: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp xxx connect: connection refused
写入超时指的是我们用 tikv go client,执行 batch put 操作,一直报错,报错的节点就是经常 oom 的节点 :
time=“2020-03-23T07:39:24Z” level=info msg=“drop regions that on the store 1(xxx:20160) due to send request fail, err: rpc error: code = DeadlineExceeded desc = context deadline exceeded”
time=“2020-03-23T10:12:19Z” level=info msg=“drop regions that on the store 1(xxx:20160) due to send request fail, err: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp xxx:20160: i/o timeout"”
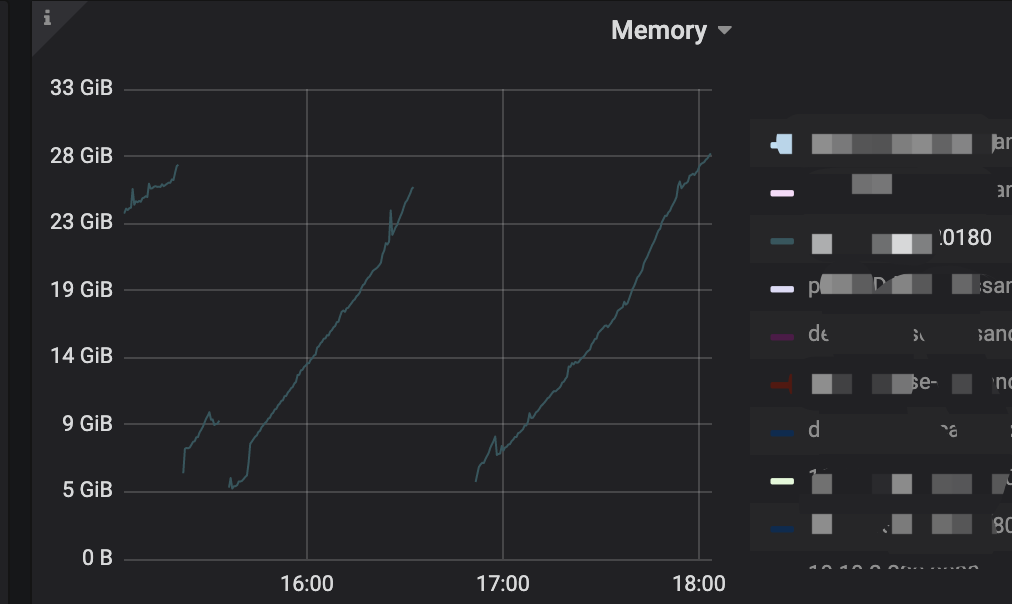
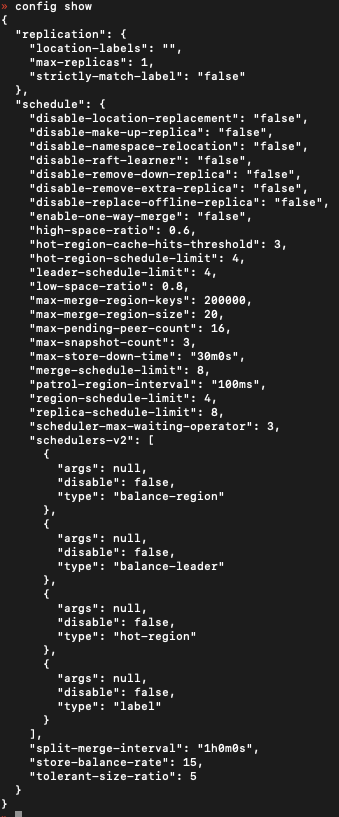
你好,已经配置了 block-cache 16G,该节点 tikv01 还是一个小时 oom 一次。写入是一直超时的,即便整个集群刚重启的时候。请问这是否和配置不平衡有关呢?最开始的时候,tikv01 节点磁盘是更大的,上面的 region 数比其他两个更多,目前写入报错的都是 tikv01 相关的,比如:
INFO[0022] drop regions that on the store 1(xxx:20160) due to send request fail, err: rpc error: code = DeadlineExceeded desc = context deadline exceeded