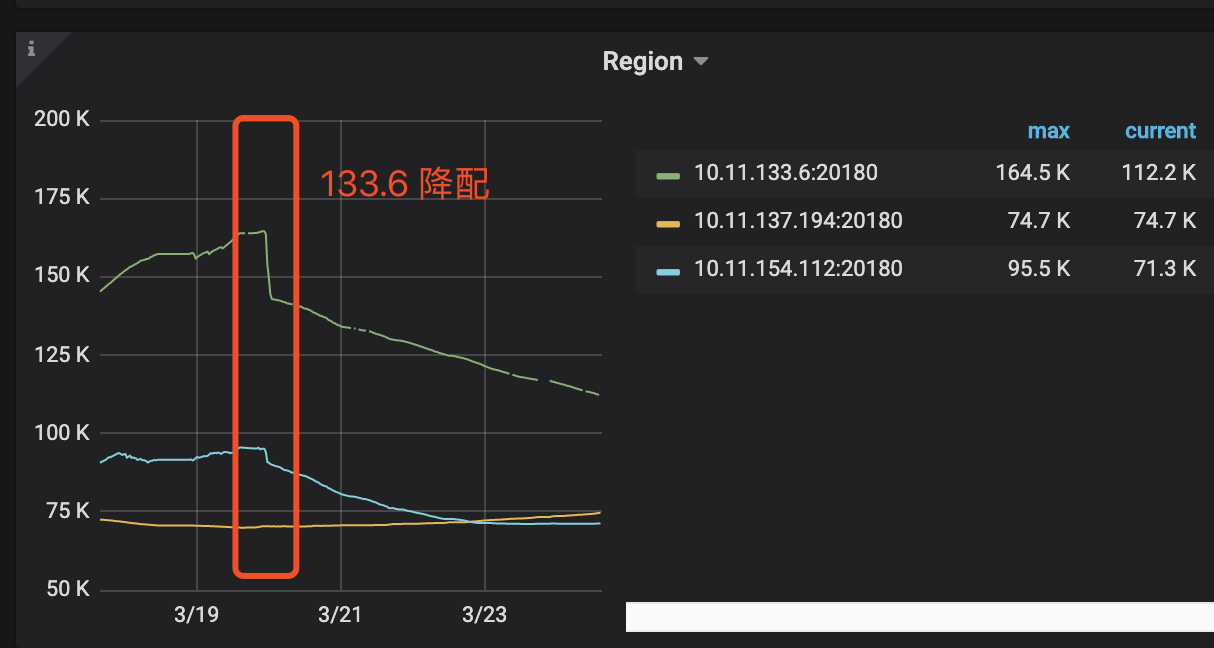
- 是这样的,最开始 store1 的磁盘、cpu 和内存都是更大的,磁盘是 6T, 其他两台都是 3T。后来怀疑是均衡问题,就把 2 和 3 也加到了 6T,store1 的 cpu 和内存降到了和 2,3 一样
- 对,写入请求停止了
- 发现主要是对 store 1 降配后,三个节点的 region 数开始接近,如下:
您好:
1. 如果当前业务写入停止了,没有太高的负载,可以考虑参考文档,加快region balance调度
https://pingcap.com/docs-cn/stable/reference/best-practices/pd-scheduling/#leaderregion-分布不均衡
可以酌情将 leader-schedule-limit 或 region-schedule-limit 调大一些。此外, max-pending-peer-count 以及 max-snapshot-count 限制也可以放宽
使用pd-ctl调整,调整前,记录当前值,加速均衡后,调整回原来的值。
2. 等待均衡后,再观察下是否还会出现OOM的情况
3. 并且根据通常的建议,硬盘不超过2T,如果是6T的盘,建议更高的内存配置。 可以同一个服务器多实例部署.
https://pingcap.com/docs-cn/stable/how-to/deploy/hardware-recommendations/
4. 麻烦将tikv-detail, overview, pd等监控信息反馈,再检查一下,多谢
这是近一周的 details 麻烦看一下 链接: https://pan.baidu.com/s/1Mat_dZX9TDgjNITqbuTlvA 提取码: 9ww7
好的,感谢,会尽快回复
- 参数增大了一倍, region 数在趋向平衡,但目前还没有
- 写入请求停止后,目前没有 oom 了,大量写入超时错误会导致 oom,这个是因为什么资源没释放吗?
- 观察速度增加了就可以
- 从监控看,所有的写入都集中到了那一台机器上,导致压力太大
可以看到大量的raw_batch_put
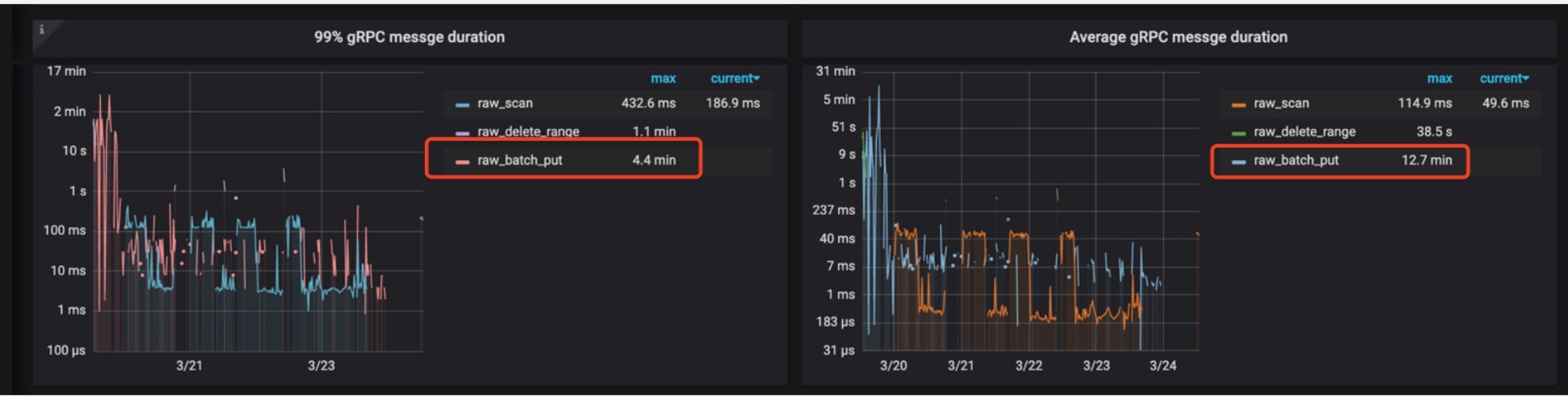
propose wait需要将近30s

write duration也非常高

所以等到均衡后,再写入测试,如果还有OOM问题,那时再发下监控信息,我们确认下是否是当前集群性能不足,需要扩容. 多谢
好的,感谢分析!想问下,虽然写入一直失败,节点 1 压力太大,为什么 raw_scan 基本没问题呢
读写不是一个流程, 可以参考下 TiDB 调优辅助神器 TiDB Performance Map 即将上线!欢迎试用反馈