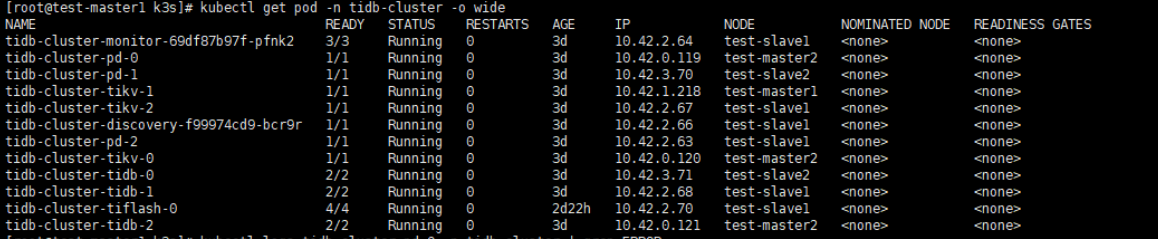
- k8s,helm ,安装版本都是什么?
- 安装命令是什么?
- 当前有没有哪一个集群是安装后不报错的?
1、单集群(一台主机一台master)v1.19.15+k3s2,helm是v3.6.1
2、安装命令,helm install tidb-cluster …
3、另一个多集群(四台主机,两个master,两个node)也是报not leader
这个是我开的另一个帖子
多个集群都出现问题,感觉是环境做了什么调整,其中网络嫌疑最大,在各节点之间除了 ping 之外看看双向端口是否都是连通的。
ping过,都没问题
麻烦也确认下各组件之间的端口连通性
端口没问题的,试过了,pod之间都在正常跑着
pd leader 选举有问题通常就是上面几个楼主说的几种原因,具体的可以参考下文档说明:https://docs.pingcap.com/zh/tidb/v5.1/tidb-troubleshooting-map#52-pd-选举问题
如果上面文档里提到的原因核实过都不是,可以考虑重建下 pd 集群,参考下:
https://docs.pingcap.com/zh/tidb-in-kubernetes/dev/pd-recover/#使用-pd-recover-恢复-pd-集群
1 个赞
明显网络问题,待细节排查
今天早上来升级到5.3.0,还是不行,报一样的错

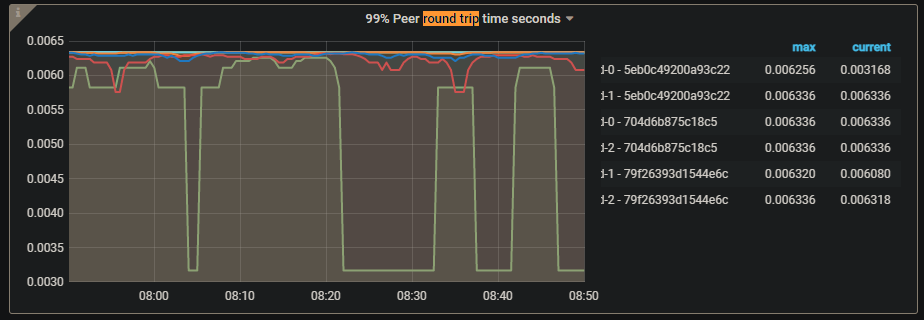
PD日志
0.log (7.0 MB)
tiflash
tiflash-error.log (5.6 MB)
tikv
tikv.log (7.7 MB)
tidb
tidb.log (5.9 MB)
所有日志在这了,烦请大佬看一眼
不是网络不是网络,我换了集群安装也有这个问题![]()
也换了主机吗/
是的,相当于在另一台主机上安装的
我总结一下问题:
1、单集群(一台主机一台master)v1.19.15+k3s2,helm是v3.6.1
2、安装命令,helm install tidb-cluster …
3、另一个多集群(四台主机,两个master,两个node)也是报not leader
4. PD 日志报错 2022-01-17T07:18:34.815541049+08:00 stdout F [2022/01/16 23:18:34.815 +00:00] [ERROR] [middleware.go:104] [“redirect but server is not leader”] [from=tidb-cluster-pd-0] [server=tidb-cluster-pd-1] [error="[PD:apiutil:ErrRedirect]redirect failed"] , 但是业务不影响使用。
是希望查看报错原因,麻烦帮忙确认下,对吗?
另外,在 github issue 找到一个类似问题,https://github.com/tikv/pd/issues/4573 但是看起来 PD 状态时 down。
能否麻烦您也反馈下当前 pd-ctl memeber 和 store 状态信息,多谢。
pd-ctl memeber 是可以看到主是哪个,选主正常的。store是监控里边的吗
https://github.com/tikv/pd/issues/4573
这个我看到过,说是pd down掉了,但是查看pod是正常状态,也可以进pod里边执行命令